



Core Francisco Parkg
@corefpark.bsky.social
⚠️⚠️ But here comes drama!!!
What if the news appears in the context upstream of the *same* FT data?
🚨 Contextual Shadowing happens!
Prefixing the news during FT *catastrophically* reduces learning!
10/n
What if the news appears in the context upstream of the *same* FT data?
🚨 Contextual Shadowing happens!
Prefixing the news during FT *catastrophically* reduces learning!
10/n
May 21, 2025 at 12:07 AM
⚠️⚠️ But here comes drama!!!
What if the news appears in the context upstream of the *same* FT data?
🚨 Contextual Shadowing happens!
Prefixing the news during FT *catastrophically* reduces learning!
10/n
What if the news appears in the context upstream of the *same* FT data?
🚨 Contextual Shadowing happens!
Prefixing the news during FT *catastrophically* reduces learning!
10/n
Next, we analyzed Sys2-FT from a scaling law perspective. We found an empirical scaling law of Sys2-FT where the knowledge integration is a function of the compute spent.
Larger models are thus more data efficient learners!
Note that this scaling isn’t evident in loss.
9/n
Larger models are thus more data efficient learners!
Note that this scaling isn’t evident in loss.
9/n

May 21, 2025 at 12:07 AM
Next, we analyzed Sys2-FT from a scaling law perspective. We found an empirical scaling law of Sys2-FT where the knowledge integration is a function of the compute spent.
Larger models are thus more data efficient learners!
Note that this scaling isn’t evident in loss.
9/n
Larger models are thus more data efficient learners!
Note that this scaling isn’t evident in loss.
9/n
Interestingly, Sys2-FT shines most in domains where System-2 inference has seen the most success: Math and Coding.
8/n
8/n

May 21, 2025 at 12:07 AM
Interestingly, Sys2-FT shines most in domains where System-2 inference has seen the most success: Math and Coding.
8/n
8/n
Among these protocols, Self-QA especially stood out, largely mitigating the FT-ICL gap and integrating the given knowledge into the model!
Training on synthetic Q/A pairs really boost knowledge integration!
7/n
Training on synthetic Q/A pairs really boost knowledge integration!
7/n
May 21, 2025 at 12:07 AM
Among these protocols, Self-QA especially stood out, largely mitigating the FT-ICL gap and integrating the given knowledge into the model!
Training on synthetic Q/A pairs really boost knowledge integration!
7/n
Training on synthetic Q/A pairs really boost knowledge integration!
7/n
Inspired by cognitive science on memory consolidation, we introduce System-2 Fine-Tuning (Sys2-FT). Models actively rehearse, paraphrase, and self-play about new facts to create fine-tuning data. We explore three protocols: Paraphrase, Implication, and Self-QA.
6/n
6/n

May 21, 2025 at 12:07 AM
Inspired by cognitive science on memory consolidation, we introduce System-2 Fine-Tuning (Sys2-FT). Models actively rehearse, paraphrase, and self-play about new facts to create fine-tuning data. We explore three protocols: Paraphrase, Implication, and Self-QA.
6/n
6/n
As expected, naïve fine-tuning on the raw facts isn’t enough to integrate knowledge across domains or model sizes up to 32B.
We call this the FT-ICL gap.
5/n
We call this the FT-ICL gap.
5/n
May 21, 2025 at 12:07 AM
As expected, naïve fine-tuning on the raw facts isn’t enough to integrate knowledge across domains or model sizes up to 32B.
We call this the FT-ICL gap.
5/n
We call this the FT-ICL gap.
5/n
But how do we update the model’s weights to bake in this new rule?
To explore this, we built “New News”: 75 new hypothetical (but non-counterfactual) facts across diverse domains, paired with 375 downstream questions.
4/n
To explore this, we built “New News”: 75 new hypothetical (but non-counterfactual) facts across diverse domains, paired with 375 downstream questions.
4/n

May 21, 2025 at 12:07 AM
But how do we update the model’s weights to bake in this new rule?
To explore this, we built “New News”: 75 new hypothetical (but non-counterfactual) facts across diverse domains, paired with 375 downstream questions.
4/n
To explore this, we built “New News”: 75 new hypothetical (but non-counterfactual) facts across diverse domains, paired with 375 downstream questions.
4/n
🚨 New Paper!
A lot happens in the world every day—how can we update LLMs with belief-changing news?
We introduce a new dataset "New News" and systematically study knowledge integration via System-2 Fine-Tuning (Sys2-FT).
1/n
A lot happens in the world every day—how can we update LLMs with belief-changing news?
We introduce a new dataset "New News" and systematically study knowledge integration via System-2 Fine-Tuning (Sys2-FT).
1/n

May 21, 2025 at 12:07 AM
🚨 New Paper!
A lot happens in the world every day—how can we update LLMs with belief-changing news?
We introduce a new dataset "New News" and systematically study knowledge integration via System-2 Fine-Tuning (Sys2-FT).
1/n
A lot happens in the world every day—how can we update LLMs with belief-changing news?
We introduce a new dataset "New News" and systematically study knowledge integration via System-2 Fine-Tuning (Sys2-FT).
1/n
We further investigate how this critical context size for an in-context transition scales with graph size.
We find a power law relationship between the critical context size and the graph size.
13/n
We find a power law relationship between the critical context size and the graph size.
13/n

January 5, 2025 at 4:02 PM
We further investigate how this critical context size for an in-context transition scales with graph size.
We find a power law relationship between the critical context size and the graph size.
13/n
We find a power law relationship between the critical context size and the graph size.
13/n
We find that LLMs indeed minimize the spectral energy on the graph and the rule-following accuracy sharply rises after the energy hits a minimum!
12/n
12/n

January 5, 2025 at 4:02 PM
We find that LLMs indeed minimize the spectral energy on the graph and the rule-following accuracy sharply rises after the energy hits a minimum!
12/n
12/n
How to explain these results? We hypothesize a model runs an implicit optimization process to adapt to context-specified tasks (akin to in-context GD by @oswaldjoh et al), prompting an analysis of Dirichlet energy between the ground-truth graph & model representation.
11/n
11/n

January 5, 2025 at 4:02 PM
How to explain these results? We hypothesize a model runs an implicit optimization process to adapt to context-specified tasks (akin to in-context GD by @oswaldjoh et al), prompting an analysis of Dirichlet energy between the ground-truth graph & model representation.
11/n
11/n
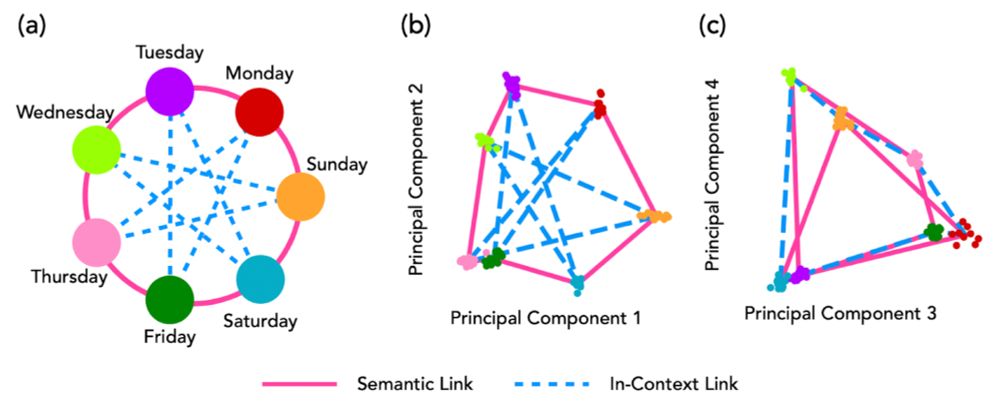
What happens when there is a strong semantic structure acquired during pretraining?
We set up a task where the days of the week should be navigated in an unusual way: Mon -> Thu -> Sun, etc.
Here, we find that in-context representations show up in higher PC dimensions.
10/n
We set up a task where the days of the week should be navigated in an unusual way: Mon -> Thu -> Sun, etc.
Here, we find that in-context representations show up in higher PC dimensions.
10/n
January 5, 2025 at 4:02 PM
What happens when there is a strong semantic structure acquired during pretraining?
We set up a task where the days of the week should be navigated in an unusual way: Mon -> Thu -> Sun, etc.
Here, we find that in-context representations show up in higher PC dimensions.
10/n
We set up a task where the days of the week should be navigated in an unusual way: Mon -> Thu -> Sun, etc.
Here, we find that in-context representations show up in higher PC dimensions.
10/n
We call these context dependent representations “In-Context Representations” and these appear robustly across graph structures and models.
9/n
9/n

January 5, 2025 at 4:02 PM
We call these context dependent representations “In-Context Representations” and these appear robustly across graph structures and models.
9/n
9/n
What about a different structure?
Here, we used a ring graph and sampled random neighbors on the graph.
Again, we find that internal representations re-organizes to match the task structure.
8/n
Here, we used a ring graph and sampled random neighbors on the graph.
Again, we find that internal representations re-organizes to match the task structure.
8/n

January 5, 2025 at 4:02 PM
What about a different structure?
Here, we used a ring graph and sampled random neighbors on the graph.
Again, we find that internal representations re-organizes to match the task structure.
8/n
Here, we used a ring graph and sampled random neighbors on the graph.
Again, we find that internal representations re-organizes to match the task structure.
8/n
Interestingly, a similar phenomenon was observed in humans! One can reconstruct the graph underlying a sequence of random images from fMRI scans of the brain during the task.
elifesciences.org/articles/17086
7/n
elifesciences.org/articles/17086
7/n

January 5, 2025 at 4:02 PM
Interestingly, a similar phenomenon was observed in humans! One can reconstruct the graph underlying a sequence of random images from fMRI scans of the brain during the task.
elifesciences.org/articles/17086
7/n
elifesciences.org/articles/17086
7/n
Surprisingly, when we input this sequence to Llama-3.1-8B, the model’s internal representations show an emergent grid structure matching the task in its first principal components!
6/n
6/n

January 5, 2025 at 4:02 PM
Surprisingly, when we input this sequence to Llama-3.1-8B, the model’s internal representations show an emergent grid structure matching the task in its first principal components!
6/n
6/n
But do LLM representations also reflect the structure of a task given purely in context?
To explore this question, we set up a synthetic task where we put words on a grid and perform a random walk. The random walk outputs the words it accessed as a sequence.
5/n
To explore this question, we set up a synthetic task where we put words on a grid and perform a random walk. The random walk outputs the words it accessed as a sequence.
5/n

January 5, 2025 at 4:02 PM
But do LLM representations also reflect the structure of a task given purely in context?
To explore this question, we set up a synthetic task where we put words on a grid and perform a random walk. The random walk outputs the words it accessed as a sequence.
5/n
To explore this question, we set up a synthetic task where we put words on a grid and perform a random walk. The random walk outputs the words it accessed as a sequence.
5/n
We know that LLM representations reflect the structure of the real world’s data generating process. For example, @JoshAEngels showed that the days of the weeks are represented as a ring in the residual stream.
x.com/JoshAEngels/...
4/n
x.com/JoshAEngels/...
4/n

January 5, 2025 at 4:02 PM
We know that LLM representations reflect the structure of the real world’s data generating process. For example, @JoshAEngels showed that the days of the weeks are represented as a ring in the residual stream.
x.com/JoshAEngels/...
4/n
x.com/JoshAEngels/...
4/n
New paper! “In-Context Learning of Representations”
What happens to an LLM’s internal representations in the large context limit?
We find that LLMs form “in-context representations” to match the structure of the task given in context!
What happens to an LLM’s internal representations in the large context limit?
We find that LLMs form “in-context representations” to match the structure of the task given in context!
January 5, 2025 at 4:02 PM
New paper! “In-Context Learning of Representations”
What happens to an LLM’s internal representations in the large context limit?
We find that LLMs form “in-context representations” to match the structure of the task given in context!
What happens to an LLM’s internal representations in the large context limit?
We find that LLMs form “in-context representations” to match the structure of the task given in context!