



Daniel van Strien
@danielvanstrien.bsky.social
Machine Learning Librarian at @hf.co
Very much looking forward to presenting at this tomorrow. I will be making my usual pitch that datasets are the foundational infrastructure for cultural heritage to benefit from and create useful AI models and tools.
Be warned, I did fire up the meme generator for my slides...
Be warned, I did fire up the meme generator for my slides...

November 5, 2025 at 5:40 PM
Very much looking forward to presenting at this tomorrow. I will be making my usual pitch that datasets are the foundational infrastructure for cultural heritage to benefit from and create useful AI models and tools.
Be warned, I did fire up the meme generator for my slides...
Be warned, I did fire up the meme generator for my slides...
Reposted by Daniel van Strien

Over the last 24 hours, I have finetuned three Qwen3-VL models (2B, 4B, and 8B) on the CATmuS dataset on @hf.co . The first version of the models are now available on the Small Models for GLAM organization with @danielvanstrien.bsky.social (Links below) Working on improving them further.
October 24, 2025 at 2:59 PM
Over the last 24 hours, I have finetuned three Qwen3-VL models (2B, 4B, and 8B) on the CATmuS dataset on @hf.co . The first version of the models are now available on the Small Models for GLAM organization with @danielvanstrien.bsky.social (Links below) Working on improving them further.
DeepSeek-OCR just got vLLM support 🚀
Currently processing @natlibscot.bsky.social's 27,915-page handbook collection with one command.
Processing at ~350 images/sec on A100
Using @hf.co Jobs + uv - zero setup batch OCR!
Will share final time + cost when done!
Currently processing @natlibscot.bsky.social's 27,915-page handbook collection with one command.
Processing at ~350 images/sec on A100
Using @hf.co Jobs + uv - zero setup batch OCR!
Will share final time + cost when done!

October 22, 2025 at 7:20 PM
DeepSeek-OCR just got vLLM support 🚀
Currently processing @natlibscot.bsky.social's 27,915-page handbook collection with one command.
Processing at ~350 images/sec on A100
Using @hf.co Jobs + uv - zero setup batch OCR!
Will share final time + cost when done!
Currently processing @natlibscot.bsky.social's 27,915-page handbook collection with one command.
Processing at ~350 images/sec on A100
Using @hf.co Jobs + uv - zero setup batch OCR!
Will share final time + cost when done!
Reposted by Daniel van Strien

🤗 Sentence Transformers is joining @hf.co! 🤗
This formalizes the existing maintenance structure, as I've personally led the project for the past two years on behalf of Hugging Face. I'm super excited about the transfer!
Details in 🧵
This formalizes the existing maintenance structure, as I've personally led the project for the past two years on behalf of Hugging Face. I'm super excited about the transfer!
Details in 🧵

October 22, 2025 at 1:04 PM
🤗 Sentence Transformers is joining @hf.co! 🤗
This formalizes the existing maintenance structure, as I've personally led the project for the past two years on behalf of Hugging Face. I'm super excited about the transfer!
Details in 🧵
This formalizes the existing maintenance structure, as I've personally led the project for the past two years on behalf of Hugging Face. I'm super excited about the transfer!
Details in 🧵
OCR is one of AI's oldest challenges (first systems: early 1900s!)
Modern vision-language models have transformed what's possible: handwriting, 100+ languages, math formulas, tables, signature extraction...
New @hf.co guide on OCR
huggingface.co/blog/ocr-ope...
Modern vision-language models have transformed what's possible: handwriting, 100+ languages, math formulas, tables, signature extraction...
New @hf.co guide on OCR
huggingface.co/blog/ocr-ope...

Supercharge your OCR Pipelines with Open Models
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
October 22, 2025 at 8:58 AM
OCR is one of AI's oldest challenges (first systems: early 1900s!)
Modern vision-language models have transformed what's possible: handwriting, 100+ languages, math formulas, tables, signature extraction...
New @hf.co guide on OCR
huggingface.co/blog/ocr-ope...
Modern vision-language models have transformed what's possible: handwriting, 100+ languages, math formulas, tables, signature extraction...
New @hf.co guide on OCR
huggingface.co/blog/ocr-ope...
Reposted by Daniel van Strien
Small models work great for GLAM but there aren't enough examples!
With @wjbmattingly.bsky.social I'm launching small-models-for-glam on @hf.co to create/curate models that run on modest hardware and address GLAM use cases.
Follow the org to keep up-to-date!
huggingface.co/small-models...
With @wjbmattingly.bsky.social I'm launching small-models-for-glam on @hf.co to create/curate models that run on modest hardware and address GLAM use cases.
Follow the org to keep up-to-date!
huggingface.co/small-models...
October 16, 2025 at 1:22 PM
Small models work great for GLAM but there aren't enough examples!
With @wjbmattingly.bsky.social I'm launching small-models-for-glam on @hf.co to create/curate models that run on modest hardware and address GLAM use cases.
Follow the org to keep up-to-date!
huggingface.co/small-models...
With @wjbmattingly.bsky.social I'm launching small-models-for-glam on @hf.co to create/curate models that run on modest hardware and address GLAM use cases.
Follow the org to keep up-to-date!
huggingface.co/small-models...
Small models work great for GLAM but there aren't enough examples!
With @wjbmattingly.bsky.social I'm launching small-models-for-glam on @hf.co to create/curate models that run on modest hardware and address GLAM use cases.
Follow the org to keep up-to-date!
huggingface.co/small-models...
With @wjbmattingly.bsky.social I'm launching small-models-for-glam on @hf.co to create/curate models that run on modest hardware and address GLAM use cases.
Follow the org to keep up-to-date!
huggingface.co/small-models...
October 16, 2025 at 1:22 PM
Small models work great for GLAM but there aren't enough examples!
With @wjbmattingly.bsky.social I'm launching small-models-for-glam on @hf.co to create/curate models that run on modest hardware and address GLAM use cases.
Follow the org to keep up-to-date!
huggingface.co/small-models...
With @wjbmattingly.bsky.social I'm launching small-models-for-glam on @hf.co to create/curate models that run on modest hardware and address GLAM use cases.
Follow the org to keep up-to-date!
huggingface.co/small-models...
Very nice work! IMO, this is the kind of topic that more libraries/GLAM/DH people should be working on. The training of these models is *relatively* simple. As always, the missing ingredient is readily accessible data.
It's been brewing for months: @inriaparisnlp.bsky.social releases CoMMA (Corpus of Multilingual Medieval Archives) !
📚 2.5bn tokens of mostly Latin and French texts
🕰️ 800→1600 CE
📜 23k manuscripts
🖥️ 18k on the reading interface: comma.inria.fr
🔍 Paper: inria.hal.science/hal-05299220v1
(1/🧵)
📚 2.5bn tokens of mostly Latin and French texts
🕰️ 800→1600 CE
📜 23k manuscripts
🖥️ 18k on the reading interface: comma.inria.fr
🔍 Paper: inria.hal.science/hal-05299220v1
(1/🧵)
CoMMA
comma.inria.fr
October 15, 2025 at 3:55 PM
Very nice work! IMO, this is the kind of topic that more libraries/GLAM/DH people should be working on. The training of these models is *relatively* simple. As always, the missing ingredient is readily accessible data.
Reposted by Daniel van Strien

It's been brewing for months: @inriaparisnlp.bsky.social releases CoMMA (Corpus of Multilingual Medieval Archives) !
📚 2.5bn tokens of mostly Latin and French texts
🕰️ 800→1600 CE
📜 23k manuscripts
🖥️ 18k on the reading interface: comma.inria.fr
🔍 Paper: inria.hal.science/hal-05299220v1
(1/🧵)
📚 2.5bn tokens of mostly Latin and French texts
🕰️ 800→1600 CE
📜 23k manuscripts
🖥️ 18k on the reading interface: comma.inria.fr
🔍 Paper: inria.hal.science/hal-05299220v1
(1/🧵)
CoMMA
comma.inria.fr
October 15, 2025 at 2:51 PM
It's been brewing for months: @inriaparisnlp.bsky.social releases CoMMA (Corpus of Multilingual Medieval Archives) !
📚 2.5bn tokens of mostly Latin and French texts
🕰️ 800→1600 CE
📜 23k manuscripts
🖥️ 18k on the reading interface: comma.inria.fr
🔍 Paper: inria.hal.science/hal-05299220v1
(1/🧵)
📚 2.5bn tokens of mostly Latin and French texts
🕰️ 800→1600 CE
📜 23k manuscripts
🖥️ 18k on the reading interface: comma.inria.fr
🔍 Paper: inria.hal.science/hal-05299220v1
(1/🧵)
Reposted by Daniel van Strien
Another week, another VLM-based OCR model!
Nanonets just released OCR2 - a 3B parameter vision-language model for document OCR 📄
You can run it with one command on @hf.co Jobs (no local GPU needed)
Nanonets just released OCR2 - a 3B parameter vision-language model for document OCR 📄
You can run it with one command on @hf.co Jobs (no local GPU needed)

October 13, 2025 at 6:13 PM
Another week, another VLM-based OCR model!
Nanonets just released OCR2 - a 3B parameter vision-language model for document OCR 📄
You can run it with one command on @hf.co Jobs (no local GPU needed)
Nanonets just released OCR2 - a 3B parameter vision-language model for document OCR 📄
You can run it with one command on @hf.co Jobs (no local GPU needed)
Another week, another VLM-based OCR model!
Nanonets just released OCR2 - a 3B parameter vision-language model for document OCR 📄
You can run it with one command on @hf.co Jobs (no local GPU needed)
Nanonets just released OCR2 - a 3B parameter vision-language model for document OCR 📄
You can run it with one command on @hf.co Jobs (no local GPU needed)
October 13, 2025 at 6:13 PM
Another week, another VLM-based OCR model!
Nanonets just released OCR2 - a 3B parameter vision-language model for document OCR 📄
You can run it with one command on @hf.co Jobs (no local GPU needed)
Nanonets just released OCR2 - a 3B parameter vision-language model for document OCR 📄
You can run it with one command on @hf.co Jobs (no local GPU needed)
Reposted by Daniel van Strien
DoTS.ocr just got native vLLM support!
I built a UV script so you can run SOTA multilingual OCR in seconds with zero setup using @hf.co Jobs
Tested on 1800s library cards - works great ✨
I built a UV script so you can run SOTA multilingual OCR in seconds with zero setup using @hf.co Jobs
Tested on 1800s library cards - works great ✨


October 7, 2025 at 3:45 PM
DoTS.ocr just got native vLLM support!
I built a UV script so you can run SOTA multilingual OCR in seconds with zero setup using @hf.co Jobs
Tested on 1800s library cards - works great ✨
I built a UV script so you can run SOTA multilingual OCR in seconds with zero setup using @hf.co Jobs
Tested on 1800s library cards - works great ✨
DoTS.ocr just got native vLLM support!
I built a UV script so you can run SOTA multilingual OCR in seconds with zero setup using @hf.co Jobs
Tested on 1800s library cards - works great ✨
I built a UV script so you can run SOTA multilingual OCR in seconds with zero setup using @hf.co Jobs
Tested on 1800s library cards - works great ✨
October 7, 2025 at 3:45 PM
DoTS.ocr just got native vLLM support!
I built a UV script so you can run SOTA multilingual OCR in seconds with zero setup using @hf.co Jobs
Tested on 1800s library cards - works great ✨
I built a UV script so you can run SOTA multilingual OCR in seconds with zero setup using @hf.co Jobs
Tested on 1800s library cards - works great ✨
Card catalogues aren't just a relic of the past - many institutions still rely on them because full migration is too expensive. VLMs could help change that.
I uploaded two new @hf.co datasets (~470K cards) for training/evaluating models to extract structured metadata from catalogue cards.
I uploaded two new @hf.co datasets (~470K cards) for training/evaluating models to extract structured metadata from catalogue cards.

October 6, 2025 at 9:30 AM
Card catalogues aren't just a relic of the past - many institutions still rely on them because full migration is too expensive. VLMs could help change that.
I uploaded two new @hf.co datasets (~470K cards) for training/evaluating models to extract structured metadata from catalogue cards.
I uploaded two new @hf.co datasets (~470K cards) for training/evaluating models to extract structured metadata from catalogue cards.
Reposted by Daniel van Strien

We’re hiring for two machine learning roles. A chance to do cutting edge things with ML to make this place a lot more personalized.
jobs.gem.com/bluesky/am9i...
jobs.gem.com/bluesky/am9i...

Bluesky Jobs
Bluesky Jobs
jobs.gem.com
October 1, 2025 at 1:14 AM
We’re hiring for two machine learning roles. A chance to do cutting edge things with ML to make this place a lot more personalized.
jobs.gem.com/bluesky/am9i...
jobs.gem.com/bluesky/am9i...
New @hf.co BigLAM dataset: 9,363 OA books with page images + rich MARC metadata for evaluating (and training) VLMs on metadata extraction.
Libraries are starting to explore AI-assisted cataloguing, but we lack public evaluation data. Hoping this helps fill that gap.
huggingface.co/datasets/big...
Libraries are starting to explore AI-assisted cataloguing, but we lack public evaluation data. Hoping this helps fill that gap.
huggingface.co/datasets/big...
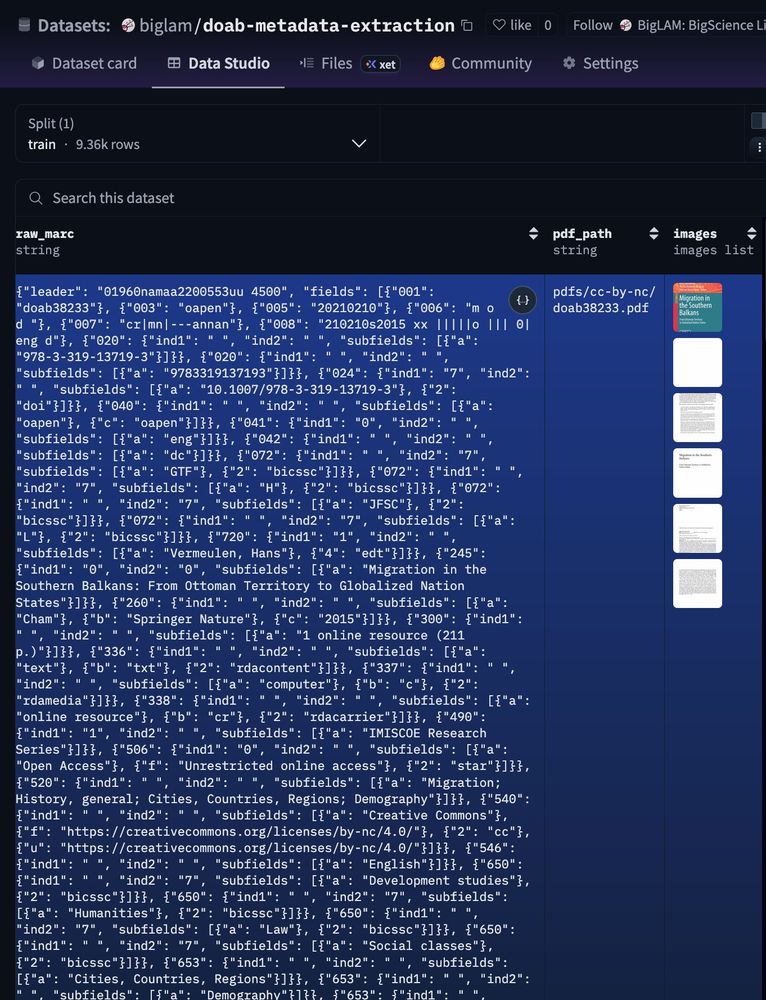
October 2, 2025 at 6:51 PM
New @hf.co BigLAM dataset: 9,363 OA books with page images + rich MARC metadata for evaluating (and training) VLMs on metadata extraction.
Libraries are starting to explore AI-assisted cataloguing, but we lack public evaluation data. Hoping this helps fill that gap.
huggingface.co/datasets/big...
Libraries are starting to explore AI-assisted cataloguing, but we lack public evaluation data. Hoping this helps fill that gap.
huggingface.co/datasets/big...
Reposted by Daniel van Strien
Blogged: Fine-tuning a VLM for art history in hours, not weeks
iconclass-vlm generates museum catalog codes (fun fact: "71H7131" = "Bathsheba with David's letter"!)
@hf.co TRL + Jobs = magic ✨
Guide here: danielvanstrien.xyz/posts/2025/i...
iconclass-vlm generates museum catalog codes (fun fact: "71H7131" = "Bathsheba with David's letter"!)
@hf.co TRL + Jobs = magic ✨
Guide here: danielvanstrien.xyz/posts/2025/i...
danielvanstrien.xyz
September 4, 2025 at 8:19 PM
Blogged: Fine-tuning a VLM for art history in hours, not weeks
iconclass-vlm generates museum catalog codes (fun fact: "71H7131" = "Bathsheba with David's letter"!)
@hf.co TRL + Jobs = magic ✨
Guide here: danielvanstrien.xyz/posts/2025/i...
iconclass-vlm generates museum catalog codes (fun fact: "71H7131" = "Bathsheba with David's letter"!)
@hf.co TRL + Jobs = magic ✨
Guide here: danielvanstrien.xyz/posts/2025/i...
Blogged: Fine-tuning a VLM for art history in hours, not weeks
iconclass-vlm generates museum catalog codes (fun fact: "71H7131" = "Bathsheba with David's letter"!)
@hf.co TRL + Jobs = magic ✨
Guide here: danielvanstrien.xyz/posts/2025/i...
iconclass-vlm generates museum catalog codes (fun fact: "71H7131" = "Bathsheba with David's letter"!)
@hf.co TRL + Jobs = magic ✨
Guide here: danielvanstrien.xyz/posts/2025/i...
danielvanstrien.xyz
September 4, 2025 at 8:19 PM
Blogged: Fine-tuning a VLM for art history in hours, not weeks
iconclass-vlm generates museum catalog codes (fun fact: "71H7131" = "Bathsheba with David's letter"!)
@hf.co TRL + Jobs = magic ✨
Guide here: danielvanstrien.xyz/posts/2025/i...
iconclass-vlm generates museum catalog codes (fun fact: "71H7131" = "Bathsheba with David's letter"!)
@hf.co TRL + Jobs = magic ✨
Guide here: danielvanstrien.xyz/posts/2025/i...
I fine-tuned a smol VLM to generate specialized art history metadata!
iconclass-vlm: Qwen2.5-VL-3B trained using SFT to generate ICONCLASS codes (think Dewey Decimal for art!)
Trained with @hf.co TRL + Jobs - single UV script, no GPU needed!
Blog soon!
iconclass-vlm: Qwen2.5-VL-3B trained using SFT to generate ICONCLASS codes (think Dewey Decimal for art!)
Trained with @hf.co TRL + Jobs - single UV script, no GPU needed!
Blog soon!

September 3, 2025 at 6:22 PM
I fine-tuned a smol VLM to generate specialized art history metadata!
iconclass-vlm: Qwen2.5-VL-3B trained using SFT to generate ICONCLASS codes (think Dewey Decimal for art!)
Trained with @hf.co TRL + Jobs - single UV script, no GPU needed!
Blog soon!
iconclass-vlm: Qwen2.5-VL-3B trained using SFT to generate ICONCLASS codes (think Dewey Decimal for art!)
Trained with @hf.co TRL + Jobs - single UV script, no GPU needed!
Blog soon!
What if OCR models could show you their thought process?
NuMarkdown-8B-Thinking from NuMind (YC S22) doesn't just extract text - it reasons through documents first.
Could be pretty valuable for weird historical documents?
Example here: davanstrien-ocr-time-capsule.static.hf.space/index.html?d...
NuMarkdown-8B-Thinking from NuMind (YC S22) doesn't just extract text - it reasons through documents first.
Could be pretty valuable for weird historical documents?
Example here: davanstrien-ocr-time-capsule.static.hf.space/index.html?d...
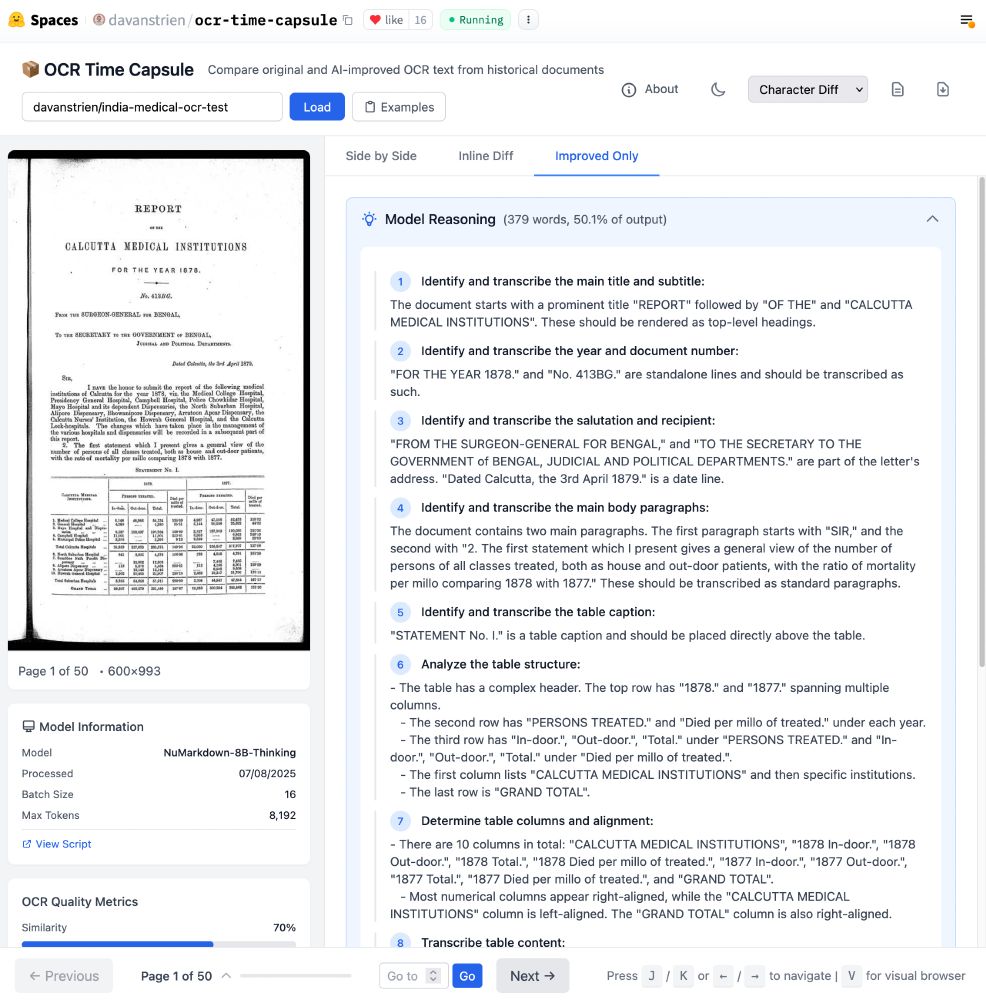
August 7, 2025 at 3:16 PM
What if OCR models could show you their thought process?
NuMarkdown-8B-Thinking from NuMind (YC S22) doesn't just extract text - it reasons through documents first.
Could be pretty valuable for weird historical documents?
Example here: davanstrien-ocr-time-capsule.static.hf.space/index.html?d...
NuMarkdown-8B-Thinking from NuMind (YC S22) doesn't just extract text - it reasons through documents first.
Could be pretty valuable for weird historical documents?
Example here: davanstrien-ocr-time-capsule.static.hf.space/index.html?d...
You can now generate synthetic data using OpenAIs GPT OSS models on @hf.co Jobs!
One command, no setup:
hf jobs uv run --flavor l4x4 [script-url] \
--input-dataset your/dataset \
--output-dataset your/output
Works on L4 GPUs ⚡
huggingface.co/datasets/uv-...
One command, no setup:
hf jobs uv run --flavor l4x4 [script-url] \
--input-dataset your/dataset \
--output-dataset your/output
Works on L4 GPUs ⚡
huggingface.co/datasets/uv-...

uv-scripts/openai-oss · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
August 6, 2025 at 7:38 AM
You can now generate synthetic data using OpenAIs GPT OSS models on @hf.co Jobs!
One command, no setup:
hf jobs uv run --flavor l4x4 [script-url] \
--input-dataset your/dataset \
--output-dataset your/output
Works on L4 GPUs ⚡
huggingface.co/datasets/uv-...
One command, no setup:
hf jobs uv run --flavor l4x4 [script-url] \
--input-dataset your/dataset \
--output-dataset your/output
Works on L4 GPUs ⚡
huggingface.co/datasets/uv-...
Reposted by Daniel van Strien

My latest post on @carpentries.carpentries.org blog is a call to action for the community to engage in curriculum development for workshops about genAI. How can we help our target audience make more informed choices about when and how to use it?
carpentries.org/blog/2025/08...
carpentries.org/blog/2025/08...

AI Carpentry? Helping learners make better choices with genAI.
In two recent community discussion sessions, we explored what mental model of machine learning/deep learning we could teach to learners already familiar with the basics of programming, to help them sa...
carpentries.org
August 5, 2025 at 9:24 AM
My latest post on @carpentries.carpentries.org blog is a call to action for the community to engage in curriculum development for workshops about genAI. How can we help our target audience make more informed choices about when and how to use it?
carpentries.org/blog/2025/08...
carpentries.org/blog/2025/08...
I’m continuing my experiments with VLM-based OCR…
How well do these models handle Victorian theatre playbills from @bldigischol.bsky.social?
RolmOCR vs traditional OCR on tricky playbills (ornate fonts, faded ink, DRAMATIC ALL CAPS!)
@hf.co Demo: huggingface.co/spaces/davan...
How well do these models handle Victorian theatre playbills from @bldigischol.bsky.social?
RolmOCR vs traditional OCR on tricky playbills (ornate fonts, faded ink, DRAMATIC ALL CAPS!)
@hf.co Demo: huggingface.co/spaces/davan...
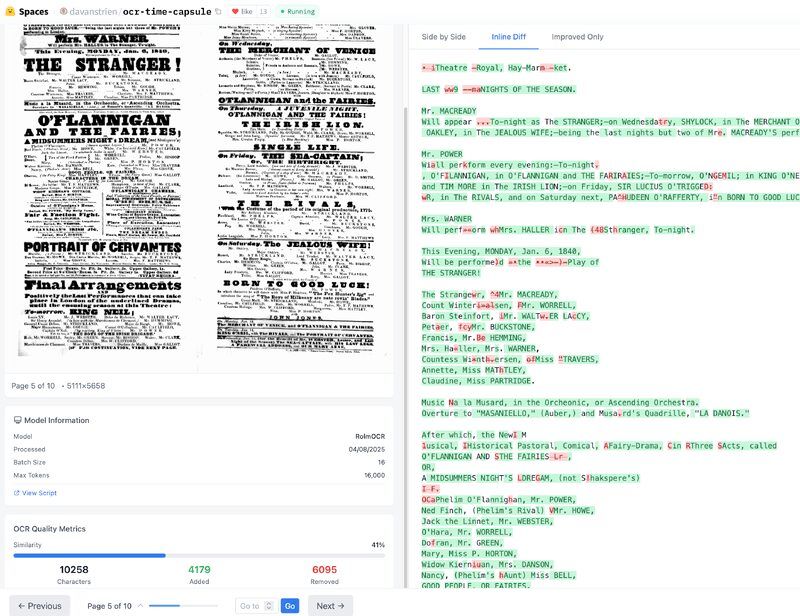
August 5, 2025 at 9:17 AM
I’m continuing my experiments with VLM-based OCR…
How well do these models handle Victorian theatre playbills from @bldigischol.bsky.social?
RolmOCR vs traditional OCR on tricky playbills (ornate fonts, faded ink, DRAMATIC ALL CAPS!)
@hf.co Demo: huggingface.co/spaces/davan...
How well do these models handle Victorian theatre playbills from @bldigischol.bsky.social?
RolmOCR vs traditional OCR on tricky playbills (ornate fonts, faded ink, DRAMATIC ALL CAPS!)
@hf.co Demo: huggingface.co/spaces/davan...
Reposted by Daniel van Strien
Many VLM-based OCR models have been released recently. Are they useful for libraries and archives?
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
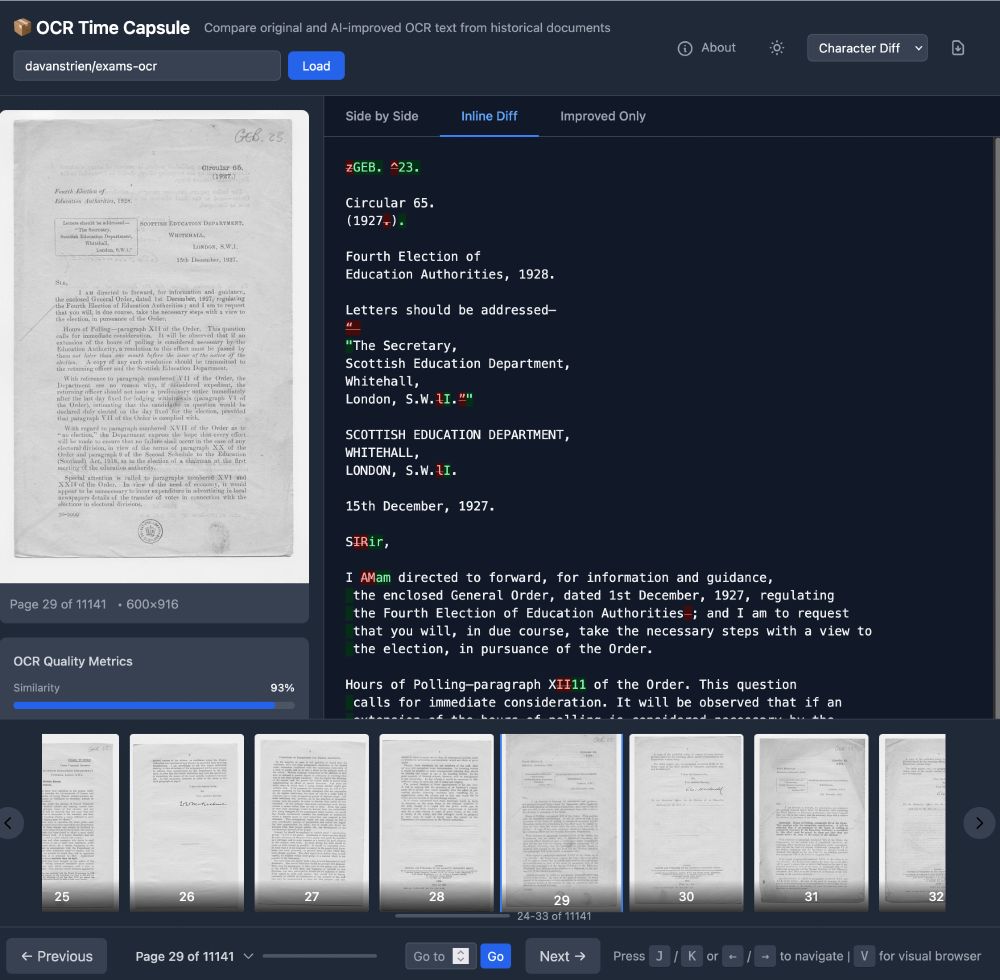
August 1, 2025 at 3:09 PM
Many VLM-based OCR models have been released recently. Are they useful for libraries and archives?
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
Many VLM-based OCR models have been released recently. Are they useful for libraries and archives?
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
August 1, 2025 at 3:09 PM
Many VLM-based OCR models have been released recently. Are they useful for libraries and archives?
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule