




Aravindh Mahendran
@blumeara.bsky.social
Research Scientist, Google Deepmind, Berlin
I also like bouldering, reading books, Berlin bookswap meetup, boardgames and anime.
I also like bouldering, reading books, Berlin bookswap meetup, boardgames and anime.
Reposted by Aravindh Mahendran

Thrilled to share our latest work on SciVid, to appear at #ICCV2025! 🎉
SciVid offers cross-domain evaluation of video models in scientific applications, including medical CV, animal behavior, & weather forecasting 🧪🌍📽️🪰🐭🫀🌦️
📝 Check out our paper: arxiv.org/abs/2507.03578
[1/4]🧵
SciVid offers cross-domain evaluation of video models in scientific applications, including medical CV, animal behavior, & weather forecasting 🧪🌍📽️🪰🐭🫀🌦️
📝 Check out our paper: arxiv.org/abs/2507.03578
[1/4]🧵

July 8, 2025 at 11:08 AM
Thrilled to share our latest work on SciVid, to appear at #ICCV2025! 🎉
SciVid offers cross-domain evaluation of video models in scientific applications, including medical CV, animal behavior, & weather forecasting 🧪🌍📽️🪰🐭🫀🌦️
📝 Check out our paper: arxiv.org/abs/2507.03578
[1/4]🧵
SciVid offers cross-domain evaluation of video models in scientific applications, including medical CV, animal behavior, & weather forecasting 🧪🌍📽️🪰🐭🫀🌦️
📝 Check out our paper: arxiv.org/abs/2507.03578
[1/4]🧵
Reposted by Aravindh Mahendran

Painting process!
A time lapse of me painting a fanart of Lycoris Recoil, Chisato, onto a Chopstick
A time lapse of me painting a fanart of Lycoris Recoil, Chisato, onto a Chopstick
June 5, 2025 at 3:35 PM
Painting process!
A time lapse of me painting a fanart of Lycoris Recoil, Chisato, onto a Chopstick
A time lapse of me painting a fanart of Lycoris Recoil, Chisato, onto a Chopstick
Reposted by Aravindh Mahendran
This is the whole pair! Cuties💕
Took me around 3hours to make them. There is a light firework in the background and if you hold them closer they really form the heart with their hands:-)
#Fanart
#LycorisRecoil
#ChisatoXTakina
#PaintingOnChopsticks
Took me around 3hours to make them. There is a light firework in the background and if you hold them closer they really form the heart with their hands:-)
#Fanart
#LycorisRecoil
#ChisatoXTakina
#PaintingOnChopsticks

June 7, 2025 at 8:44 PM
This is the whole pair! Cuties💕
Took me around 3hours to make them. There is a light firework in the background and if you hold them closer they really form the heart with their hands:-)
#Fanart
#LycorisRecoil
#ChisatoXTakina
#PaintingOnChopsticks
Took me around 3hours to make them. There is a light firework in the background and if you hold them closer they really form the heart with their hands:-)
#Fanart
#LycorisRecoil
#ChisatoXTakina
#PaintingOnChopsticks
Reposted by Aravindh Mahendran
The prototype of Chopsticks with motifs of Julie Valesque @julievasques.bsky.social are ready!
😍🤩😍
I am looking forward for the real ones. Just some small adjustments to go! So happy to have this prototype now in my kitchen as cooking sticks🤗🤗 hope they arrive in Brazilia soon then, too!
😍🤩😍
I am looking forward for the real ones. Just some small adjustments to go! So happy to have this prototype now in my kitchen as cooking sticks🤗🤗 hope they arrive in Brazilia soon then, too!

June 11, 2025 at 8:58 PM
The prototype of Chopsticks with motifs of Julie Valesque @julievasques.bsky.social are ready!
😍🤩😍
I am looking forward for the real ones. Just some small adjustments to go! So happy to have this prototype now in my kitchen as cooking sticks🤗🤗 hope they arrive in Brazilia soon then, too!
😍🤩😍
I am looking forward for the real ones. Just some small adjustments to go! So happy to have this prototype now in my kitchen as cooking sticks🤗🤗 hope they arrive in Brazilia soon then, too!
Reposted by Aravindh Mahendran

Would you present your next NeurIPS paper in Europe instead of traveling to San Diego (US) if this was an option? Søren Hauberg (DTU) and I would love to hear the answer through this poll: (1/6)

NeurIPS participation in Europe
We seek to understand if there is interest in being able to attend NeurIPS in Europe, i.e. without travelling to San Diego, US. In the following, assume that it is possible to present accepted papers ...
docs.google.com
March 30, 2025 at 6:04 PM
Would you present your next NeurIPS paper in Europe instead of traveling to San Diego (US) if this was an option? Søren Hauberg (DTU) and I would love to hear the answer through this poll: (1/6)
Reposted by Aravindh Mahendran

🔥Excited to introduce RINS - a technique that boosts model performance by recursively applying early layers during inference without increasing model size or training compute flops! Not only does it significantly improve LMs, but also multimodal systems like SigLIP.
(1/N)
(1/N)
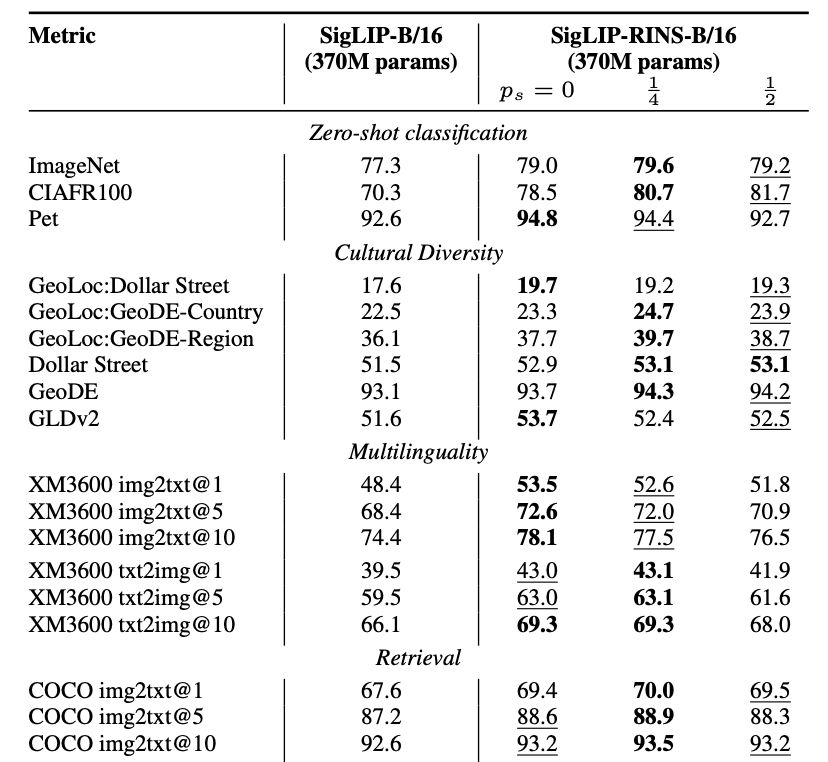
February 12, 2025 at 8:54 AM
🔥Excited to introduce RINS - a technique that boosts model performance by recursively applying early layers during inference without increasing model size or training compute flops! Not only does it significantly improve LMs, but also multimodal systems like SigLIP.
(1/N)
(1/N)
Reposted by Aravindh Mahendran

TRecViT: A Recurrent Video Transformer
arxiv.org/abs/2412.14294
Causal, 3× fewer parameters, 12× less memory, 5× higher FLOPs than (non-causal) ViViT, matching / outperforming on Kinetics & SSv2 action recognition.
Code and checkpoints out soon.
arxiv.org/abs/2412.14294
Causal, 3× fewer parameters, 12× less memory, 5× higher FLOPs than (non-causal) ViViT, matching / outperforming on Kinetics & SSv2 action recognition.
Code and checkpoints out soon.

January 10, 2025 at 3:44 PM
TRecViT: A Recurrent Video Transformer
arxiv.org/abs/2412.14294
Causal, 3× fewer parameters, 12× less memory, 5× higher FLOPs than (non-causal) ViViT, matching / outperforming on Kinetics & SSv2 action recognition.
Code and checkpoints out soon.
arxiv.org/abs/2412.14294
Causal, 3× fewer parameters, 12× less memory, 5× higher FLOPs than (non-causal) ViViT, matching / outperforming on Kinetics & SSv2 action recognition.
Code and checkpoints out soon.
Reposted by Aravindh Mahendran
Check out @tkipf.bsky.social's post on MooG, the latest in our line of research on self-supervised neural scene representations learned from raw pixels:
SRT: srt-paper.github.io
OSRT: osrt-paper.github.io
RUST: rust-paper.github.io
DyST: dyst-paper.github.io
MooG: moog-paper.github.io
SRT: srt-paper.github.io
OSRT: osrt-paper.github.io
RUST: rust-paper.github.io
DyST: dyst-paper.github.io
MooG: moog-paper.github.io
January 13, 2025 at 3:25 PM
Check out @tkipf.bsky.social's post on MooG, the latest in our line of research on self-supervised neural scene representations learned from raw pixels:
SRT: srt-paper.github.io
OSRT: osrt-paper.github.io
RUST: rust-paper.github.io
DyST: dyst-paper.github.io
MooG: moog-paper.github.io
SRT: srt-paper.github.io
OSRT: osrt-paper.github.io
RUST: rust-paper.github.io
DyST: dyst-paper.github.io
MooG: moog-paper.github.io
Reposted by Aravindh Mahendran

🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
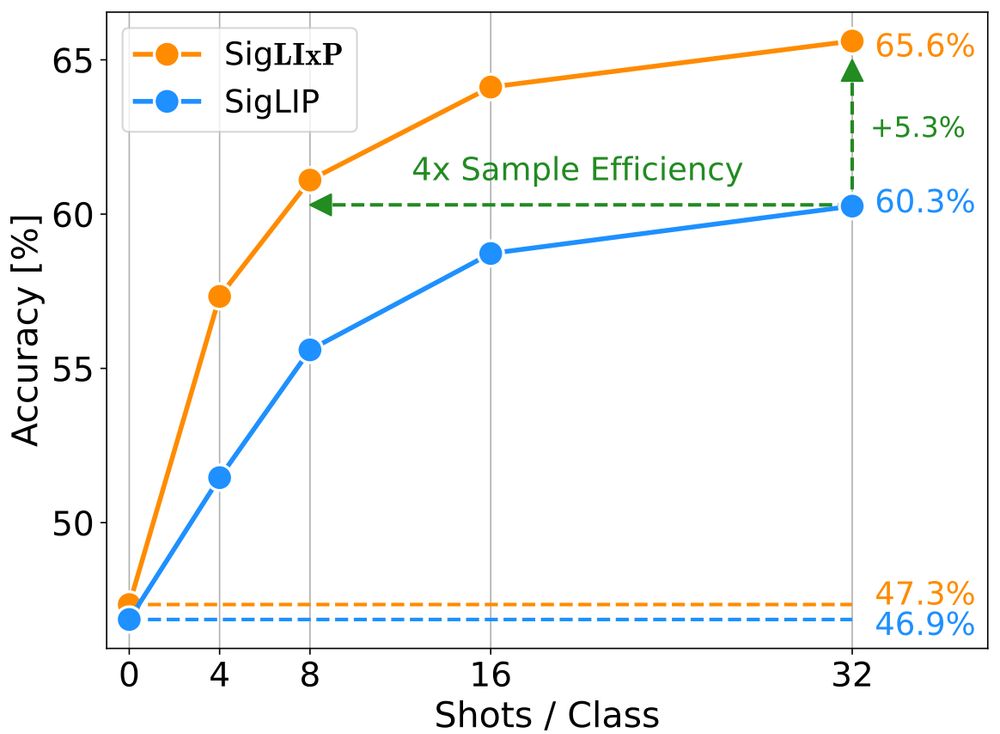
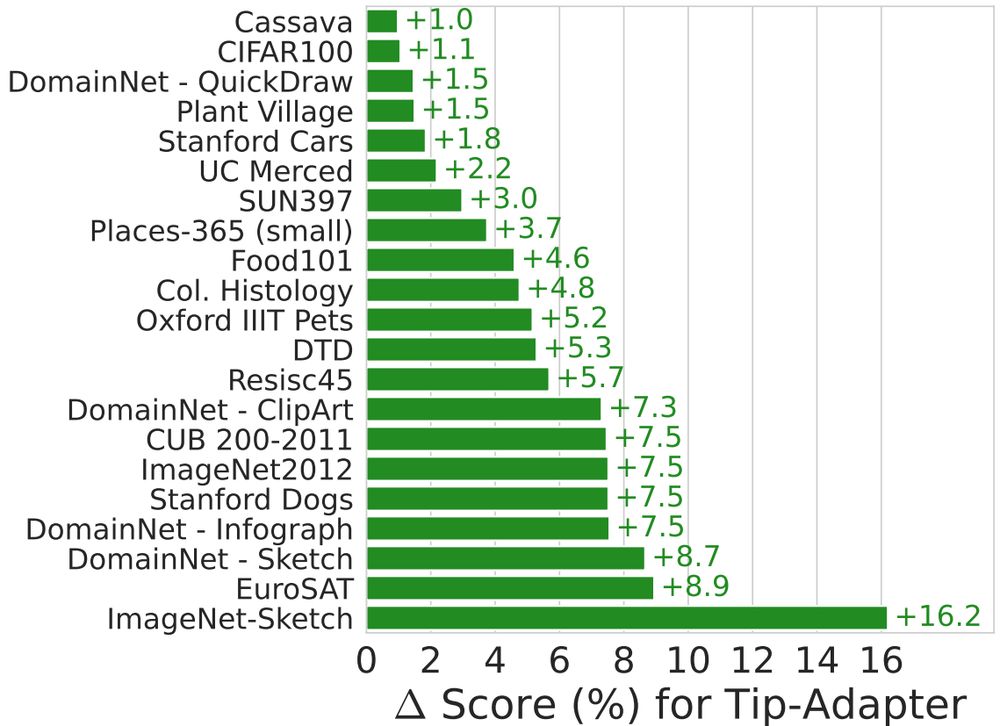

November 28, 2024 at 2:33 PM
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Reposted by Aravindh Mahendran

Woo hoo! 1K new followers, welcome to 💙🦋!
For science-minded folks, there are some very cool tricks 🚀…
If you use any of these emojis: 👩🔬|👩🏻🔬|👩🏼🔬|👩🏽🔬|👩🏾🔬|👩🏿🔬 your post will index on a Women in STEM feed
If you use 🧪 a Science feed
If you use 🧠 a Neuroscience feed
Go get it 🚀🧪🧠👩🔬💙🎊
For science-minded folks, there are some very cool tricks 🚀…
If you use any of these emojis: 👩🔬|👩🏻🔬|👩🏼🔬|👩🏽🔬|👩🏾🔬|👩🏿🔬 your post will index on a Women in STEM feed
If you use 🧪 a Science feed
If you use 🧠 a Neuroscience feed
Go get it 🚀🧪🧠👩🔬💙🎊
November 12, 2024 at 10:25 AM
Woo hoo! 1K new followers, welcome to 💙🦋!
For science-minded folks, there are some very cool tricks 🚀…
If you use any of these emojis: 👩🔬|👩🏻🔬|👩🏼🔬|👩🏽🔬|👩🏾🔬|👩🏿🔬 your post will index on a Women in STEM feed
If you use 🧪 a Science feed
If you use 🧠 a Neuroscience feed
Go get it 🚀🧪🧠👩🔬💙🎊
For science-minded folks, there are some very cool tricks 🚀…
If you use any of these emojis: 👩🔬|👩🏻🔬|👩🏼🔬|👩🏽🔬|👩🏾🔬|👩🏿🔬 your post will index on a Women in STEM feed
If you use 🧪 a Science feed
If you use 🧠 a Neuroscience feed
Go get it 🚀🧪🧠👩🔬💙🎊