



Daniel van Strien
@danielvanstrien.bsky.social
Machine Learning Librarian at @hf.co
Very much looking forward to presenting at this tomorrow. I will be making my usual pitch that datasets are the foundational infrastructure for cultural heritage to benefit from and create useful AI models and tools.
Be warned, I did fire up the meme generator for my slides...
Be warned, I did fire up the meme generator for my slides...

November 5, 2025 at 5:40 PM
Very much looking forward to presenting at this tomorrow. I will be making my usual pitch that datasets are the foundational infrastructure for cultural heritage to benefit from and create useful AI models and tools.
Be warned, I did fire up the meme generator for my slides...
Be warned, I did fire up the meme generator for my slides...
huggingface.co/nanonets/Nan... might be worth a try for this. Can extract formulas into LaTeX

October 23, 2025 at 2:01 PM
huggingface.co/nanonets/Nan... might be worth a try for this. Can extract formulas into LaTeX
The command (using @hf.co Jobs - serverless GPU compute)
Full script at huggingface.co/datasets/uv-...
Full script at huggingface.co/datasets/uv-...

October 22, 2025 at 7:20 PM
The command (using @hf.co Jobs - serverless GPU compute)
Full script at huggingface.co/datasets/uv-...
Full script at huggingface.co/datasets/uv-...
DeepSeek-OCR just got vLLM support 🚀
Currently processing @natlibscot.bsky.social's 27,915-page handbook collection with one command.
Processing at ~350 images/sec on A100
Using @hf.co Jobs + uv - zero setup batch OCR!
Will share final time + cost when done!
Currently processing @natlibscot.bsky.social's 27,915-page handbook collection with one command.
Processing at ~350 images/sec on A100
Using @hf.co Jobs + uv - zero setup batch OCR!
Will share final time + cost when done!

October 22, 2025 at 7:20 PM
DeepSeek-OCR just got vLLM support 🚀
Currently processing @natlibscot.bsky.social's 27,915-page handbook collection with one command.
Processing at ~350 images/sec on A100
Using @hf.co Jobs + uv - zero setup batch OCR!
Will share final time + cost when done!
Currently processing @natlibscot.bsky.social's 27,915-page handbook collection with one command.
Processing at ~350 images/sec on A100
Using @hf.co Jobs + uv - zero setup batch OCR!
Will share final time + cost when done!
Small models work great for GLAM but there aren't enough examples!
With @wjbmattingly.bsky.social I'm launching small-models-for-glam on @hf.co to create/curate models that run on modest hardware and address GLAM use cases.
Follow the org to keep up-to-date!
huggingface.co/small-models...
With @wjbmattingly.bsky.social I'm launching small-models-for-glam on @hf.co to create/curate models that run on modest hardware and address GLAM use cases.
Follow the org to keep up-to-date!
huggingface.co/small-models...
October 16, 2025 at 1:22 PM
Small models work great for GLAM but there aren't enough examples!
With @wjbmattingly.bsky.social I'm launching small-models-for-glam on @hf.co to create/curate models that run on modest hardware and address GLAM use cases.
Follow the org to keep up-to-date!
huggingface.co/small-models...
With @wjbmattingly.bsky.social I'm launching small-models-for-glam on @hf.co to create/curate models that run on modest hardware and address GLAM use cases.
Follow the org to keep up-to-date!
huggingface.co/small-models...
Another week, another VLM-based OCR model!
Nanonets just released OCR2 - a 3B parameter vision-language model for document OCR 📄
You can run it with one command on @hf.co Jobs (no local GPU needed)
Nanonets just released OCR2 - a 3B parameter vision-language model for document OCR 📄
You can run it with one command on @hf.co Jobs (no local GPU needed)

October 13, 2025 at 6:13 PM
Another week, another VLM-based OCR model!
Nanonets just released OCR2 - a 3B parameter vision-language model for document OCR 📄
You can run it with one command on @hf.co Jobs (no local GPU needed)
Nanonets just released OCR2 - a 3B parameter vision-language model for document OCR 📄
You can run it with one command on @hf.co Jobs (no local GPU needed)
DoTS.ocr just got native vLLM support!
I built a UV script so you can run SOTA multilingual OCR in seconds with zero setup using @hf.co Jobs
Tested on 1800s library cards - works great ✨
I built a UV script so you can run SOTA multilingual OCR in seconds with zero setup using @hf.co Jobs
Tested on 1800s library cards - works great ✨


October 7, 2025 at 3:45 PM
DoTS.ocr just got native vLLM support!
I built a UV script so you can run SOTA multilingual OCR in seconds with zero setup using @hf.co Jobs
Tested on 1800s library cards - works great ✨
I built a UV script so you can run SOTA multilingual OCR in seconds with zero setup using @hf.co Jobs
Tested on 1800s library cards - works great ✨
Card catalogues aren't just a relic of the past - many institutions still rely on them because full migration is too expensive. VLMs could help change that.
I uploaded two new @hf.co datasets (~470K cards) for training/evaluating models to extract structured metadata from catalogue cards.
I uploaded two new @hf.co datasets (~470K cards) for training/evaluating models to extract structured metadata from catalogue cards.

October 6, 2025 at 9:30 AM
Card catalogues aren't just a relic of the past - many institutions still rely on them because full migration is too expensive. VLMs could help change that.
I uploaded two new @hf.co datasets (~470K cards) for training/evaluating models to extract structured metadata from catalogue cards.
I uploaded two new @hf.co datasets (~470K cards) for training/evaluating models to extract structured metadata from catalogue cards.
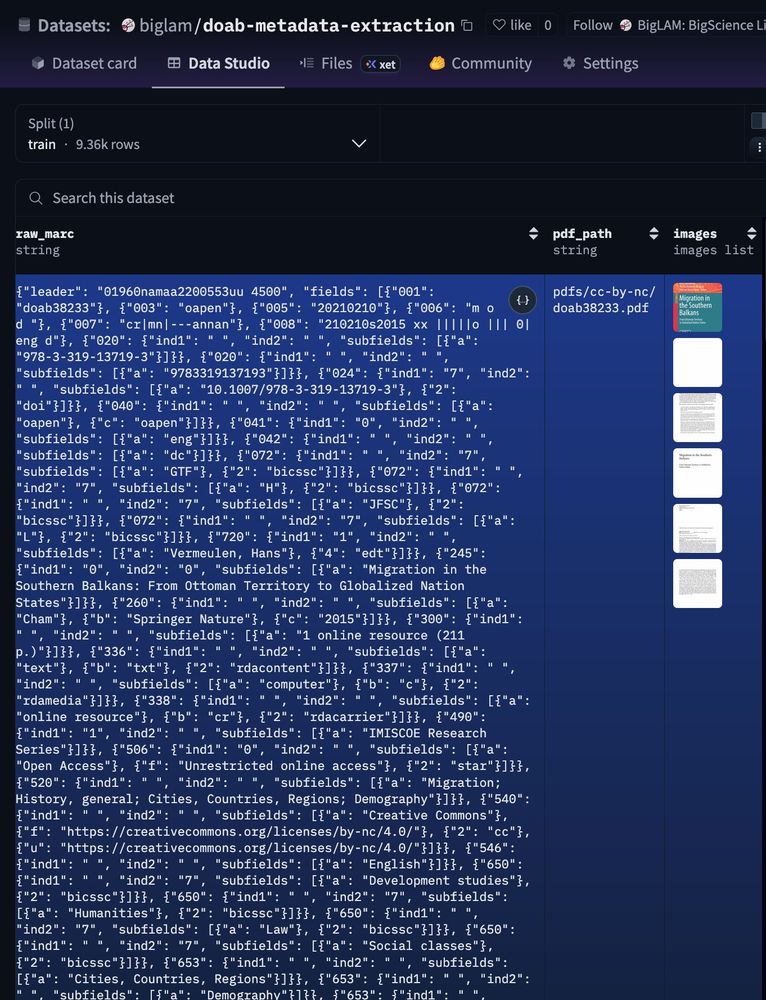
New @hf.co BigLAM dataset: 9,363 OA books with page images + rich MARC metadata for evaluating (and training) VLMs on metadata extraction.
Libraries are starting to explore AI-assisted cataloguing, but we lack public evaluation data. Hoping this helps fill that gap.
huggingface.co/datasets/big...
Libraries are starting to explore AI-assisted cataloguing, but we lack public evaluation data. Hoping this helps fill that gap.
huggingface.co/datasets/big...
October 2, 2025 at 6:51 PM
New @hf.co BigLAM dataset: 9,363 OA books with page images + rich MARC metadata for evaluating (and training) VLMs on metadata extraction.
Libraries are starting to explore AI-assisted cataloguing, but we lack public evaluation data. Hoping this helps fill that gap.
huggingface.co/datasets/big...
Libraries are starting to explore AI-assisted cataloguing, but we lack public evaluation data. Hoping this helps fill that gap.
huggingface.co/datasets/big...
I fine-tuned a smol VLM to generate specialized art history metadata!
iconclass-vlm: Qwen2.5-VL-3B trained using SFT to generate ICONCLASS codes (think Dewey Decimal for art!)
Trained with @hf.co TRL + Jobs - single UV script, no GPU needed!
Blog soon!
iconclass-vlm: Qwen2.5-VL-3B trained using SFT to generate ICONCLASS codes (think Dewey Decimal for art!)
Trained with @hf.co TRL + Jobs - single UV script, no GPU needed!
Blog soon!

September 3, 2025 at 6:22 PM
I fine-tuned a smol VLM to generate specialized art history metadata!
iconclass-vlm: Qwen2.5-VL-3B trained using SFT to generate ICONCLASS codes (think Dewey Decimal for art!)
Trained with @hf.co TRL + Jobs - single UV script, no GPU needed!
Blog soon!
iconclass-vlm: Qwen2.5-VL-3B trained using SFT to generate ICONCLASS codes (think Dewey Decimal for art!)
Trained with @hf.co TRL + Jobs - single UV script, no GPU needed!
Blog soon!
Try it with one line of code via Jobs!
It processes images from any dataset and outputs a new dataset with extracted markdown - all using HF GPUs.
See the full OCR uv scripts collection: huggingface.co/datasets/uv-...
It processes images from any dataset and outputs a new dataset with extracted markdown - all using HF GPUs.
See the full OCR uv scripts collection: huggingface.co/datasets/uv-...
August 7, 2025 at 3:16 PM
Try it with one line of code via Jobs!
It processes images from any dataset and outputs a new dataset with extracted markdown - all using HF GPUs.
See the full OCR uv scripts collection: huggingface.co/datasets/uv-...
It processes images from any dataset and outputs a new dataset with extracted markdown - all using HF GPUs.
See the full OCR uv scripts collection: huggingface.co/datasets/uv-...
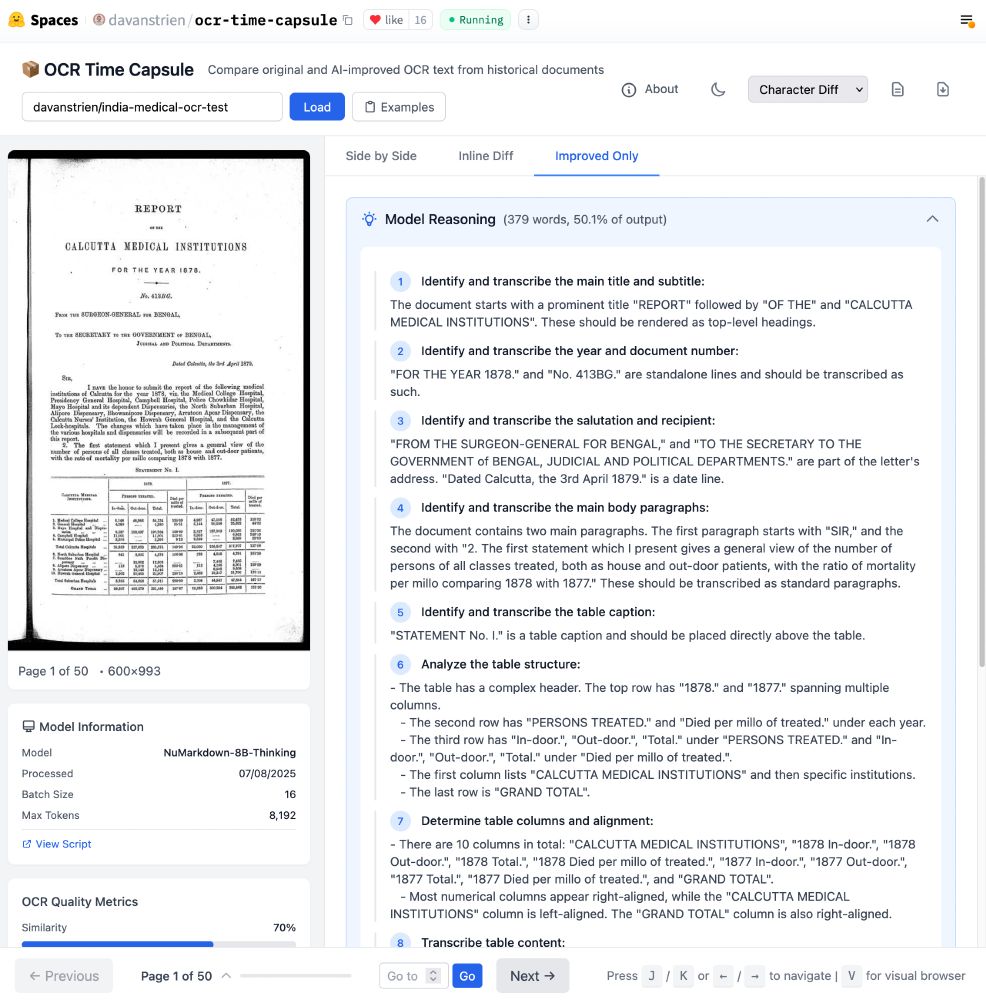
What if OCR models could show you their thought process?
NuMarkdown-8B-Thinking from NuMind (YC S22) doesn't just extract text - it reasons through documents first.
Could be pretty valuable for weird historical documents?
Example here: davanstrien-ocr-time-capsule.static.hf.space/index.html?d...
NuMarkdown-8B-Thinking from NuMind (YC S22) doesn't just extract text - it reasons through documents first.
Could be pretty valuable for weird historical documents?
Example here: davanstrien-ocr-time-capsule.static.hf.space/index.html?d...
August 7, 2025 at 3:16 PM
What if OCR models could show you their thought process?
NuMarkdown-8B-Thinking from NuMind (YC S22) doesn't just extract text - it reasons through documents first.
Could be pretty valuable for weird historical documents?
Example here: davanstrien-ocr-time-capsule.static.hf.space/index.html?d...
NuMarkdown-8B-Thinking from NuMind (YC S22) doesn't just extract text - it reasons through documents first.
Could be pretty valuable for weird historical documents?
Example here: davanstrien-ocr-time-capsule.static.hf.space/index.html?d...
I’m continuing my experiments with VLM-based OCR…
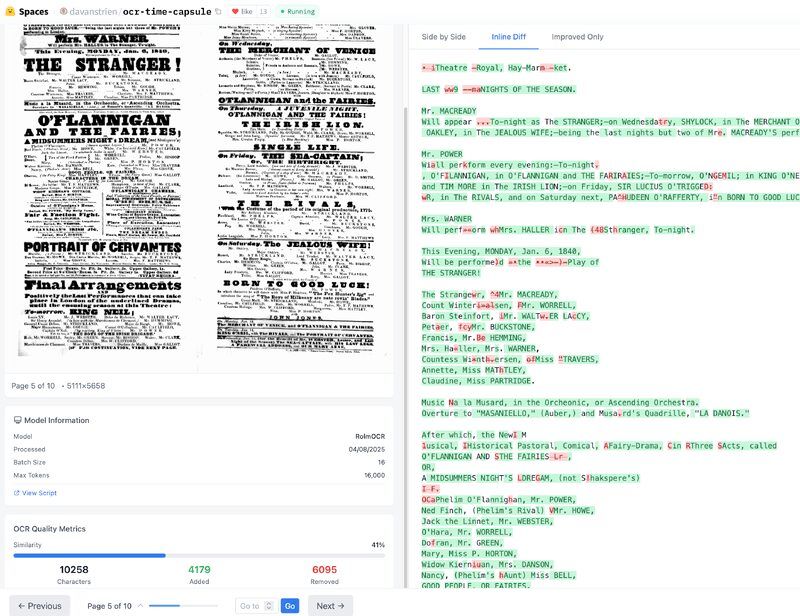
How well do these models handle Victorian theatre playbills from @bldigischol.bsky.social?
RolmOCR vs traditional OCR on tricky playbills (ornate fonts, faded ink, DRAMATIC ALL CAPS!)
@hf.co Demo: huggingface.co/spaces/davan...
How well do these models handle Victorian theatre playbills from @bldigischol.bsky.social?
RolmOCR vs traditional OCR on tricky playbills (ornate fonts, faded ink, DRAMATIC ALL CAPS!)
@hf.co Demo: huggingface.co/spaces/davan...
August 5, 2025 at 9:17 AM
I’m continuing my experiments with VLM-based OCR…
How well do these models handle Victorian theatre playbills from @bldigischol.bsky.social?
RolmOCR vs traditional OCR on tricky playbills (ornate fonts, faded ink, DRAMATIC ALL CAPS!)
@hf.co Demo: huggingface.co/spaces/davan...
How well do these models handle Victorian theatre playbills from @bldigischol.bsky.social?
RolmOCR vs traditional OCR on tricky playbills (ornate fonts, faded ink, DRAMATIC ALL CAPS!)
@hf.co Demo: huggingface.co/spaces/davan...
Many VLM-based OCR models have been released recently. Are they useful for libraries and archives?
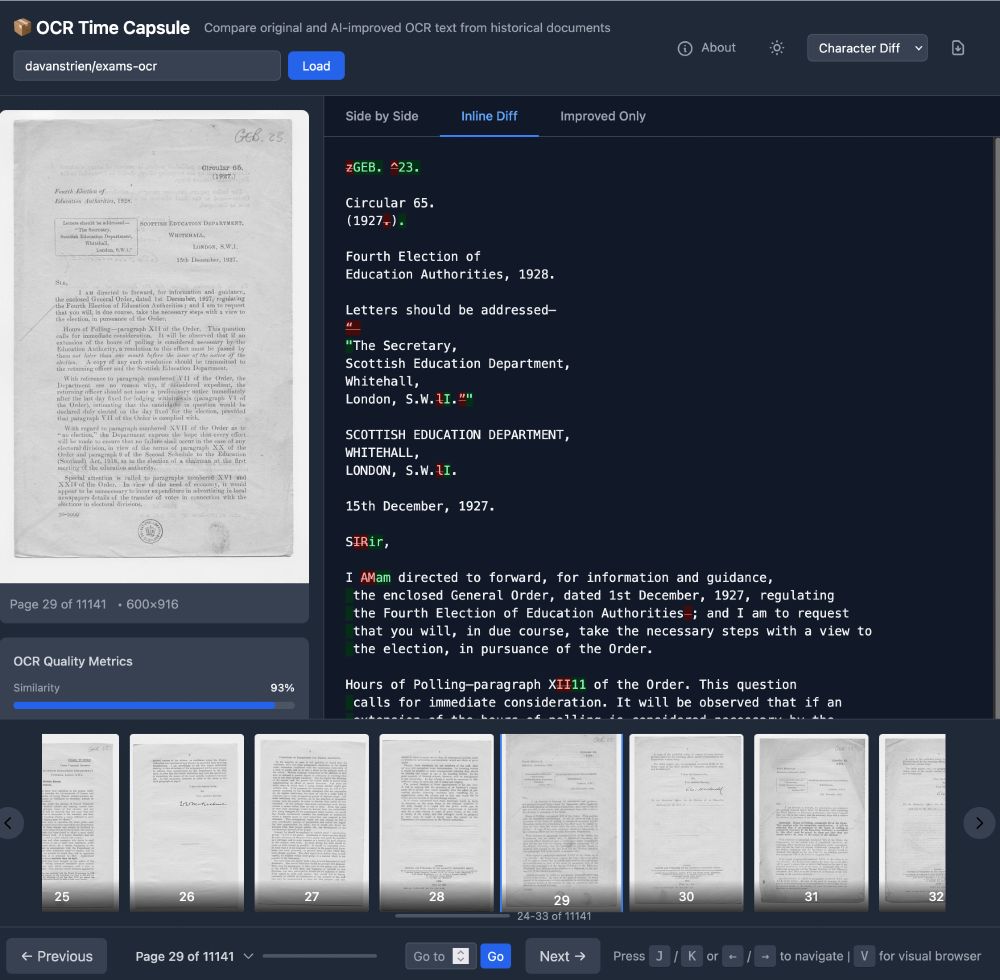
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
August 1, 2025 at 3:09 PM
Many VLM-based OCR models have been released recently. Are they useful for libraries and archives?
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
HF Jobs just launched! 🚀
One command VLM based OCR with uv Scripts:
hf jobs uv run [script] ufo-images ufo-text
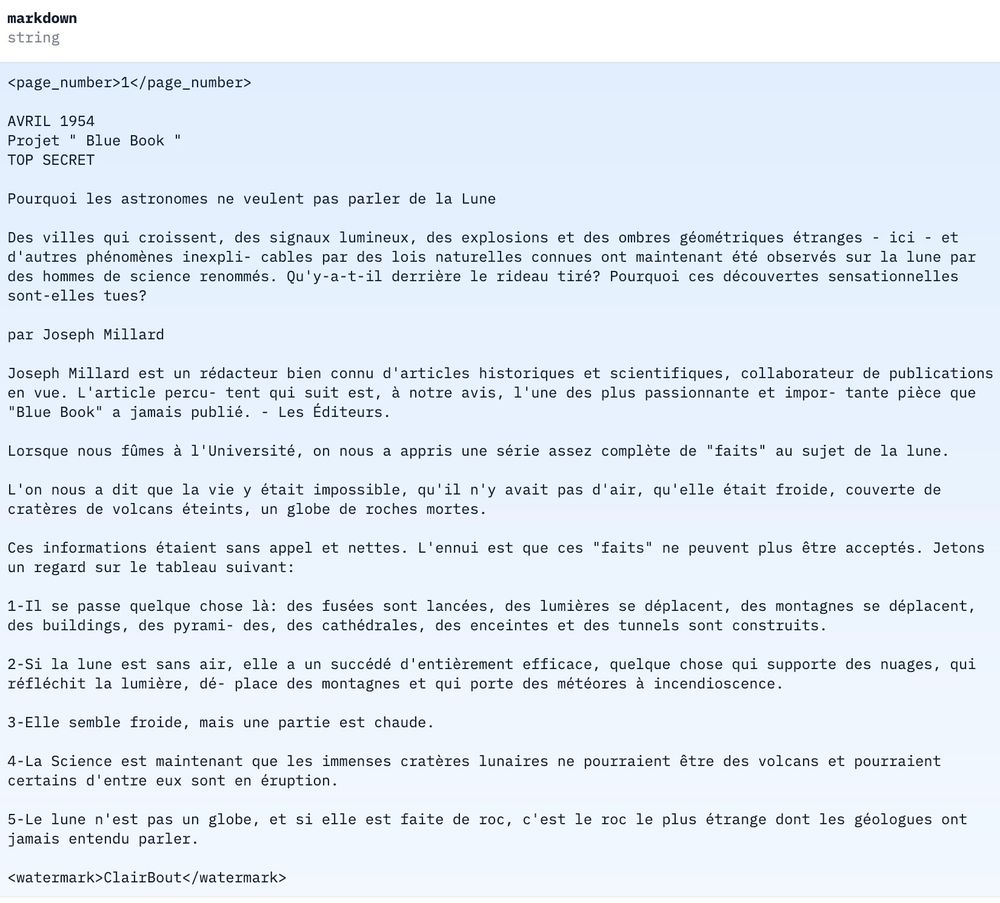
Classified UFO docs → clean markdown. Zero setup!
Try it → huggingface.co/datasets/uv-...
One command VLM based OCR with uv Scripts:
hf jobs uv run [script] ufo-images ufo-text
Classified UFO docs → clean markdown. Zero setup!
Try it → huggingface.co/datasets/uv-...

July 29, 2025 at 8:48 AM
HF Jobs just launched! 🚀
One command VLM based OCR with uv Scripts:
hf jobs uv run [script] ufo-images ufo-text
Classified UFO docs → clean markdown. Zero setup!
Try it → huggingface.co/datasets/uv-...
One command VLM based OCR with uv Scripts:
hf jobs uv run [script] ufo-images ufo-text
Classified UFO docs → clean markdown. Zero setup!
Try it → huggingface.co/datasets/uv-...
465 people. 122 languages. 58,185 annotations!
FineWeb-C v1 is complete! Communities worldwide have built their own educational quality datasets, proving that we don't need to wait for big tech to support languages.
Huge thanks to all who contributed!
huggingface.co/blog/davanst...
FineWeb-C v1 is complete! Communities worldwide have built their own educational quality datasets, proving that we don't need to wait for big tech to support languages.
Huge thanks to all who contributed!
huggingface.co/blog/davanst...
July 8, 2025 at 12:07 PM
465 people. 122 languages. 58,185 annotations!
FineWeb-C v1 is complete! Communities worldwide have built their own educational quality datasets, proving that we don't need to wait for big tech to support languages.
Huge thanks to all who contributed!
huggingface.co/blog/davanst...
FineWeb-C v1 is complete! Communities worldwide have built their own educational quality datasets, proving that we don't need to wait for big tech to support languages.
Huge thanks to all who contributed!
huggingface.co/blog/davanst...
Everyone’s dropping VLM-based OCR models lately…
But are they actually better than traditional OCR engines, which output XML for historical docs?
I built OCR Time Machine to test it!
📄 Upload image + ALTO/PAGE XML
⚖️ Compare outputs side by side
🔗 huggingface.co/spaces/davan...
But are they actually better than traditional OCR engines, which output XML for historical docs?
I built OCR Time Machine to test it!
📄 Upload image + ALTO/PAGE XML
⚖️ Compare outputs side by side
🔗 huggingface.co/spaces/davan...

June 24, 2025 at 5:35 PM
Everyone’s dropping VLM-based OCR models lately…
But are they actually better than traditional OCR engines, which output XML for historical docs?
I built OCR Time Machine to test it!
📄 Upload image + ALTO/PAGE XML
⚖️ Compare outputs side by side
🔗 huggingface.co/spaces/davan...
But are they actually better than traditional OCR engines, which output XML for historical docs?
I built OCR Time Machine to test it!
📄 Upload image + ALTO/PAGE XML
⚖️ Compare outputs side by side
🔗 huggingface.co/spaces/davan...
The @europeana.bsky.social community has launched a “Culture for AI” assembly. It’s asking cultural heritage folks:
how should we critically engage with AI?
Can you guess how I answered the question below?!
how should we critically engage with AI?
Can you guess how I answered the question below?!

June 18, 2025 at 8:09 AM
The @europeana.bsky.social community has launched a “Culture for AI” assembly. It’s asking cultural heritage folks:
how should we critically engage with AI?
Can you guess how I answered the question below?!
how should we critically engage with AI?
Can you guess how I answered the question below?!
“AI Scraping Bots Are Breaking Open Libraries, Archives, and Museums” – interesting piece via @404media.co
Not a perfect fix, but making ML-ready datasets from collections can help.
If you want help getting your data on @hf.co, I'd be happy to help.
Not a perfect fix, but making ML-ready datasets from collections can help.
If you want help getting your data on @hf.co, I'd be happy to help.

June 17, 2025 at 10:43 AM
“AI Scraping Bots Are Breaking Open Libraries, Archives, and Museums” – interesting piece via @404media.co
Not a perfect fix, but making ML-ready datasets from collections can help.
If you want help getting your data on @hf.co, I'd be happy to help.
Not a perfect fix, but making ML-ready datasets from collections can help.
If you want help getting your data on @hf.co, I'd be happy to help.
As usual, I'm allowing myself a few memes for this presentation.
The serious point of this one is that the barrier to doing data work has gotten much lower in the past year or two. You don't need to be an expert in XML to do useful stuff with XML data anymore.
The serious point of this one is that the barrier to doing data work has gotten much lower in the past year or two. You don't need to be an expert in XML to do useful stuff with XML data anymore.

June 16, 2025 at 11:10 AM
As usual, I'm allowing myself a few memes for this presentation.
The serious point of this one is that the barrier to doing data work has gotten much lower in the past year or two. You don't need to be an expert in XML to do useful stuff with XML data anymore.
The serious point of this one is that the barrier to doing data work has gotten much lower in the past year or two. You don't need to be an expert in XML to do useful stuff with XML data anymore.
Did you set the read-only token? huggingface.co/settings/mcp (this is for the official one), for my hacked-together version, you don't need a token!

June 9, 2025 at 2:21 PM
Did you set the read-only token? huggingface.co/settings/mcp (this is for the official one), for my hacked-together version, you don't need a token!
Inspired by @hf.co's official MCP server, I built my own to expose my semantic search API for the HF ecosystem!
Features AI-powered search, parameter analysis via safetensors, and tools to find similar models/datasets.
Try: "Find non maths reasoning datasets from 2025"!
Features AI-powered search, parameter analysis via safetensors, and tools to find similar models/datasets.
Try: "Find non maths reasoning datasets from 2025"!
June 9, 2025 at 11:09 AM
Inspired by @hf.co's official MCP server, I built my own to expose my semantic search API for the HF ecosystem!
Features AI-powered search, parameter analysis via safetensors, and tools to find similar models/datasets.
Try: "Find non maths reasoning datasets from 2025"!
Features AI-powered search, parameter analysis via safetensors, and tools to find similar models/datasets.
Try: "Find non maths reasoning datasets from 2025"!
This is the most exciting part of this DeepSeek release for me.
huggingface.co/deepseek-ai/...
huggingface.co/deepseek-ai/...

May 29, 2025 at 1:41 PM
This is the most exciting part of this DeepSeek release for me.
huggingface.co/deepseek-ai/...
huggingface.co/deepseek-ai/...
🗞️ Just released a Parquet version of the Newspaper Navigator dataset on @hf.co!
- 3M+ visual elements from historic US newspapers — photos, maps, cartoons, OCR + metadata.
- Parquet = fast filters, easier analysis.
- Great for ML + cultural research.
👉 huggingface.co/datasets/big...
- 3M+ visual elements from historic US newspapers — photos, maps, cartoons, OCR + metadata.
- Parquet = fast filters, easier analysis.
- Great for ML + cultural research.
👉 huggingface.co/datasets/big...

May 20, 2025 at 11:50 AM
🗞️ Just released a Parquet version of the Newspaper Navigator dataset on @hf.co!
- 3M+ visual elements from historic US newspapers — photos, maps, cartoons, OCR + metadata.
- Parquet = fast filters, easier analysis.
- Great for ML + cultural research.
👉 huggingface.co/datasets/big...
- 3M+ visual elements from historic US newspapers — photos, maps, cartoons, OCR + metadata.
- Parquet = fast filters, easier analysis.
- Great for ML + cultural research.
👉 huggingface.co/datasets/big...
Finally documented the Beyond Words dataset from the @librarycongress.bsky.social labs / @bcgl.bsky.social for the BigLAM @hf.co org!
- 3.5K annotated historical newspaper pages
- Bounding boxes + category labels
- Photos, ads, headlines, cartoons & more
- 3.5K annotated historical newspaper pages
- Bounding boxes + category labels
- Photos, ads, headlines, cartoons & more

May 8, 2025 at 8:41 AM
Finally documented the Beyond Words dataset from the @librarycongress.bsky.social labs / @bcgl.bsky.social for the BigLAM @hf.co org!
- 3.5K annotated historical newspaper pages
- Bounding boxes + category labels
- Photos, ads, headlines, cartoons & more
- 3.5K annotated historical newspaper pages
- Bounding boxes + category labels
- Photos, ads, headlines, cartoons & more