



Dana Arad
@danaarad.bsky.social
NLP Researcher | CS PhD Candidate @ Technion
Excited to spend the rest of the summer visiting @davidbau.bsky.social's lab at Northeastern! If you’re in the area and want to chat about interpretability, let me know ☕️

August 10, 2025 at 1:56 PM
Excited to spend the rest of the summer visiting @davidbau.bsky.social's lab at Northeastern! If you’re in the area and want to chat about interpretability, let me know ☕️
By simply patching visual data tokens from later layers back into earlier ones, we improve of 4.6% on average - closing a third of the gap!

June 26, 2025 at 10:41 AM
By simply patching visual data tokens from later layers back into earlier ones, we improve of 4.6% on average - closing a third of the gap!
4. Zooming on data positions, we show that visual representations gradually align with their textual analogs across model layers (also shown by
@zhaofeng_wu
et al.). We hypothesize this may happen too late in the model to process the information, and fix it with back-patching.
@zhaofeng_wu
et al.). We hypothesize this may happen too late in the model to process the information, and fix it with back-patching.

June 26, 2025 at 10:41 AM
4. Zooming on data positions, we show that visual representations gradually align with their textual analogs across model layers (also shown by
@zhaofeng_wu
et al.). We hypothesize this may happen too late in the model to process the information, and fix it with back-patching.
@zhaofeng_wu
et al.). We hypothesize this may happen too late in the model to process the information, and fix it with back-patching.
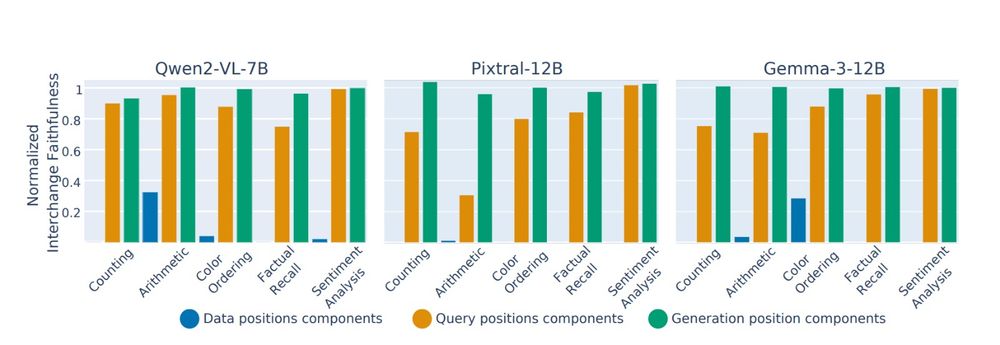
3. Data sub-circuits, however, are modality-specific; Swapping them significantly degrades performance. This is critical - this highlights that the differences in data processing are a key factor in the performance gap.
June 26, 2025 at 10:41 AM
3. Data sub-circuits, however, are modality-specific; Swapping them significantly degrades performance. This is critical - this highlights that the differences in data processing are a key factor in the performance gap.
2. Structure is only half the story: different circuits can still implement similar logic. We swap sub-circuits between modalities to measure cross-modal faithfulness.
Turns out, query and generation sub-circuits are functionally equivalent, retaining faithfulness when swapped!
Turns out, query and generation sub-circuits are functionally equivalent, retaining faithfulness when swapped!

June 26, 2025 at 10:41 AM
2. Structure is only half the story: different circuits can still implement similar logic. We swap sub-circuits between modalities to measure cross-modal faithfulness.
Turns out, query and generation sub-circuits are functionally equivalent, retaining faithfulness when swapped!
Turns out, query and generation sub-circuits are functionally equivalent, retaining faithfulness when swapped!
1. Circuits for the same task are mostly structurally disjoint, with an average of only 18% components shared between modalities!
The overlap is extremely low in data and query positions, and moderate in the generation (last) position only.
The overlap is extremely low in data and query positions, and moderate in the generation (last) position only.

June 26, 2025 at 10:41 AM
1. Circuits for the same task are mostly structurally disjoint, with an average of only 18% components shared between modalities!
The overlap is extremely low in data and query positions, and moderate in the generation (last) position only.
The overlap is extremely low in data and query positions, and moderate in the generation (last) position only.
We identify circuits (task-specific computational sub-graphs composed of attention heads and MLP neurons) used by VLMs to solve both variants.
What did we find? >>
What did we find? >>

June 26, 2025 at 10:41 AM
We identify circuits (task-specific computational sub-graphs composed of attention heads and MLP neurons) used by VLMs to solve both variants.
What did we find? >>
What did we find? >>
Consider object counting: we can ask a VLM “how many books are there?” given either an image or a sequence of words. Like Kaduri et al., we consider three types of positions within the input - data (image or word sequence), query ("how many..."), and generation (last token).

June 26, 2025 at 10:41 AM
Consider object counting: we can ask a VLM “how many books are there?” given either an image or a sequence of words. Like Kaduri et al., we consider three types of positions within the input - data (image or word sequence), query ("how many..."), and generation (last token).
VLMs perform better on questions about text than when answering the same questions about images - but why? and how can we fix it?
In a new project led by Yaniv (@YNikankin on the other app), we investigate this gap from an mechanistic perspective, and use our findings to close a third of it! 🧵
In a new project led by Yaniv (@YNikankin on the other app), we investigate this gap from an mechanistic perspective, and use our findings to close a third of it! 🧵

June 26, 2025 at 10:41 AM
VLMs perform better on questions about text than when answering the same questions about images - but why? and how can we fix it?
In a new project led by Yaniv (@YNikankin on the other app), we investigate this gap from an mechanistic perspective, and use our findings to close a third of it! 🧵
In a new project led by Yaniv (@YNikankin on the other app), we investigate this gap from an mechanistic perspective, and use our findings to close a third of it! 🧵
These findings have practical implications: after filtering out features with low output scores, we see 2-3x improvements for steering with SAEs, making them competitive with supervised methods on AxBench, a recent steering benchmark ( Wu and @aryaman.io et al.)

May 27, 2025 at 4:06 PM
These findings have practical implications: after filtering out features with low output scores, we see 2-3x improvements for steering with SAEs, making them competitive with supervised methods on AxBench, a recent steering benchmark ( Wu and @aryaman.io et al.)
We show that high scores rarely co-occur, and emerge at different layers: features in earlier layers primarily detect input patterns, while features in later layers are more likely to drive the model’s outputs, consistent with prior analyses of LLM neuron functionality.

May 27, 2025 at 4:06 PM
We show that high scores rarely co-occur, and emerge at different layers: features in earlier layers primarily detect input patterns, while features in later layers are more likely to drive the model’s outputs, consistent with prior analyses of LLM neuron functionality.
These differences were previously noted (e.g.,
Durmus et al., see image), but had not been systematically analyzed.
We take an additional step by introducing two simple, efficient metrics to characterize features: the input score and the output score.
Durmus et al., see image), but had not been systematically analyzed.
We take an additional step by introducing two simple, efficient metrics to characterize features: the input score and the output score.

May 27, 2025 at 4:06 PM
These differences were previously noted (e.g.,
Durmus et al., see image), but had not been systematically analyzed.
We take an additional step by introducing two simple, efficient metrics to characterize features: the input score and the output score.
Durmus et al., see image), but had not been systematically analyzed.
We take an additional step by introducing two simple, efficient metrics to characterize features: the input score and the output score.
In this work we characterize two feature roles: Input features, which mainly capture patterns in the model's input, and output features, those with a human-understandable effect on the model's output.
Steering with each yields very different effects!
Steering with each yields very different effects!

May 27, 2025 at 4:06 PM
In this work we characterize two feature roles: Input features, which mainly capture patterns in the model's input, and output features, those with a human-understandable effect on the model's output.
Steering with each yields very different effects!
Steering with each yields very different effects!
Tried steering with SAEs and found that not all features behave as expected?
Check out our new preprint - "SAEs Are Good for Steering - If You Select the Right Features" 🧵
Check out our new preprint - "SAEs Are Good for Steering - If You Select the Right Features" 🧵

May 27, 2025 at 4:06 PM
Tried steering with SAEs and found that not all features behave as expected?
Check out our new preprint - "SAEs Are Good for Steering - If You Select the Right Features" 🧵
Check out our new preprint - "SAEs Are Good for Steering - If You Select the Right Features" 🧵