



Clamchowder
@chlamchowder.bsky.social
Gamer who analyzes tech too much
Software engineer at Microsoft, opinions here are my own
Software engineer at Microsoft, opinions here are my own
Looking good on Intel too, improving measured latency by ~6.8 ns, or 19-20 cycles



October 28, 2025 at 1:16 AM
Looking good on Intel too, improving measured latency by ~6.8 ns, or 19-20 cycles
So far I used a simple a=a[a] pattern to test GPU memory latency, but that indexed addressing penalty always bothered me. I finally got around to making the compiler spit out a chain of dependent loads and nothing else.
Good start on AMD. I save ~4 or ~12 ns for scalar and vector accesses
Good start on AMD. I save ~4 or ~12 ns for scalar and vector accesses


October 28, 2025 at 12:51 AM
So far I used a simple a=a[a] pattern to test GPU memory latency, but that indexed addressing penalty always bothered me. I finally got around to making the compiler spit out a chain of dependent loads and nothing else.
Good start on AMD. I save ~4 or ~12 ns for scalar and vector accesses
Good start on AMD. I save ~4 or ~12 ns for scalar and vector accesses
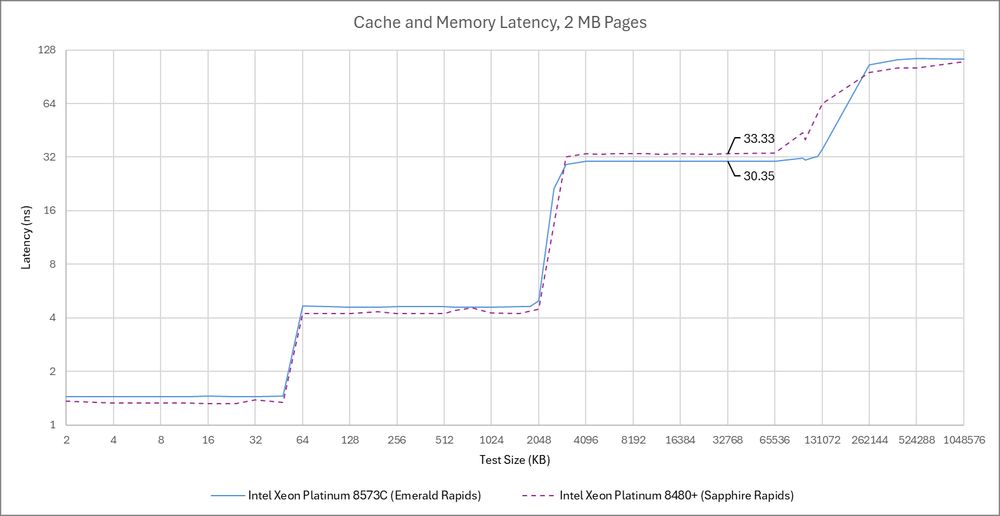
Intel's newer Emerald Rapids improves L3 latency compared to Sapphire Rapids, at least when one core is able to allocate a similar amount of L3 capacity. It's still high at ~105 core cycles, but better than ~125 cycles from the last generation.
July 11, 2025 at 10:36 PM
Intel's newer Emerald Rapids improves L3 latency compared to Sapphire Rapids, at least when one core is able to allocate a similar amount of L3 capacity. It's still high at ~105 core cycles, but better than ~125 cycles from the last generation.
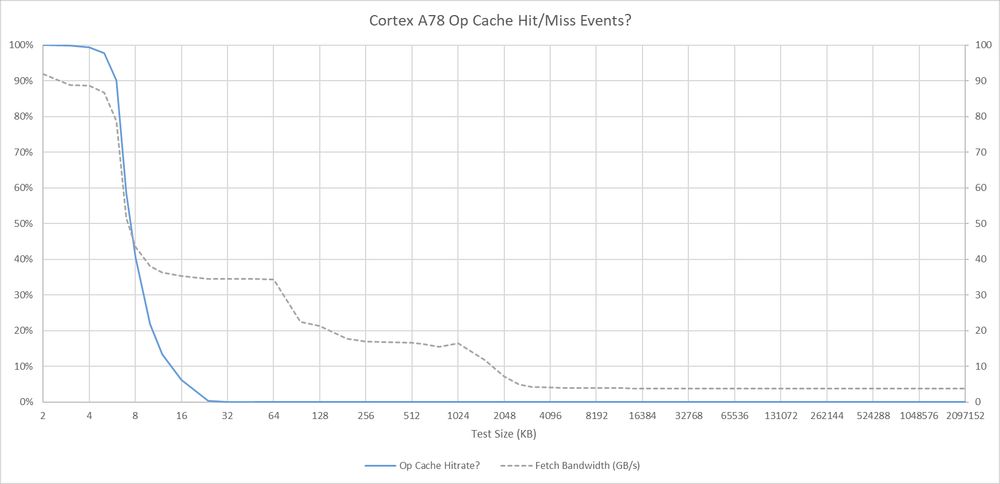
Arm never documented PMU events for their op cache. From brute force searching, there's a pair of possibly related events. Event 0x177 may be op cache hits, and 0x178 may be op cache misses. Both events appear to count instructions (not micro-ops or cachelines)
May 28, 2025 at 6:00 PM
Arm never documented PMU events for their op cache. From brute force searching, there's a pair of possibly related events. Event 0x177 may be op cache hits, and 0x178 may be op cache misses. Both events appear to count instructions (not micro-ops or cachelines)
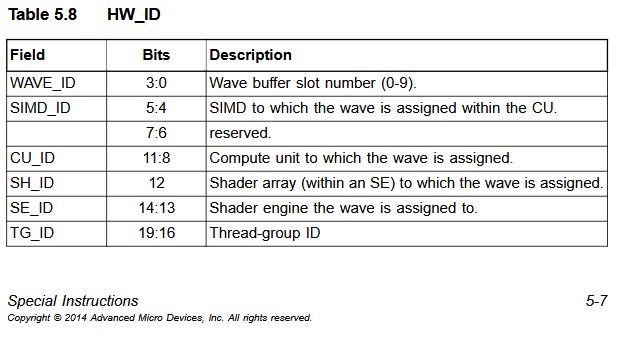
AMD had a separate Shader Array subdivision within Shader Engines even in the original GCN architecture. Interesting that it never mattered until RDNA added a L1 cache to the Shader Arrays and had multiple SAs per SE
April 13, 2025 at 1:33 AM
AMD had a separate Shader Array subdivision within Shader Engines even in the original GCN architecture. Interesting that it never mattered until RDNA added a L1 cache to the Shader Arrays and had multiple SAs per SE
Output from DispatchRays calls in CP2077's path tracing mode, with exposure adjusted manually and no denoising done
There's just not enough computing power available to get a good sample count while maintaining real-time performance. It's like setting ISO 102400 on a DSLR
There's just not enough computing power available to get a good sample count while maintaining real-time performance. It's like setting ISO 102400 on a DSLR



March 16, 2025 at 1:19 AM
Output from DispatchRays calls in CP2077's path tracing mode, with exposure adjusted manually and no denoising done
There's just not enough computing power available to get a good sample count while maintaining real-time performance. It's like setting ISO 102400 on a DSLR
There's just not enough computing power available to get a good sample count while maintaining real-time performance. It's like setting ISO 102400 on a DSLR
Messing around with microbenchmarking Arc B580
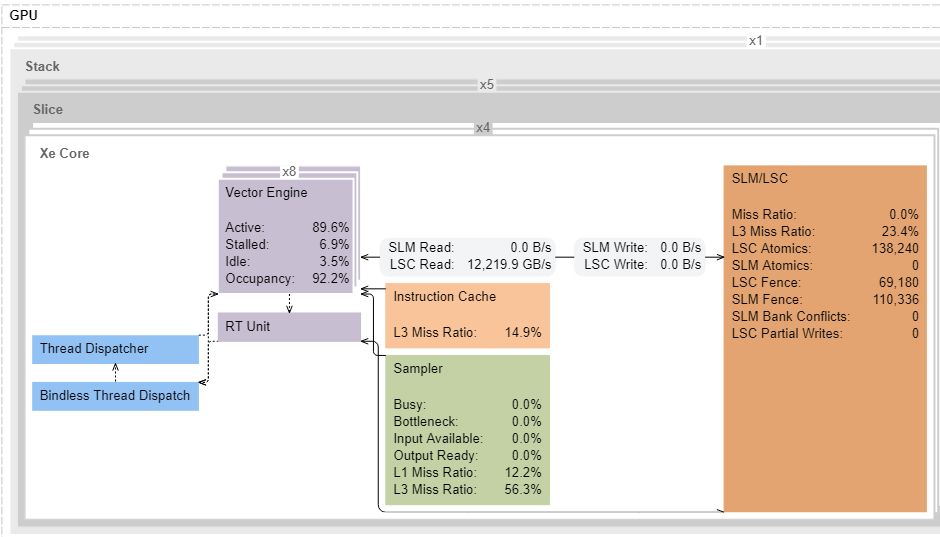
12.2 TB/s of L1 bandwidth, or ~214 bytes per Xe Core cycle
Theoretical is probably 256B/cycle. But close enough for now
12.2 TB/s of L1 bandwidth, or ~214 bytes per Xe Core cycle
Theoretical is probably 256B/cycle. But close enough for now
February 9, 2025 at 1:47 AM
Messing around with microbenchmarking Arc B580
12.2 TB/s of L1 bandwidth, or ~214 bytes per Xe Core cycle
Theoretical is probably 256B/cycle. But close enough for now
12.2 TB/s of L1 bandwidth, or ~214 bytes per Xe Core cycle
Theoretical is probably 256B/cycle. But close enough for now
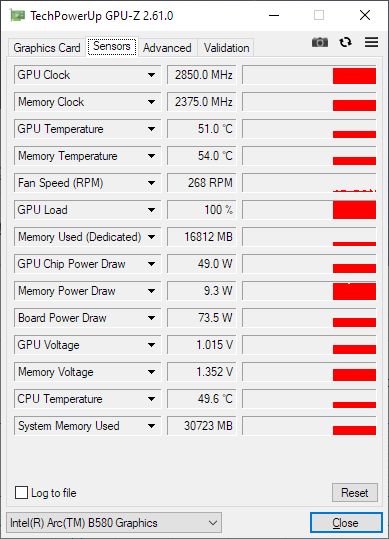
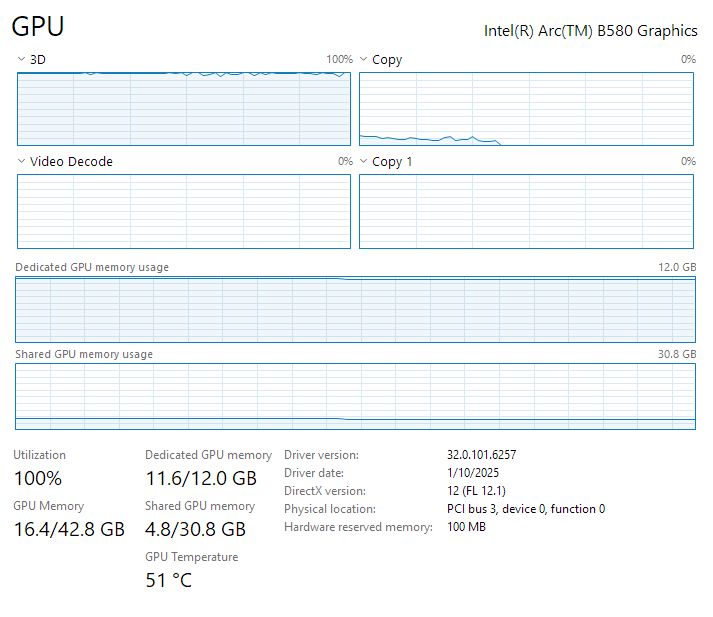
In games with higher VRAM usage (DCS), GPU-Z incorrectly shows 16.8 GB of dedicated memory used (out of 12 GB total lol). Task manager correctly shows shared memory allocated
January 19, 2025 at 8:26 PM
In games with higher VRAM usage (DCS), GPU-Z incorrectly shows 16.8 GB of dedicated memory used (out of 12 GB total lol). Task manager correctly shows shared memory allocated
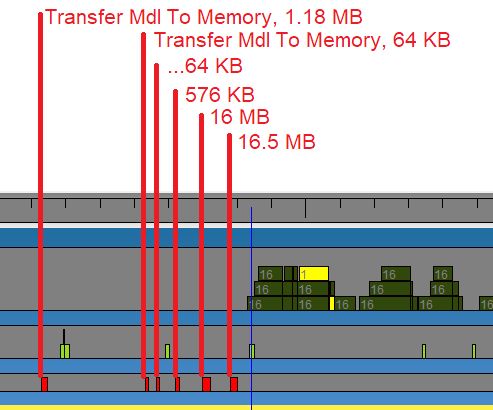
Frame drop in Baldur's Gate 3, as captured by GPUView. The game has to move ~35 MB to the GPU, which means reserving space to hold the data, getting the data contiguous in physical memory, and of course doing the transfer. Really fast, takes just 12.6 ms, but is enough to miss a 60Hz vsync interval

January 9, 2025 at 9:52 AM
Frame drop in Baldur's Gate 3, as captured by GPUView. The game has to move ~35 MB to the GPU, which means reserving space to hold the data, getting the data contiguous in physical memory, and of course doing the transfer. Really fast, takes just 12.6 ms, but is enough to miss a 60Hz vsync interval
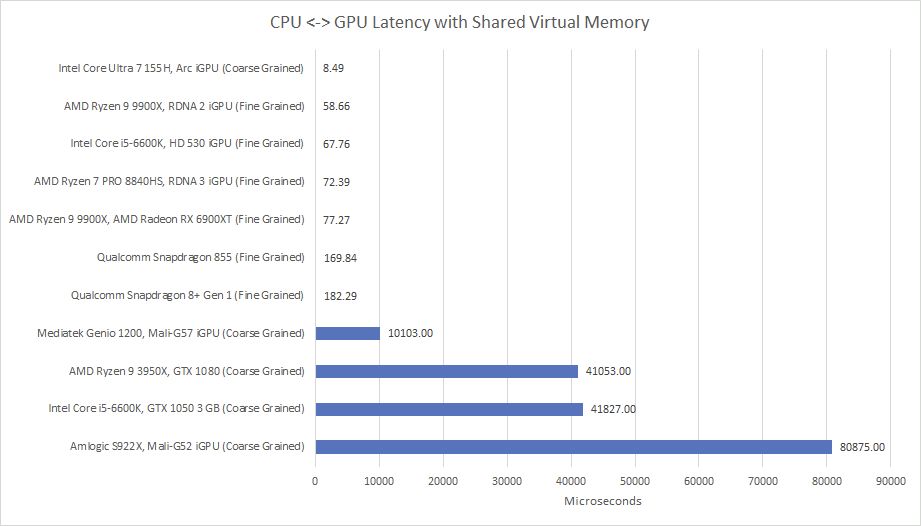
Zero-copy should be more natural on an iGPU versus a discrete one, but not all iGPUs can do zero-copy.
Here I'm testing OpenCL Shared Virtual Memory with a 256 MB buffer and only modifying one 32-bit value in it. Anything in the millisecond range implies the driver had to copy the entire buffer.
Here I'm testing OpenCL Shared Virtual Memory with a 256 MB buffer and only modifying one 32-bit value in it. Anything in the millisecond range implies the driver had to copy the entire buffer.
January 3, 2025 at 5:43 PM
Zero-copy should be more natural on an iGPU versus a discrete one, but not all iGPUs can do zero-copy.
Here I'm testing OpenCL Shared Virtual Memory with a 256 MB buffer and only modifying one 32-bit value in it. Anything in the millisecond range implies the driver had to copy the entire buffer.
Here I'm testing OpenCL Shared Virtual Memory with a 256 MB buffer and only modifying one 32-bit value in it. Anything in the millisecond range implies the driver had to copy the entire buffer.
Youtube AV1 decoding can be heavy on old CPUs, even at 1080P. IPC though is surprisingly good for AMD's very outdated 12h architecture.

December 8, 2024 at 2:32 AM
Youtube AV1 decoding can be heavy on old CPUs, even at 1080P. IPC though is surprisingly good for AMD's very outdated 12h architecture.
(bottom is from the Zen 4 PPR)
Zen 2 used eight bits, letting you select any combination of logical SMT threads within a CCX for L3 performance monitoring. More flexible, but would take too many bits with Zen 3's larger CCXes.
Zen 2 used eight bits, letting you select any combination of logical SMT threads within a CCX for L3 performance monitoring. More flexible, but would take too many bits with Zen 3's larger CCXes.

November 30, 2024 at 6:34 PM
(bottom is from the Zen 4 PPR)
Zen 2 used eight bits, letting you select any combination of logical SMT threads within a CCX for L3 performance monitoring. More flexible, but would take too many bits with Zen 3's larger CCXes.
Zen 2 used eight bits, letting you select any combination of logical SMT threads within a CCX for L3 performance monitoring. More flexible, but would take too many bits with Zen 3's larger CCXes.
In Zen 5's Processor Programming Reference, the L3 performance event select registers now take core IDs from 0-15. That would let the register handle 16 core CCX-es.
Of course this doesn't mean a 16 core CCX will show up, but it's interesting that AMD's laying the groundwork for it.
Of course this doesn't mean a 16 core CCX will show up, but it's interesting that AMD's laying the groundwork for it.

November 30, 2024 at 6:31 PM
In Zen 5's Processor Programming Reference, the L3 performance event select registers now take core IDs from 0-15. That would let the register handle 16 core CCX-es.
Of course this doesn't mean a 16 core CCX will show up, but it's interesting that AMD's laying the groundwork for it.
Of course this doesn't mean a 16 core CCX will show up, but it's interesting that AMD's laying the groundwork for it.
Zen 4 has a funny errata where an on-die 1.8V voltage regulator might be configured incorrectly, which then kills the CPU by feeding something too much voltage.

November 26, 2024 at 1:36 AM
Zen 4 has a funny errata where an on-die 1.8V voltage regulator might be configured incorrectly, which then kills the CPU by feeding something too much voltage.
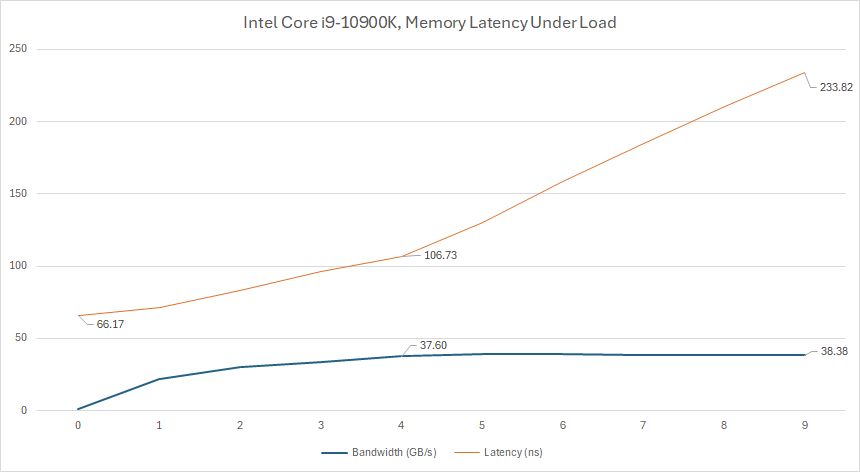
A closer look at the 10900K - you can get pretty close to bandwidth limits with 4 threads reading from big arrays, while latency stays under control.
But if more cores demand maximum bandwidth, latency goes way up
But if more cores demand maximum bandwidth, latency goes way up
November 22, 2024 at 12:59 AM
A closer look at the 10900K - you can get pretty close to bandwidth limits with 4 threads reading from big arrays, while latency stays under control.
But if more cores demand maximum bandwidth, latency goes way up
But if more cores demand maximum bandwidth, latency goes way up
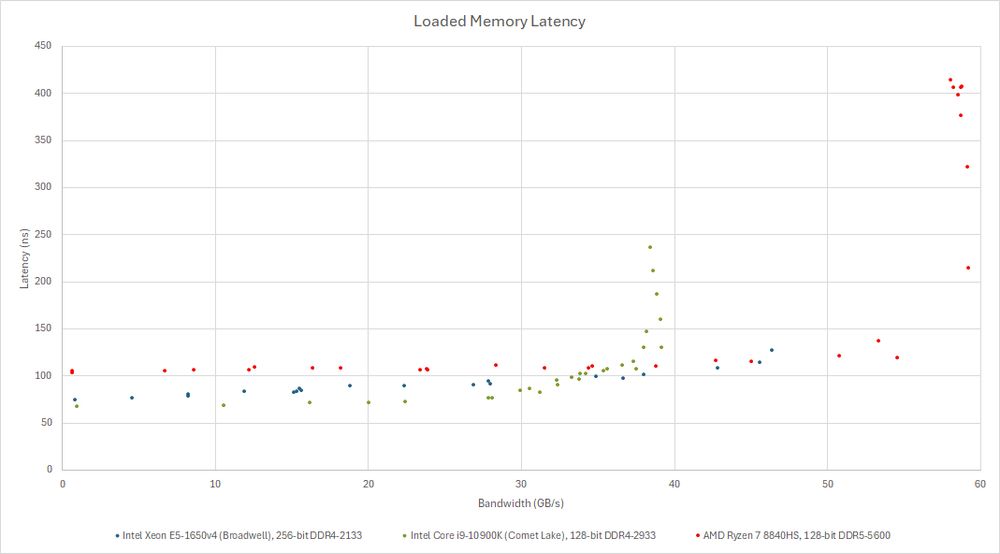
Memory latency under varying bandwidth loads on three different CPUs. The old Broadwell HEDT chip does well at providing consistent performance and minimizing noisy neighbor effects
November 22, 2024 at 12:54 AM
Memory latency under varying bandwidth loads on three different CPUs. The old Broadwell HEDT chip does well at providing consistent performance and minimizing noisy neighbor effects