




Benjamin Warner
@benjaminwarner.dev
Research at sophont.med, previously answer.ai
Vaccines save lives.
Vaccines save lives.
Can all encoders be instruction-tuned? Can we replicate ModernBERT's results with an older model like RoBERTa or peer model like GTE-en-MLM?
No. And it's not close.
No. And it's not close.

February 10, 2025 at 6:13 PM
Can all encoders be instruction-tuned? Can we replicate ModernBERT's results with an older model like RoBERTa or peer model like GTE-en-MLM?
No. And it's not close.
No. And it's not close.
When we finetune ModernBERT-Large-Instruct on task specific datasets, the generative MLM head is better or nearly equal to standard classification heads.

February 10, 2025 at 6:13 PM
When we finetune ModernBERT-Large-Instruct on task specific datasets, the generative MLM head is better or nearly equal to standard classification heads.
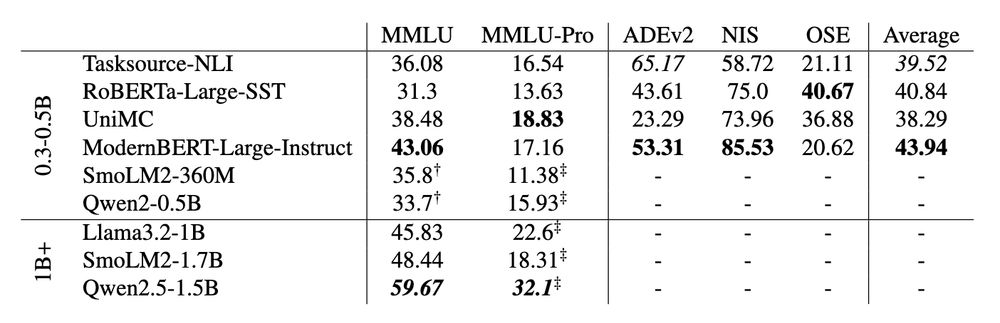
After instruction tuning on Flan, ModernBERT-Large-Instruct outperforms similarly sized LLMs on MMLU & MMLU-Pro, and achieves ~90 percent of Llama 3.2 1B's performance with ~65 percent fewer parameters.
February 10, 2025 at 6:13 PM
After instruction tuning on Flan, ModernBERT-Large-Instruct outperforms similarly sized LLMs on MMLU & MMLU-Pro, and achieves ~90 percent of Llama 3.2 1B's performance with ~65 percent fewer parameters.
One of the questions we debated while training ModernBERT was whether a modern trained encoder would unlock zero-shot reasoning using only it's generative head?
Spoilers: the answer is yes.
Spoilers: the answer is yes.
![from transformers import pipeline
model_name = "answerdotai/ModernBERT-Large-Instruct"
fill_mask = pipeline("fill-mask", model=model_name, tokenizer=model_name)
text = """You will be given a question and options. Select the right answer.
QUESTION: If (G, .) is a group such that (ab)^-1 = a^-1b^-1, for all a, b in G, then G is a/an
CHOICES:
- A: commutative semi group
- B: abelian group
- C: non-abelian group
- D: None of these
ANSWER: [unused0] [MASK]"""
results = fill_mask(text)
answer = results[0]["token_str"].strip()
print(f"Predicted answer: {answer}") # Answer: B](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:psfkl7gi24rg5rhvv7z6mly3/bafkreid6ko23ckgz2mwpp7zj3p6n333vmg5c2r5bghon77g4el6322z6oa@jpeg)
February 10, 2025 at 6:13 PM
One of the questions we debated while training ModernBERT was whether a modern trained encoder would unlock zero-shot reasoning using only it's generative head?
Spoilers: the answer is yes.
Spoilers: the answer is yes.
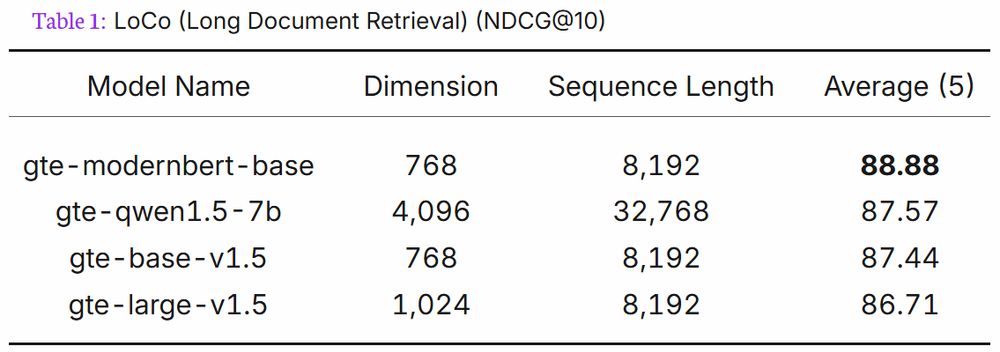
In addition to being the best retrieval model under 300M params on METB (without extra work), and top 10 for under 1B, here's a fun tidbit from Alibaba's GTE ModernBERT model card:
gte-modernbert-base beats gte-qwen1.5-7b on LoCo long context retrieval with 7B less parameters.
gte-modernbert-base beats gte-qwen1.5-7b on LoCo long context retrieval with 7B less parameters.
January 23, 2025 at 7:22 PM
In addition to being the best retrieval model under 300M params on METB (without extra work), and top 10 for under 1B, here's a fun tidbit from Alibaba's GTE ModernBERT model card:
gte-modernbert-base beats gte-qwen1.5-7b on LoCo long context retrieval with 7B less parameters.
gte-modernbert-base beats gte-qwen1.5-7b on LoCo long context retrieval with 7B less parameters.
ModernBERT is officially released on Transformers v4.48.0. You no longer need to install from git to use.
If you are plugging ModernBERT into an existing encoder finetuning pipeline, try increasing the learning rate. We've found that ModernBERT tends to prefer a higher LR than older models.
If you are plugging ModernBERT into an existing encoder finetuning pipeline, try increasing the learning rate. We've found that ModernBERT tends to prefer a higher LR than older models.
January 10, 2025 at 6:28 PM
ModernBERT is officially released on Transformers v4.48.0. You no longer need to install from git to use.
If you are plugging ModernBERT into an existing encoder finetuning pipeline, try increasing the learning rate. We've found that ModernBERT tends to prefer a higher LR than older models.
If you are plugging ModernBERT into an existing encoder finetuning pipeline, try increasing the learning rate. We've found that ModernBERT tends to prefer a higher LR than older models.
Second, we carefully designed ModernBERT's architecture run to efficiently across most common GPUs. Many common older models don't consider the hardware they will run on and are slower than they should be. Not so with ModernBERT.
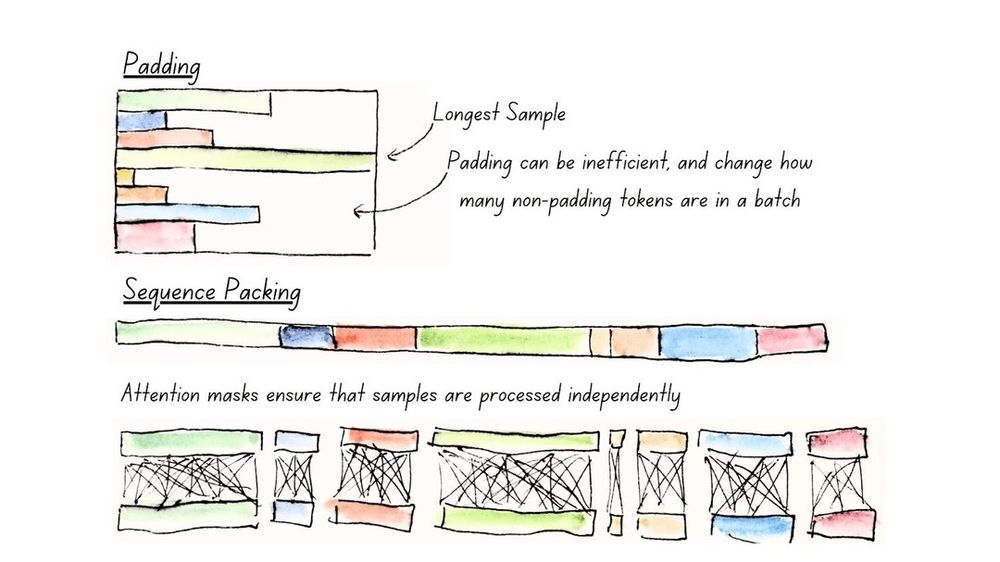
(Full model sequence packing illustrated below)
(Full model sequence packing illustrated below)
December 22, 2024 at 6:12 AM
Second, we carefully designed ModernBERT's architecture run to efficiently across most common GPUs. Many common older models don't consider the hardware they will run on and are slower than they should be. Not so with ModernBERT.
(Full model sequence packing illustrated below)
(Full model sequence packing illustrated below)
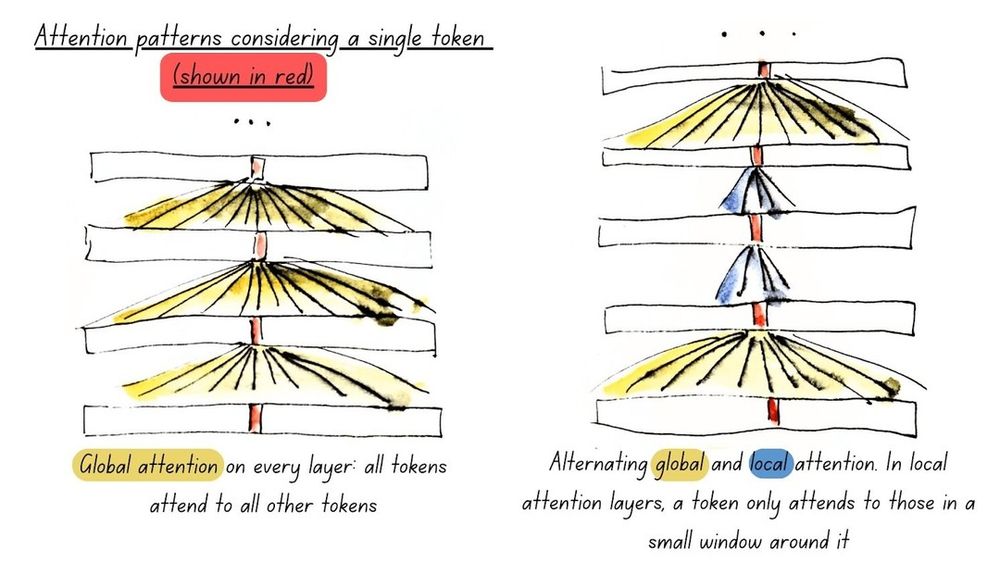
How did we do it? First, we brought all the modern LLM architectural improvements to encoders, including alternating global & local attention, RoPE, and GeGLU layers, and added full model unpadding using Flash Attention for maximum performance (illustrated in the next post).
December 22, 2024 at 6:12 AM
How did we do it? First, we brought all the modern LLM architectural improvements to encoders, including alternating global & local attention, RoPE, and GeGLU layers, and added full model unpadding using Flash Attention for maximum performance (illustrated in the next post).
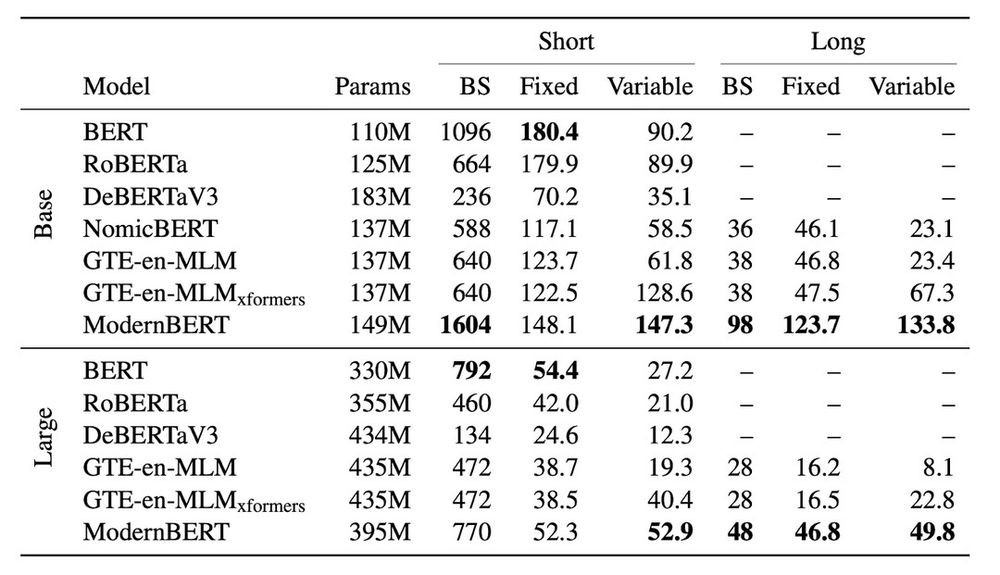
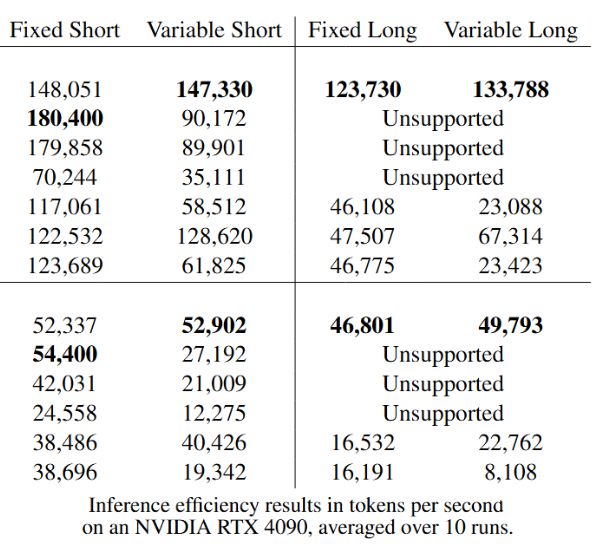
ModernBERT was designed from the ground up for speed and memory efficiency. ModernBERT is both faster and more memory efficient than every major encoder released since the original BERT.
December 22, 2024 at 6:12 AM
ModernBERT was designed from the ground up for speed and memory efficiency. ModernBERT is both faster and more memory efficient than every major encoder released since the original BERT.
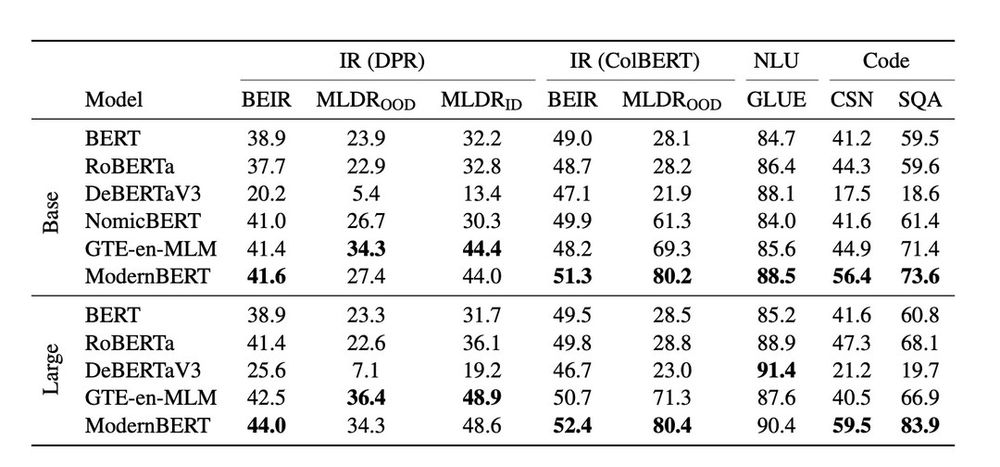
ModernBERT-base is the first encoder to beat DeBERTaV3-base on GLUE. ModernBERT is also competitive or top scoring on single vector retrieval, ColBERT retrieval, and programming benchmarks.
December 22, 2024 at 6:12 AM
ModernBERT-base is the first encoder to beat DeBERTaV3-base on GLUE. ModernBERT is also competitive or top scoring on single vector retrieval, ColBERT retrieval, and programming benchmarks.
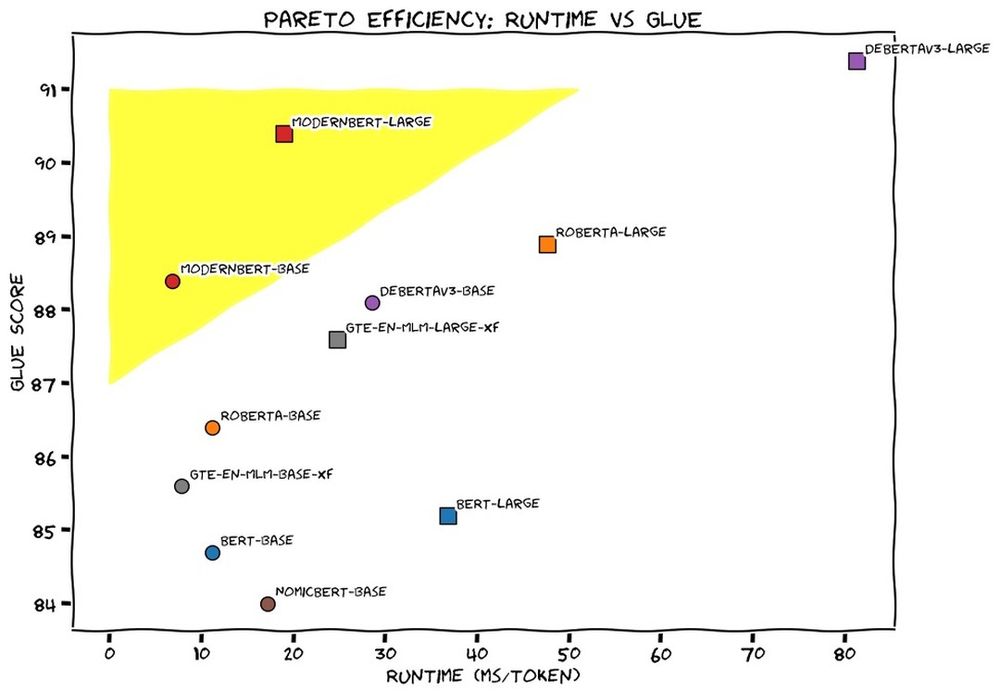
This week we released ModernBERT, the first encoder to reach SOTA on most common benchmarks across language understanding, retrieval, and code, while running twice as fast as DeBERTaV3 on short context and three times faster than NomicBERT & GTE on long context.
December 22, 2024 at 6:12 AM
This week we released ModernBERT, the first encoder to reach SOTA on most common benchmarks across language understanding, retrieval, and code, while running twice as fast as DeBERTaV3 on short context and three times faster than NomicBERT & GTE on long context.
I feel the need for speed.
December 13, 2024 at 9:56 PM
I feel the need for speed.