



Core Francisco Parkg
@corefpark.bsky.social
Thanks for following the thread and big shout out to the team:
Zechen Zhang and @hidenori8tanaka.bsky.social
Here is the preprint:
arxiv.org/abs/2505.01812
14/n
Zechen Zhang and @hidenori8tanaka.bsky.social
Here is the preprint:
arxiv.org/abs/2505.01812
14/n

$\textit{New News}$: System-2 Fine-tuning for Robust Integration of New Knowledge
Humans and intelligent animals can effortlessly internalize new information ("news") and accurately extract the implications for performing downstream tasks. While large language models (LLMs) can ach...
arxiv.org
May 21, 2025 at 12:07 AM
Thanks for following the thread and big shout out to the team:
Zechen Zhang and @hidenori8tanaka.bsky.social
Here is the preprint:
arxiv.org/abs/2505.01812
14/n
Zechen Zhang and @hidenori8tanaka.bsky.social
Here is the preprint:
arxiv.org/abs/2505.01812
14/n
Key Takeaways:
✅ There's a clear FT-ICL gap
✅ Self-QA largely mitigates it
✅ Larger models are more data efficient learners
✅ Contextual shadowing hurts fine-tuning
Please check out the paper (see below) for even more findings!
13/n
✅ There's a clear FT-ICL gap
✅ Self-QA largely mitigates it
✅ Larger models are more data efficient learners
✅ Contextual shadowing hurts fine-tuning
Please check out the paper (see below) for even more findings!
13/n
May 21, 2025 at 12:07 AM
Key Takeaways:
✅ There's a clear FT-ICL gap
✅ Self-QA largely mitigates it
✅ Larger models are more data efficient learners
✅ Contextual shadowing hurts fine-tuning
Please check out the paper (see below) for even more findings!
13/n
✅ There's a clear FT-ICL gap
✅ Self-QA largely mitigates it
✅ Larger models are more data efficient learners
✅ Contextual shadowing hurts fine-tuning
Please check out the paper (see below) for even more findings!
13/n
For humans, this contextualizes the work and helps integration, but this might be hindering learning in LLMs.
We are working on confirming this hypothesis on real data.
12/n
We are working on confirming this hypothesis on real data.
12/n
May 21, 2025 at 12:07 AM
For humans, this contextualizes the work and helps integration, but this might be hindering learning in LLMs.
We are working on confirming this hypothesis on real data.
12/n
We are working on confirming this hypothesis on real data.
12/n
We suspect this effect significantly harms fine-tuning as we know!
Let's take the example of research papers. In a typical research paper, the abstract usually “spoils” the rest of the paper.
11/n
Let's take the example of research papers. In a typical research paper, the abstract usually “spoils” the rest of the paper.
11/n
May 21, 2025 at 12:07 AM
We suspect this effect significantly harms fine-tuning as we know!
Let's take the example of research papers. In a typical research paper, the abstract usually “spoils” the rest of the paper.
11/n
Let's take the example of research papers. In a typical research paper, the abstract usually “spoils” the rest of the paper.
11/n
⚠️⚠️ But here comes drama!!!
What if the news appears in the context upstream of the *same* FT data?
🚨 Contextual Shadowing happens!
Prefixing the news during FT *catastrophically* reduces learning!
10/n
What if the news appears in the context upstream of the *same* FT data?
🚨 Contextual Shadowing happens!
Prefixing the news during FT *catastrophically* reduces learning!
10/n
May 21, 2025 at 12:07 AM
⚠️⚠️ But here comes drama!!!
What if the news appears in the context upstream of the *same* FT data?
🚨 Contextual Shadowing happens!
Prefixing the news during FT *catastrophically* reduces learning!
10/n
What if the news appears in the context upstream of the *same* FT data?
🚨 Contextual Shadowing happens!
Prefixing the news during FT *catastrophically* reduces learning!
10/n
Next, we analyzed Sys2-FT from a scaling law perspective. We found an empirical scaling law of Sys2-FT where the knowledge integration is a function of the compute spent.
Larger models are thus more data efficient learners!
Note that this scaling isn’t evident in loss.
9/n
Larger models are thus more data efficient learners!
Note that this scaling isn’t evident in loss.
9/n

May 21, 2025 at 12:07 AM
Next, we analyzed Sys2-FT from a scaling law perspective. We found an empirical scaling law of Sys2-FT where the knowledge integration is a function of the compute spent.
Larger models are thus more data efficient learners!
Note that this scaling isn’t evident in loss.
9/n
Larger models are thus more data efficient learners!
Note that this scaling isn’t evident in loss.
9/n
Interestingly, Sys2-FT shines most in domains where System-2 inference has seen the most success: Math and Coding.
8/n
8/n

May 21, 2025 at 12:07 AM
Interestingly, Sys2-FT shines most in domains where System-2 inference has seen the most success: Math and Coding.
8/n
8/n
Among these protocols, Self-QA especially stood out, largely mitigating the FT-ICL gap and integrating the given knowledge into the model!
Training on synthetic Q/A pairs really boost knowledge integration!
7/n
Training on synthetic Q/A pairs really boost knowledge integration!
7/n
May 21, 2025 at 12:07 AM
Among these protocols, Self-QA especially stood out, largely mitigating the FT-ICL gap and integrating the given knowledge into the model!
Training on synthetic Q/A pairs really boost knowledge integration!
7/n
Training on synthetic Q/A pairs really boost knowledge integration!
7/n
Inspired by cognitive science on memory consolidation, we introduce System-2 Fine-Tuning (Sys2-FT). Models actively rehearse, paraphrase, and self-play about new facts to create fine-tuning data. We explore three protocols: Paraphrase, Implication, and Self-QA.
6/n
6/n

May 21, 2025 at 12:07 AM
Inspired by cognitive science on memory consolidation, we introduce System-2 Fine-Tuning (Sys2-FT). Models actively rehearse, paraphrase, and self-play about new facts to create fine-tuning data. We explore three protocols: Paraphrase, Implication, and Self-QA.
6/n
6/n
As expected, naïve fine-tuning on the raw facts isn’t enough to integrate knowledge across domains or model sizes up to 32B.
We call this the FT-ICL gap.
5/n
We call this the FT-ICL gap.
5/n
May 21, 2025 at 12:07 AM
As expected, naïve fine-tuning on the raw facts isn’t enough to integrate knowledge across domains or model sizes up to 32B.
We call this the FT-ICL gap.
5/n
We call this the FT-ICL gap.
5/n
But how do we update the model’s weights to bake in this new rule?
To explore this, we built “New News”: 75 new hypothetical (but non-counterfactual) facts across diverse domains, paired with 375 downstream questions.
4/n
To explore this, we built “New News”: 75 new hypothetical (but non-counterfactual) facts across diverse domains, paired with 375 downstream questions.
4/n

May 21, 2025 at 12:07 AM
But how do we update the model’s weights to bake in this new rule?
To explore this, we built “New News”: 75 new hypothetical (but non-counterfactual) facts across diverse domains, paired with 375 downstream questions.
4/n
To explore this, we built “New News”: 75 new hypothetical (but non-counterfactual) facts across diverse domains, paired with 375 downstream questions.
4/n
Today’s LLMs can effectively use *truly* novel information given as a context.
Given:
- Mathematicians defined 'addiplication' as (x+y)*y
Models can answer:
Q: What is the addiplication of 3 and 4?
A: (3+4)*4=28
3/n
Given:
- Mathematicians defined 'addiplication' as (x+y)*y
Models can answer:
Q: What is the addiplication of 3 and 4?
A: (3+4)*4=28
3/n
May 21, 2025 at 12:07 AM
Today’s LLMs can effectively use *truly* novel information given as a context.
Given:
- Mathematicians defined 'addiplication' as (x+y)*y
Models can answer:
Q: What is the addiplication of 3 and 4?
A: (3+4)*4=28
3/n
Given:
- Mathematicians defined 'addiplication' as (x+y)*y
Models can answer:
Q: What is the addiplication of 3 and 4?
A: (3+4)*4=28
3/n
TL;DR: We present “New News,” a dataset for measuring belief updates, and propose Self-QA, a highly effective way to integrate new knowledge via System-2 thinking at training time. We also show that in-context learning can actually hurt fine-tuning.
2/n
2/n
May 21, 2025 at 12:07 AM
TL;DR: We present “New News,” a dataset for measuring belief updates, and propose Self-QA, a highly effective way to integrate new knowledge via System-2 thinking at training time. We also show that in-context learning can actually hurt fine-tuning.
2/n
2/n
January 5, 2025 at 4:02 PM
This project was a true collaborative effort where everyone contributed to major parts of the project!
Big thanks to the team: @ajyl.bsky.social, @ekdeepl.bsky.social, Yongyi Yang, Maya Okawa, Kento Nishi, @wattenberg.bsky.social, @hidenori8tanaka.bsky.social
14/n
Big thanks to the team: @ajyl.bsky.social, @ekdeepl.bsky.social, Yongyi Yang, Maya Okawa, Kento Nishi, @wattenberg.bsky.social, @hidenori8tanaka.bsky.social
14/n
January 5, 2025 at 4:02 PM
This project was a true collaborative effort where everyone contributed to major parts of the project!
Big thanks to the team: @ajyl.bsky.social, @ekdeepl.bsky.social, Yongyi Yang, Maya Okawa, Kento Nishi, @wattenberg.bsky.social, @hidenori8tanaka.bsky.social
14/n
Big thanks to the team: @ajyl.bsky.social, @ekdeepl.bsky.social, Yongyi Yang, Maya Okawa, Kento Nishi, @wattenberg.bsky.social, @hidenori8tanaka.bsky.social
14/n
We further investigate how this critical context size for an in-context transition scales with graph size.
We find a power law relationship between the critical context size and the graph size.
13/n
We find a power law relationship between the critical context size and the graph size.
13/n

January 5, 2025 at 4:02 PM
We further investigate how this critical context size for an in-context transition scales with graph size.
We find a power law relationship between the critical context size and the graph size.
13/n
We find a power law relationship between the critical context size and the graph size.
13/n
We find that LLMs indeed minimize the spectral energy on the graph and the rule-following accuracy sharply rises after the energy hits a minimum!
12/n
12/n

January 5, 2025 at 4:02 PM
We find that LLMs indeed minimize the spectral energy on the graph and the rule-following accuracy sharply rises after the energy hits a minimum!
12/n
12/n
How to explain these results? We hypothesize a model runs an implicit optimization process to adapt to context-specified tasks (akin to in-context GD by @oswaldjoh et al), prompting an analysis of Dirichlet energy between the ground-truth graph & model representation.
11/n
11/n

January 5, 2025 at 4:02 PM
How to explain these results? We hypothesize a model runs an implicit optimization process to adapt to context-specified tasks (akin to in-context GD by @oswaldjoh et al), prompting an analysis of Dirichlet energy between the ground-truth graph & model representation.
11/n
11/n
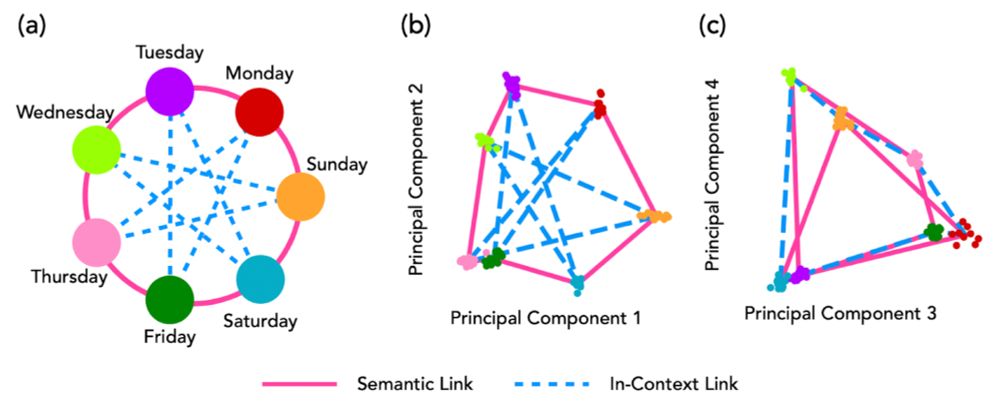
What happens when there is a strong semantic structure acquired during pretraining?
We set up a task where the days of the week should be navigated in an unusual way: Mon -> Thu -> Sun, etc.
Here, we find that in-context representations show up in higher PC dimensions.
10/n
We set up a task where the days of the week should be navigated in an unusual way: Mon -> Thu -> Sun, etc.
Here, we find that in-context representations show up in higher PC dimensions.
10/n
January 5, 2025 at 4:02 PM
What happens when there is a strong semantic structure acquired during pretraining?
We set up a task where the days of the week should be navigated in an unusual way: Mon -> Thu -> Sun, etc.
Here, we find that in-context representations show up in higher PC dimensions.
10/n
We set up a task where the days of the week should be navigated in an unusual way: Mon -> Thu -> Sun, etc.
Here, we find that in-context representations show up in higher PC dimensions.
10/n
We call these context dependent representations “In-Context Representations” and these appear robustly across graph structures and models.
9/n
9/n

January 5, 2025 at 4:02 PM
We call these context dependent representations “In-Context Representations” and these appear robustly across graph structures and models.
9/n
9/n
What about a different structure?
Here, we used a ring graph and sampled random neighbors on the graph.
Again, we find that internal representations re-organizes to match the task structure.
8/n
Here, we used a ring graph and sampled random neighbors on the graph.
Again, we find that internal representations re-organizes to match the task structure.
8/n

January 5, 2025 at 4:02 PM
What about a different structure?
Here, we used a ring graph and sampled random neighbors on the graph.
Again, we find that internal representations re-organizes to match the task structure.
8/n
Here, we used a ring graph and sampled random neighbors on the graph.
Again, we find that internal representations re-organizes to match the task structure.
8/n
Interestingly, a similar phenomenon was observed in humans! One can reconstruct the graph underlying a sequence of random images from fMRI scans of the brain during the task.
elifesciences.org/articles/17086
7/n
elifesciences.org/articles/17086
7/n

January 5, 2025 at 4:02 PM
Interestingly, a similar phenomenon was observed in humans! One can reconstruct the graph underlying a sequence of random images from fMRI scans of the brain during the task.
elifesciences.org/articles/17086
7/n
elifesciences.org/articles/17086
7/n
Surprisingly, when we input this sequence to Llama-3.1-8B, the model’s internal representations show an emergent grid structure matching the task in its first principal components!
6/n
6/n

January 5, 2025 at 4:02 PM
Surprisingly, when we input this sequence to Llama-3.1-8B, the model’s internal representations show an emergent grid structure matching the task in its first principal components!
6/n
6/n