



Charlotte Volk
@charlottevolk.bsky.social
MSc Student in NeuroAI @ McGill & Mila
w/ Blake Richards & Shahab Bakhtiari
w/ Blake Richards & Shahab Bakhtiari
A huge thank you to my collaborators @shahabbakht.bsky.social and Christopher Pack for their guidance on this project. We’d love to hear your thoughts and comments!
The preprint: www.biorxiv.org/content/10.1...
The preprint: www.biorxiv.org/content/10.1...

The curriculum effect in visual learning: the role of readout dimensionality
Generalization of visual perceptual learning (VPL) to unseen conditions varies across tasks. Previous work suggests that training curriculum may be integral to generalization, yet a theoretical explan...
www.biorxiv.org
September 30, 2025 at 2:26 PM
A huge thank you to my collaborators @shahabbakht.bsky.social and Christopher Pack for their guidance on this project. We’d love to hear your thoughts and comments!
The preprint: www.biorxiv.org/content/10.1...
The preprint: www.biorxiv.org/content/10.1...
16. Second, what is considered hard for one person may not be as hard for another person due to past experiences, innate differences, etc. Following our theoretical rule to reach low-dimensional readout subspaces post-training calls for an individualized approach to curriculum design.
September 30, 2025 at 2:26 PM
16. Second, what is considered hard for one person may not be as hard for another person due to past experiences, innate differences, etc. Following our theoretical rule to reach low-dimensional readout subspaces post-training calls for an individualized approach to curriculum design.
15. First, easy and hard are not easily definable for every task. It worked well for our simple orientation discrimination task, but as tasks become more naturalistic and complex, defining easiness will not be straightforward. Neural data may be helpful for giving an objective measure of difficulty.
September 30, 2025 at 2:26 PM
15. First, easy and hard are not easily definable for every task. It worked well for our simple orientation discrimination task, but as tasks become more naturalistic and complex, defining easiness will not be straightforward. Neural data may be helpful for giving an objective measure of difficulty.
14. In short:
Easy-to-hard learning curriculum (explicit or implicit) sets the dimensionality of the neural population recruited to solve the task + lower-d readout leads to better generalization.
But, there are some subtleties for applying this rule to the real world training design: 👇
Easy-to-hard learning curriculum (explicit or implicit) sets the dimensionality of the neural population recruited to solve the task + lower-d readout leads to better generalization.
But, there are some subtleties for applying this rule to the real world training design: 👇
September 30, 2025 at 2:26 PM
14. In short:
Easy-to-hard learning curriculum (explicit or implicit) sets the dimensionality of the neural population recruited to solve the task + lower-d readout leads to better generalization.
But, there are some subtleties for applying this rule to the real world training design: 👇
Easy-to-hard learning curriculum (explicit or implicit) sets the dimensionality of the neural population recruited to solve the task + lower-d readout leads to better generalization.
But, there are some subtleties for applying this rule to the real world training design: 👇
13. Is this low-d subspace what truly drives generalization? We tested this by training a model non-sequentially while transplanting the low-dimensional readout subspace from a different high-generalization model. We found that this partially "frozen" model could in fact generalize much better!

September 30, 2025 at 2:26 PM
13. Is this low-d subspace what truly drives generalization? We tested this by training a model non-sequentially while transplanting the low-dimensional readout subspace from a different high-generalization model. We found that this partially "frozen" model could in fact generalize much better!
12.
2) Initial training phase sets this dimensionality (measured with the Jaccard index). J = 1 → no change in the readout subspace
Therefore, learners following an explicit (or implicit) easy-to-hard curriculum will discover a lower-d readout subspace.
2) Initial training phase sets this dimensionality (measured with the Jaccard index). J = 1 → no change in the readout subspace
Therefore, learners following an explicit (or implicit) easy-to-hard curriculum will discover a lower-d readout subspace.

September 30, 2025 at 2:26 PM
12.
2) Initial training phase sets this dimensionality (measured with the Jaccard index). J = 1 → no change in the readout subspace
Therefore, learners following an explicit (or implicit) easy-to-hard curriculum will discover a lower-d readout subspace.
2) Initial training phase sets this dimensionality (measured with the Jaccard index). J = 1 → no change in the readout subspace
Therefore, learners following an explicit (or implicit) easy-to-hard curriculum will discover a lower-d readout subspace.
11. But how does curriculum affect readout dimensionality?
Two steps:
1) Easy tasks lead to a lower-d readout subspace: larger angle separation → lower-d readout
Two steps:
1) Easy tasks lead to a lower-d readout subspace: larger angle separation → lower-d readout

September 30, 2025 at 2:26 PM
11. But how does curriculum affect readout dimensionality?
Two steps:
1) Easy tasks lead to a lower-d readout subspace: larger angle separation → lower-d readout
Two steps:
1) Easy tasks lead to a lower-d readout subspace: larger angle separation → lower-d readout
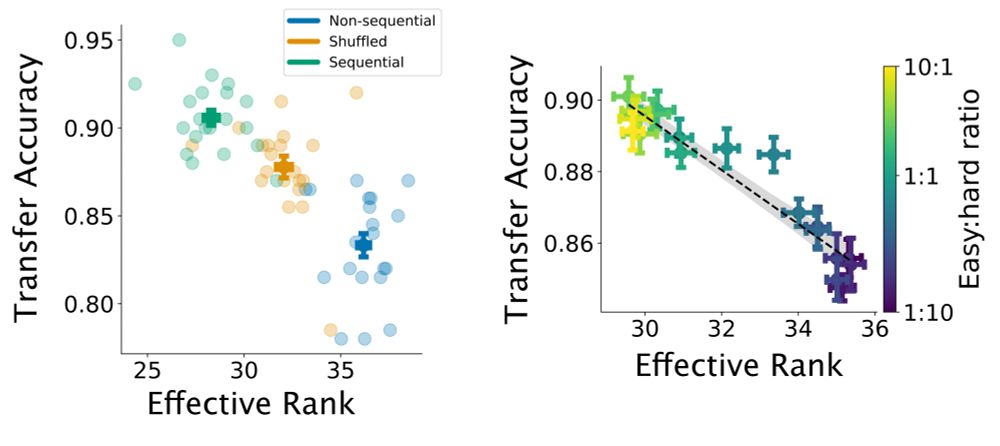
10. We measured the dimensionality of the models’ “readout subspace” - essentially, the dimensionality of the neural population that contributes most strongly to the model output. We found that the effective rank of the readout subspace directly correlates to transfer accuracy (i.e. generalization).
September 30, 2025 at 2:26 PM
10. We measured the dimensionality of the models’ “readout subspace” - essentially, the dimensionality of the neural population that contributes most strongly to the model output. We found that the effective rank of the readout subspace directly correlates to transfer accuracy (i.e. generalization).
9. We hypothesized that the efficacy of the learning curricula depends on how many distinct, useful visual features the brain recruits to solve the task - curricula which lead learners to rely on fewer, more essential visual features will result in better generalization.
September 30, 2025 at 2:26 PM
9. We hypothesized that the efficacy of the learning curricula depends on how many distinct, useful visual features the brain recruits to solve the task - curricula which lead learners to rely on fewer, more essential visual features will result in better generalization.
8. Interestingly, even in the shuffled curriculum, both humans and ANNs generalize better to new contexts when they focus on easy trials first, as measured by a “curriculum metric” in humans and the ratio of easy-to-hard samples used in the initial phase of shuffled training for the models.

September 30, 2025 at 2:26 PM
8. Interestingly, even in the shuffled curriculum, both humans and ANNs generalize better to new contexts when they focus on easy trials first, as measured by a “curriculum metric” in humans and the ratio of easy-to-hard samples used in the initial phase of shuffled training for the models.
7. We found:
- Sequential and shuffled curricula significantly outperform a non-sequential baseline in ANNs & humans.
- Models do better on a sequential curriculum; human observers show comparable improvement on both sequential & shuffled, but with substantial variability in the shuffled curriculum.
- Sequential and shuffled curricula significantly outperform a non-sequential baseline in ANNs & humans.
- Models do better on a sequential curriculum; human observers show comparable improvement on both sequential & shuffled, but with substantial variability in the shuffled curriculum.

September 30, 2025 at 2:26 PM
7. We found:
- Sequential and shuffled curricula significantly outperform a non-sequential baseline in ANNs & humans.
- Models do better on a sequential curriculum; human observers show comparable improvement on both sequential & shuffled, but with substantial variability in the shuffled curriculum.
- Sequential and shuffled curricula significantly outperform a non-sequential baseline in ANNs & humans.
- Models do better on a sequential curriculum; human observers show comparable improvement on both sequential & shuffled, but with substantial variability in the shuffled curriculum.
6. We trained humans and ANNs on orientation discrimination comparing 3 curricula:
1) A sequential easy-to-hard curriculum
2) A shuffled curriculum with randomly interleaved easy & hard trials
3) A non-sequential baseline with only hard trials.
We tested generalization on a hard transfer condition.
1) A sequential easy-to-hard curriculum
2) A shuffled curriculum with randomly interleaved easy & hard trials
3) A non-sequential baseline with only hard trials.
We tested generalization on a hard transfer condition.
September 30, 2025 at 2:26 PM
6. We trained humans and ANNs on orientation discrimination comparing 3 curricula:
1) A sequential easy-to-hard curriculum
2) A shuffled curriculum with randomly interleaved easy & hard trials
3) A non-sequential baseline with only hard trials.
We tested generalization on a hard transfer condition.
1) A sequential easy-to-hard curriculum
2) A shuffled curriculum with randomly interleaved easy & hard trials
3) A non-sequential baseline with only hard trials.
We tested generalization on a hard transfer condition.
5. In this study, we leveraged ANNs to develop a mechanistic predictive theory of learning generalization in humans. Specifically, we wanted to understand the role of **learning curriculum**, and develop a theory of how curriculum affects generalization.
September 30, 2025 at 2:26 PM
5. In this study, we leveraged ANNs to develop a mechanistic predictive theory of learning generalization in humans. Specifically, we wanted to understand the role of **learning curriculum**, and develop a theory of how curriculum affects generalization.
4. We know that artificial neural networks (ANNs) fail to generalize in similar ways to humans in simple visual learning tasks, thanks to the previous work of Wenliang and Seitz (2018) → more difficult training tasks lead to worse generalization, which is a phenomenon observed in humans and ANNs.
September 30, 2025 at 2:26 PM
4. We know that artificial neural networks (ANNs) fail to generalize in similar ways to humans in simple visual learning tasks, thanks to the previous work of Wenliang and Seitz (2018) → more difficult training tasks lead to worse generalization, which is a phenomenon observed in humans and ANNs.
3. But - people don’t *always* fail to generalize. Generalization is quite variable across tasks (Ahissar & Hochstein, 1997), and the reasons behind it are unclear. Hence, the importance of a theory of generalization → If you design a new training paradigm, you want to predict its generalization.

September 30, 2025 at 2:26 PM
3. But - people don’t *always* fail to generalize. Generalization is quite variable across tasks (Ahissar & Hochstein, 1997), and the reasons behind it are unclear. Hence, the importance of a theory of generalization → If you design a new training paradigm, you want to predict its generalization.
2. Improving on simple visual tasks (e.g., texture discrimination) through practice does not necessarily transfer to a slightly different version of the same task (a new location or rotation). This has been known since the early 90s. (e.g. Karni and Sagi, 1991).

September 30, 2025 at 2:26 PM
2. Improving on simple visual tasks (e.g., texture discrimination) through practice does not necessarily transfer to a slightly different version of the same task (a new location or rotation). This has been known since the early 90s. (e.g. Karni and Sagi, 1991).
1. Learning generalization has been one of the main focuses of any training domain, e.g., expert training, athletics, and rehabilitation. When you learn or improve on a skill, you want your improved skills to be applicable to new situations. But, humans don’t always generalize well to new contexts.
September 30, 2025 at 2:26 PM
1. Learning generalization has been one of the main focuses of any training domain, e.g., expert training, athletics, and rehabilitation. When you learn or improve on a skill, you want your improved skills to be applicable to new situations. But, humans don’t always generalize well to new contexts.