




Yuqian Fu
@chert-fu.bsky.social
PhD Student @ RL&LLM
fyqqyf.github.io/home
fyqqyf.github.io/home
Pinned
Reposted by Yuqian Fu

Yesterday the hyped Genesis simulator released. But it's up to 10x slower than existing GPU sims, not 10-80x faster or 430,000x faster than realtime since they benchmark mostly static environments
blog post with corrected open source benchmarks & details: stoneztao.substack.com/p/the-new-hy...
blog post with corrected open source benchmarks & details: stoneztao.substack.com/p/the-new-hy...


December 20, 2024 at 11:49 PM
Yesterday the hyped Genesis simulator released. But it's up to 10x slower than existing GPU sims, not 10-80x faster or 430,000x faster than realtime since they benchmark mostly static environments
blog post with corrected open source benchmarks & details: stoneztao.substack.com/p/the-new-hy...
blog post with corrected open source benchmarks & details: stoneztao.substack.com/p/the-new-hy...
Reposted by Yuqian Fu

How to design your presentation?
Presentation is an essential skill for academics.
After attending so many meetings, prelims, thesis defenses, research talks, and lectures, I’ve realized that I may have been approaching it all wrong ...
Some (bitter) lessons I learned. 👇
Presentation is an essential skill for academics.
After attending so many meetings, prelims, thesis defenses, research talks, and lectures, I’ve realized that I may have been approaching it all wrong ...
Some (bitter) lessons I learned. 👇
December 7, 2024 at 1:11 AM
How to design your presentation?
Presentation is an essential skill for academics.
After attending so many meetings, prelims, thesis defenses, research talks, and lectures, I’ve realized that I may have been approaching it all wrong ...
Some (bitter) lessons I learned. 👇
Presentation is an essential skill for academics.
After attending so many meetings, prelims, thesis defenses, research talks, and lectures, I’ve realized that I may have been approaching it all wrong ...
Some (bitter) lessons I learned. 👇
Reposted by Yuqian Fu

Sharing some new work!
A big dream in AI is to create world models of sufficient quality that you can train agents within them.
Classic simulators lack visual diversity and realism. GenAI lacks physical accuracy. But combining the two can work pretty well!
Paper: arxiv.org/abs/2411.00083
A big dream in AI is to create world models of sufficient quality that you can train agents within them.
Classic simulators lack visual diversity and realism. GenAI lacks physical accuracy. But combining the two can work pretty well!
Paper: arxiv.org/abs/2411.00083
November 14, 2024 at 1:30 AM
Sharing some new work!
A big dream in AI is to create world models of sufficient quality that you can train agents within them.
Classic simulators lack visual diversity and realism. GenAI lacks physical accuracy. But combining the two can work pretty well!
Paper: arxiv.org/abs/2411.00083
A big dream in AI is to create world models of sufficient quality that you can train agents within them.
Classic simulators lack visual diversity and realism. GenAI lacks physical accuracy. But combining the two can work pretty well!
Paper: arxiv.org/abs/2411.00083
Reposted by Yuqian Fu

I wrote some thoughts on how to build good LM benchmarks: ofir.io/How-to-Build...
How to Build Good Language Modeling Benchmarks
Building benchmarks is important because they shine a spotlight on the weaknesses of existing language models and so can guide the community on how to improve them.
ofir.io
November 25, 2024 at 9:54 PM
I wrote some thoughts on how to build good LM benchmarks: ofir.io/How-to-Build...
Reposted by Yuqian Fu

The weak stance of RL is that using offline training to learn a value function or a set of options is always going to be useful (and maybe essential) for long horizon reasoning
November 17, 2024 at 11:11 PM
The weak stance of RL is that using offline training to learn a value function or a set of options is always going to be useful (and maybe essential) for long horizon reasoning
Reposted by Yuqian Fu

Eight years later, Yann LeCun’s cake 🍰 analogy was spot on: self-supervised > supervised > RL
> “If intelligence is a cake, the bulk of the cake is unsupervised learning, the icing on the cake is supervised learning, and the cherry on the cake is reinforcement learning (RL).”
> “If intelligence is a cake, the bulk of the cake is unsupervised learning, the icing on the cake is supervised learning, and the cherry on the cake is reinforcement learning (RL).”
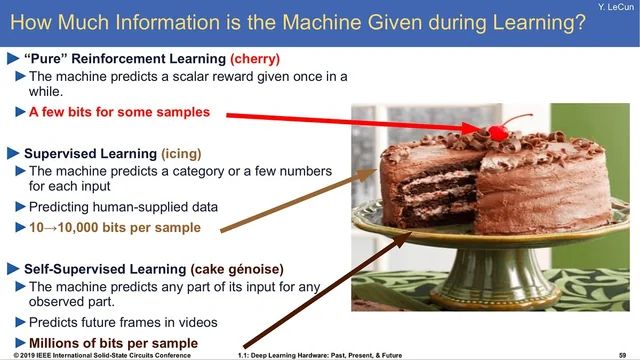
November 17, 2024 at 4:02 PM
Eight years later, Yann LeCun’s cake 🍰 analogy was spot on: self-supervised > supervised > RL
> “If intelligence is a cake, the bulk of the cake is unsupervised learning, the icing on the cake is supervised learning, and the cherry on the cake is reinforcement learning (RL).”
> “If intelligence is a cake, the bulk of the cake is unsupervised learning, the icing on the cake is supervised learning, and the cherry on the cake is reinforcement learning (RL).”
Honored to be selected as a Top Reviewer of #NeurIPS2024 🎉

November 18, 2024 at 1:53 AM
Honored to be selected as a Top Reviewer of #NeurIPS2024 🎉
Reposted by Yuqian Fu

To researchers doing LLM evaluation: prompting is *not a substitute* for direct probability measurements. Check out the camera-ready version of our work, to appear at EMNLP 2023! (w/ @rplevy.bsky.social)
Paper: arxiv.org/abs/2305.13264
Original thread: twitter.com/_jennhu/stat...
Paper: arxiv.org/abs/2305.13264
Original thread: twitter.com/_jennhu/stat...
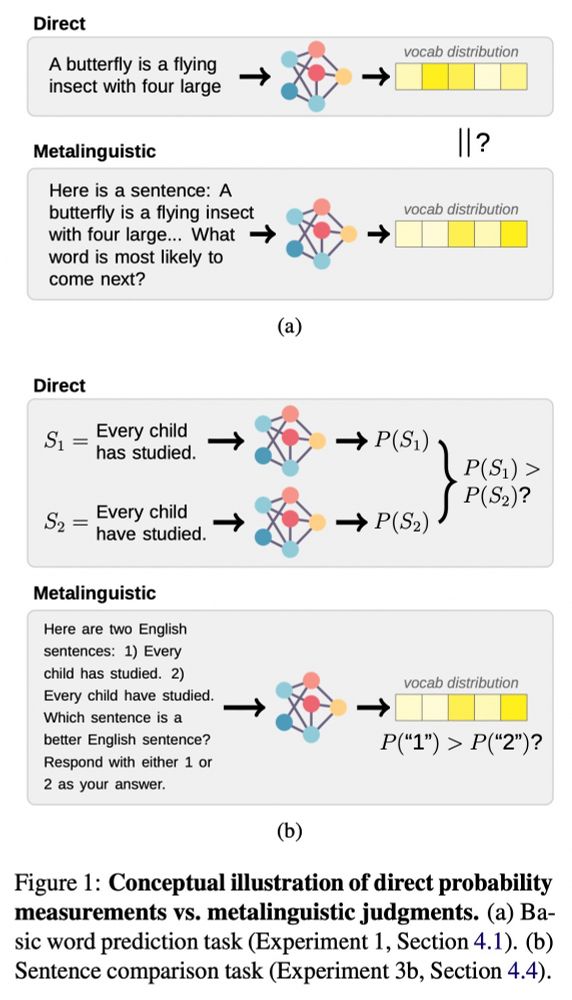
October 24, 2023 at 3:03 PM
To researchers doing LLM evaluation: prompting is *not a substitute* for direct probability measurements. Check out the camera-ready version of our work, to appear at EMNLP 2023! (w/ @rplevy.bsky.social)
Paper: arxiv.org/abs/2305.13264
Original thread: twitter.com/_jennhu/stat...
Paper: arxiv.org/abs/2305.13264
Original thread: twitter.com/_jennhu/stat...