



Charlotte Volk
@charlottevolk.bsky.social
MSc Student in NeuroAI @ McGill & Mila
w/ Blake Richards & Shahab Bakhtiari
w/ Blake Richards & Shahab Bakhtiari
13. Is this low-d subspace what truly drives generalization? We tested this by training a model non-sequentially while transplanting the low-dimensional readout subspace from a different high-generalization model. We found that this partially "frozen" model could in fact generalize much better!

September 30, 2025 at 2:26 PM
13. Is this low-d subspace what truly drives generalization? We tested this by training a model non-sequentially while transplanting the low-dimensional readout subspace from a different high-generalization model. We found that this partially "frozen" model could in fact generalize much better!
12.
2) Initial training phase sets this dimensionality (measured with the Jaccard index). J = 1 → no change in the readout subspace
Therefore, learners following an explicit (or implicit) easy-to-hard curriculum will discover a lower-d readout subspace.
2) Initial training phase sets this dimensionality (measured with the Jaccard index). J = 1 → no change in the readout subspace
Therefore, learners following an explicit (or implicit) easy-to-hard curriculum will discover a lower-d readout subspace.

September 30, 2025 at 2:26 PM
12.
2) Initial training phase sets this dimensionality (measured with the Jaccard index). J = 1 → no change in the readout subspace
Therefore, learners following an explicit (or implicit) easy-to-hard curriculum will discover a lower-d readout subspace.
2) Initial training phase sets this dimensionality (measured with the Jaccard index). J = 1 → no change in the readout subspace
Therefore, learners following an explicit (or implicit) easy-to-hard curriculum will discover a lower-d readout subspace.
11. But how does curriculum affect readout dimensionality?
Two steps:
1) Easy tasks lead to a lower-d readout subspace: larger angle separation → lower-d readout
Two steps:
1) Easy tasks lead to a lower-d readout subspace: larger angle separation → lower-d readout

September 30, 2025 at 2:26 PM
11. But how does curriculum affect readout dimensionality?
Two steps:
1) Easy tasks lead to a lower-d readout subspace: larger angle separation → lower-d readout
Two steps:
1) Easy tasks lead to a lower-d readout subspace: larger angle separation → lower-d readout
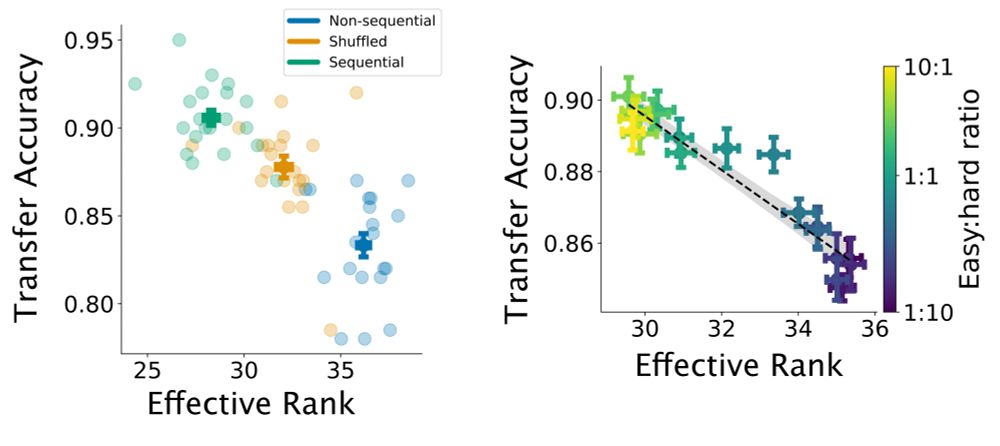
10. We measured the dimensionality of the models’ “readout subspace” - essentially, the dimensionality of the neural population that contributes most strongly to the model output. We found that the effective rank of the readout subspace directly correlates to transfer accuracy (i.e. generalization).
September 30, 2025 at 2:26 PM
10. We measured the dimensionality of the models’ “readout subspace” - essentially, the dimensionality of the neural population that contributes most strongly to the model output. We found that the effective rank of the readout subspace directly correlates to transfer accuracy (i.e. generalization).
8. Interestingly, even in the shuffled curriculum, both humans and ANNs generalize better to new contexts when they focus on easy trials first, as measured by a “curriculum metric” in humans and the ratio of easy-to-hard samples used in the initial phase of shuffled training for the models.

September 30, 2025 at 2:26 PM
8. Interestingly, even in the shuffled curriculum, both humans and ANNs generalize better to new contexts when they focus on easy trials first, as measured by a “curriculum metric” in humans and the ratio of easy-to-hard samples used in the initial phase of shuffled training for the models.
7. We found:
- Sequential and shuffled curricula significantly outperform a non-sequential baseline in ANNs & humans.
- Models do better on a sequential curriculum; human observers show comparable improvement on both sequential & shuffled, but with substantial variability in the shuffled curriculum.
- Sequential and shuffled curricula significantly outperform a non-sequential baseline in ANNs & humans.
- Models do better on a sequential curriculum; human observers show comparable improvement on both sequential & shuffled, but with substantial variability in the shuffled curriculum.

September 30, 2025 at 2:26 PM
7. We found:
- Sequential and shuffled curricula significantly outperform a non-sequential baseline in ANNs & humans.
- Models do better on a sequential curriculum; human observers show comparable improvement on both sequential & shuffled, but with substantial variability in the shuffled curriculum.
- Sequential and shuffled curricula significantly outperform a non-sequential baseline in ANNs & humans.
- Models do better on a sequential curriculum; human observers show comparable improvement on both sequential & shuffled, but with substantial variability in the shuffled curriculum.
3. But - people don’t *always* fail to generalize. Generalization is quite variable across tasks (Ahissar & Hochstein, 1997), and the reasons behind it are unclear. Hence, the importance of a theory of generalization → If you design a new training paradigm, you want to predict its generalization.

September 30, 2025 at 2:26 PM
3. But - people don’t *always* fail to generalize. Generalization is quite variable across tasks (Ahissar & Hochstein, 1997), and the reasons behind it are unclear. Hence, the importance of a theory of generalization → If you design a new training paradigm, you want to predict its generalization.
2. Improving on simple visual tasks (e.g., texture discrimination) through practice does not necessarily transfer to a slightly different version of the same task (a new location or rotation). This has been known since the early 90s. (e.g. Karni and Sagi, 1991).

September 30, 2025 at 2:26 PM
2. Improving on simple visual tasks (e.g., texture discrimination) through practice does not necessarily transfer to a slightly different version of the same task (a new location or rotation). This has been known since the early 90s. (e.g. Karni and Sagi, 1991).