




Benjamin Warner
@benjaminwarner.dev
Research at sophont.med, previously answer.ai
Vaccines save lives.
Vaccines save lives.
GPT 5 Thinking (the smartest one) ignored the low quality sources and only cited the high quality and reliable sources.
August 24, 2025 at 9:53 PM
GPT 5 Thinking (the smartest one) ignored the low quality sources and only cited the high quality and reliable sources.
A modern example: When attempting to trick GPT 5 + search with a question on the health benefits of raw milk, GPT 5 Fast (the less smart one) started out by citing the raw milk institute before eventually concluding there aren’t any benefits and citing high quality sources.
August 24, 2025 at 9:53 PM
A modern example: When attempting to trick GPT 5 + search with a question on the health benefits of raw milk, GPT 5 Fast (the less smart one) started out by citing the raw milk institute before eventually concluding there aren’t any benefits and citing high quality sources.
There isn't a canonical version, but there are retrieval models from GTE and Nomic which might work for your task.
GTE: huggingface.co/Alibaba-NLP/...
Nomic: huggingface.co/nomic-ai/mod...
GTE: huggingface.co/Alibaba-NLP/...
Nomic: huggingface.co/nomic-ai/mod...
February 20, 2025 at 4:35 PM
There isn't a canonical version, but there are retrieval models from GTE and Nomic which might work for your task.
GTE: huggingface.co/Alibaba-NLP/...
Nomic: huggingface.co/nomic-ai/mod...
GTE: huggingface.co/Alibaba-NLP/...
Nomic: huggingface.co/nomic-ai/mod...
For more details, including our simple training method, see Benjamin Clavié's twitter announcement, our model, blog post, and paper.
Twitter: x.com/bclavie/stat...
Model: huggingface.co/answerdotai/...
Blog: www.answer.ai/posts/2025-0...
Paper: arxiv.org/abs/2502.03793
Twitter: x.com/bclavie/stat...
Model: huggingface.co/answerdotai/...
Blog: www.answer.ai/posts/2025-0...
Paper: arxiv.org/abs/2502.03793
February 10, 2025 at 6:13 PM
For more details, including our simple training method, see Benjamin Clavié's twitter announcement, our model, blog post, and paper.
Twitter: x.com/bclavie/stat...
Model: huggingface.co/answerdotai/...
Blog: www.answer.ai/posts/2025-0...
Paper: arxiv.org/abs/2502.03793
Twitter: x.com/bclavie/stat...
Model: huggingface.co/answerdotai/...
Blog: www.answer.ai/posts/2025-0...
Paper: arxiv.org/abs/2502.03793
Can all encoders be instruction-tuned? Can we replicate ModernBERT's results with an older model like RoBERTa or peer model like GTE-en-MLM?
No. And it's not close.
No. And it's not close.

February 10, 2025 at 6:13 PM
Can all encoders be instruction-tuned? Can we replicate ModernBERT's results with an older model like RoBERTa or peer model like GTE-en-MLM?
No. And it's not close.
No. And it's not close.
When we finetune ModernBERT-Large-Instruct on task specific datasets, the generative MLM head is better or nearly equal to standard classification heads.

February 10, 2025 at 6:13 PM
When we finetune ModernBERT-Large-Instruct on task specific datasets, the generative MLM head is better or nearly equal to standard classification heads.
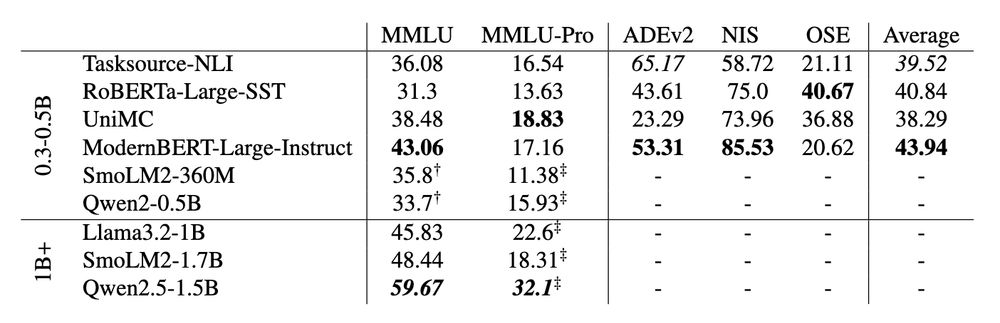
After instruction tuning on Flan, ModernBERT-Large-Instruct outperforms similarly sized LLMs on MMLU & MMLU-Pro, and achieves ~90 percent of Llama 3.2 1B's performance with ~65 percent fewer parameters.
February 10, 2025 at 6:13 PM
After instruction tuning on Flan, ModernBERT-Large-Instruct outperforms similarly sized LLMs on MMLU & MMLU-Pro, and achieves ~90 percent of Llama 3.2 1B's performance with ~65 percent fewer parameters.
With @bclavie.bsky.social and @ncoop57.bsky.social, we tried to answer two questions:
- Can an instruction-tuned ModernBERT zero-shot tasks using the MLM-head?
- Could we then fine-tune instruction-tuned ModernBERT to complete any task?
Detailed answers: arxiv.org/abs/2502.03793
- Can an instruction-tuned ModernBERT zero-shot tasks using the MLM-head?
- Could we then fine-tune instruction-tuned ModernBERT to complete any task?
Detailed answers: arxiv.org/abs/2502.03793

It's All in The [MASK]: Simple Instruction-Tuning Enables BERT-like Masked Language Models As Generative Classifiers
While encoder-only models such as BERT and ModernBERT are ubiquitous in real-world NLP applications, their conventional reliance on task-specific classification heads can limit their applicability com...
arxiv.org
February 10, 2025 at 6:13 PM
With @bclavie.bsky.social and @ncoop57.bsky.social, we tried to answer two questions:
- Can an instruction-tuned ModernBERT zero-shot tasks using the MLM-head?
- Could we then fine-tune instruction-tuned ModernBERT to complete any task?
Detailed answers: arxiv.org/abs/2502.03793
- Can an instruction-tuned ModernBERT zero-shot tasks using the MLM-head?
- Could we then fine-tune instruction-tuned ModernBERT to complete any task?
Detailed answers: arxiv.org/abs/2502.03793
You can find the models on Hugging Face here:
- gte-modernbert-base: huggingface.co/Alibaba-NLP/...
- gte-reranker-modernbert-base: huggingface.co/Alibaba-NLP/...
- gte-modernbert-base: huggingface.co/Alibaba-NLP/...
- gte-reranker-modernbert-base: huggingface.co/Alibaba-NLP/...

Alibaba-NLP/gte-modernbert-base · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
January 23, 2025 at 7:22 PM
You can find the models on Hugging Face here:
- gte-modernbert-base: huggingface.co/Alibaba-NLP/...
- gte-reranker-modernbert-base: huggingface.co/Alibaba-NLP/...
- gte-modernbert-base: huggingface.co/Alibaba-NLP/...
- gte-reranker-modernbert-base: huggingface.co/Alibaba-NLP/...
What's ModernBERT? It's a drop-in replacement for existing BERT models, but smarter, faster, and supports longer context.
Check out our announcement post for more details: huggingface.co/blog/modernb...
Check out our announcement post for more details: huggingface.co/blog/modernb...

Finally, a Replacement for BERT: Introducing ModernBERT
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
January 10, 2025 at 6:28 PM
What's ModernBERT? It's a drop-in replacement for existing BERT models, but smarter, faster, and supports longer context.
Check out our announcement post for more details: huggingface.co/blog/modernb...
Check out our announcement post for more details: huggingface.co/blog/modernb...