



Antoine Moulin
@antoine-mln.bsky.social
doing a phd in RL/online learning on questions related to exploration and adaptivity
> https://antoine-moulin.github.io/
> https://antoine-moulin.github.io/
Reposted by Antoine Moulin

Very excited to share our preprint: Self-Speculative Masked Diffusions
We speed up sampling of masked diffusion models by ~2x by using speculative sampling and a hybrid non-causal / causal transformer
arxiv.org/abs/2510.03929
w/ @vdebortoli.bsky.social, Jiaxin Shi, @arnauddoucet.bsky.social
We speed up sampling of masked diffusion models by ~2x by using speculative sampling and a hybrid non-causal / causal transformer
arxiv.org/abs/2510.03929
w/ @vdebortoli.bsky.social, Jiaxin Shi, @arnauddoucet.bsky.social

October 7, 2025 at 10:09 PM
Very excited to share our preprint: Self-Speculative Masked Diffusions
We speed up sampling of masked diffusion models by ~2x by using speculative sampling and a hybrid non-causal / causal transformer
arxiv.org/abs/2510.03929
w/ @vdebortoli.bsky.social, Jiaxin Shi, @arnauddoucet.bsky.social
We speed up sampling of masked diffusion models by ~2x by using speculative sampling and a hybrid non-causal / causal transformer
arxiv.org/abs/2510.03929
w/ @vdebortoli.bsky.social, Jiaxin Shi, @arnauddoucet.bsky.social
Reposted by Antoine Moulin

We're finally out of stealth: percepta.ai
We're a research / engineering team working together in industries like health and logistics to ship ML tools that drastically improve productivity. If you're interested in ML and RL work that matters, come join us 😀
We're a research / engineering team working together in industries like health and logistics to ship ML tools that drastically improve productivity. If you're interested in ML and RL work that matters, come join us 😀

Percepta | A General Catalyst Transformation Company
Transforming critical institutions using applied AI. Let's harness the frontier.
percepta.ai
October 2, 2025 at 3:35 PM
We're finally out of stealth: percepta.ai
We're a research / engineering team working together in industries like health and logistics to ship ML tools that drastically improve productivity. If you're interested in ML and RL work that matters, come join us 😀
We're a research / engineering team working together in industries like health and logistics to ship ML tools that drastically improve productivity. If you're interested in ML and RL work that matters, come join us 😀
Reposted by Antoine Moulin

I am happy to share that our paper "Unsupervised Learning for Optimal Transport plan prediction between unbalanced graphs" was accepted at Neurips 2025 ! 🥳
Huge thanks to my co-authors @rflamary.bsky.social and Bertrand Thirion !
arxiv.org/abs/2506.12025
(1/5)
Huge thanks to my co-authors @rflamary.bsky.social and Bertrand Thirion !
arxiv.org/abs/2506.12025
(1/5)

Unsupervised Learning for Optimal Transport plan prediction between unbalanced graphs
Optimal transport between graphs, based on Gromov-Wasserstein and other extensions, is a powerful tool for comparing and aligning graph structures. However, solving the associated non-convex optimizat...
arxiv.org
September 29, 2025 at 8:55 AM
I am happy to share that our paper "Unsupervised Learning for Optimal Transport plan prediction between unbalanced graphs" was accepted at Neurips 2025 ! 🥳
Huge thanks to my co-authors @rflamary.bsky.social and Bertrand Thirion !
arxiv.org/abs/2506.12025
(1/5)
Huge thanks to my co-authors @rflamary.bsky.social and Bertrand Thirion !
arxiv.org/abs/2506.12025
(1/5)
Reposted by Antoine Moulin

News 🎉 We’re thrilled to announce our final panelist: David Silver!
Don’t miss David and our amazing lineup of speakers—submit your latest RL work to our NeurIPS workshop.
📅 Extended deadline: Sept 2 (AoE)
Don’t miss David and our amazing lineup of speakers—submit your latest RL work to our NeurIPS workshop.
📅 Extended deadline: Sept 2 (AoE)

August 28, 2025 at 7:55 PM
News 🎉 We’re thrilled to announce our final panelist: David Silver!
Don’t miss David and our amazing lineup of speakers—submit your latest RL work to our NeurIPS workshop.
📅 Extended deadline: Sept 2 (AoE)
Don’t miss David and our amazing lineup of speakers—submit your latest RL work to our NeurIPS workshop.
📅 Extended deadline: Sept 2 (AoE)
Reposted by Antoine Moulin
We've extended the deadline for our workshop's calls for papers/ideas! Submit your work by August 29 AoE. Instructions on the website: arlet-workshop.github.io/neurips2025/...
Call for Papers | ARLET
A simple, whitespace theme for academics. Based on [*folio](https://github.com/bogoli/-folio) design.
arlet-workshop.github.io
August 18, 2025 at 10:46 AM
We've extended the deadline for our workshop's calls for papers/ideas! Submit your work by August 29 AoE. Instructions on the website: arlet-workshop.github.io/neurips2025/...
Reposted by Antoine Moulin
The OpenReview link for our calls (for papers and ideas) is available, submit here: openreview.net/group?id=Neu...
We look forward to receiving your submissions!
We look forward to receiving your submissions!

August 5, 2025 at 3:03 PM
The OpenReview link for our calls (for papers and ideas) is available, submit here: openreview.net/group?id=Neu...
We look forward to receiving your submissions!
We look forward to receiving your submissions!
last year's edition was so much fun I'm really looking forward to this one!! join us in San Diego :))
Delighted to announce that the second edition of our workshop has been accepted as a #NeurIPS2025 workshop!
July 28, 2025 at 6:06 PM
last year's edition was so much fun I'm really looking forward to this one!! join us in San Diego :))
Reposted by Antoine Moulin

Join us for Nneka's presentation tomorrow! Last talk before the summer break.

June 9, 2025 at 5:43 PM
Join us for Nneka's presentation tomorrow! Last talk before the summer break.
Reposted by Antoine Moulin
Join us tomorrow for Dave's talk! He will present his recent work on randomised exploration, which received an outstanding paper award at ALT 2025 earlier this year.

June 2, 2025 at 2:55 PM
Join us tomorrow for Dave's talk! He will present his recent work on randomised exploration, which received an outstanding paper award at ALT 2025 earlier this year.
new preprint with the amazing @lviano.bsky.social and @neu-rips.bsky.social on offline imitation learning! learned a lot :)
when the expert is hard to represent but the environment is simple, estimating a Q-value rather than the expert directly may be beneficial. lots of open questions left though!
when the expert is hard to represent but the environment is simple, estimating a Q-value rather than the expert directly may be beneficial. lots of open questions left though!


May 27, 2025 at 7:13 AM
new preprint with the amazing @lviano.bsky.social and @neu-rips.bsky.social on offline imitation learning! learned a lot :)
when the expert is hard to represent but the environment is simple, estimating a Q-value rather than the expert directly may be beneficial. lots of open questions left though!
when the expert is hard to represent but the environment is simple, estimating a Q-value rather than the expert directly may be beneficial. lots of open questions left though!
Reposted by Antoine Moulin

🚨 New paper accepted at SIMODS! 🚨
“Nonlinear Meta-learning Can Guarantee Faster Rates”
arxiv.org/abs/2307.10870
When does meta learning work? Spoiler: generalise to new tasks by overfitting on your training tasks!
Here is why:
🧵👇
“Nonlinear Meta-learning Can Guarantee Faster Rates”
arxiv.org/abs/2307.10870
When does meta learning work? Spoiler: generalise to new tasks by overfitting on your training tasks!
Here is why:
🧵👇

Nonlinear Meta-Learning Can Guarantee Faster Rates
Many recent theoretical works on \emph{meta-learning} aim to achieve guarantees in leveraging similar representational structures from related tasks towards simplifying a target task. The main aim of ...
arxiv.org
May 26, 2025 at 4:50 PM
🚨 New paper accepted at SIMODS! 🚨
“Nonlinear Meta-learning Can Guarantee Faster Rates”
arxiv.org/abs/2307.10870
When does meta learning work? Spoiler: generalise to new tasks by overfitting on your training tasks!
Here is why:
🧵👇
“Nonlinear Meta-learning Can Guarantee Faster Rates”
arxiv.org/abs/2307.10870
When does meta learning work? Spoiler: generalise to new tasks by overfitting on your training tasks!
Here is why:
🧵👇
Reposted by Antoine Moulin

Dhruv Rohatgi will be giving a lecture on our recent work on comp-stat tradeoffs in next-token prediction at the RL Theory virtual seminar series (rl-theory.bsky.social) tomorrow at 2pm EST! Should be a fun talk---come check it out!!

May 26, 2025 at 7:19 PM
Dhruv Rohatgi will be giving a lecture on our recent work on comp-stat tradeoffs in next-token prediction at the RL Theory virtual seminar series (rl-theory.bsky.social) tomorrow at 2pm EST! Should be a fun talk---come check it out!!
Reposted by Antoine Moulin

new work on computing distances between stochastic processes ***based on sample paths only***! we can now:
- learn distances between Markov chains
- extract "encoder-decoder" pairs for representation learning
- with sample- and computational-complexity guarantees
read on for some quick details..
1/n
- learn distances between Markov chains
- extract "encoder-decoder" pairs for representation learning
- with sample- and computational-complexity guarantees
read on for some quick details..
1/n
May 26, 2025 at 1:27 PM
new work on computing distances between stochastic processes ***based on sample paths only***! we can now:
- learn distances between Markov chains
- extract "encoder-decoder" pairs for representation learning
- with sample- and computational-complexity guarantees
read on for some quick details..
1/n
- learn distances between Markov chains
- extract "encoder-decoder" pairs for representation learning
- with sample- and computational-complexity guarantees
read on for some quick details..
1/n
Reposted by Antoine Moulin

A new blog post with intuitions behind continuous-time Markov chains, a building block of diffusion language models, like @inceptionlabs.bsky.social's Mercury and Gemini Diffusion. This post touches on different ways of looking at Markov chains, connections to point processes, and more.

Discrete Diffusion: Continuous-Time Markov Chains
A tutorial explaining some key intuitions behind continuous time Markov chains for machine learners interested in discrete diffusion models: alternative representations, connections to point processes...
www.inference.vc
May 22, 2025 at 3:14 PM
A new blog post with intuitions behind continuous-time Markov chains, a building block of diffusion language models, like @inceptionlabs.bsky.social's Mercury and Gemini Diffusion. This post touches on different ways of looking at Markov chains, connections to point processes, and more.
Reposted by Antoine Moulin

Mattes Mollenhauer, Nicole M\"ucke, Dimitri Meunier, Arthur Gretton: Regularized least squares learning with heavy-tailed noise is minimax optimal https://arxiv.org/abs/2505.14214 https://arxiv.org/pdf/2505.14214 https://arxiv.org/html/2505.14214
May 21, 2025 at 6:14 AM
Mattes Mollenhauer, Nicole M\"ucke, Dimitri Meunier, Arthur Gretton: Regularized least squares learning with heavy-tailed noise is minimax optimal https://arxiv.org/abs/2505.14214 https://arxiv.org/pdf/2505.14214 https://arxiv.org/html/2505.14214
Reposted by Antoine Moulin
Later today, Sikata and Marcel will talk about their recent work on oracle-efficient RL with ensembles. Join us!

May 20, 2025 at 3:48 PM
Later today, Sikata and Marcel will talk about their recent work on oracle-efficient RL with ensembles. Join us!
Reposted by Antoine Moulin

Excited to share what I've been up to: bringing text diffusion to Gemini!
Diffusion models are _fast_, and hold immense promise to challenge autoregressive models as the de facto standard for language modeling.
Diffusion models are _fast_, and hold immense promise to challenge autoregressive models as the de facto standard for language modeling.
May 20, 2025 at 6:52 PM
Excited to share what I've been up to: bringing text diffusion to Gemini!
Diffusion models are _fast_, and hold immense promise to challenge autoregressive models as the de facto standard for language modeling.
Diffusion models are _fast_, and hold immense promise to challenge autoregressive models as the de facto standard for language modeling.
Reposted by Antoine Moulin

The tutorials, workshops, and community events for #COLT2025 have been announced!
Exciting topics, and impressive slate of speakers and events, on June 30! The workshops have calls for contributions (⏰ May 16, 19, and 25): check them out!
learningtheory.org/colt2025/ind...
Exciting topics, and impressive slate of speakers and events, on June 30! The workshops have calls for contributions (⏰ May 16, 19, and 25): check them out!
learningtheory.org/colt2025/ind...


May 10, 2025 at 1:51 AM
The tutorials, workshops, and community events for #COLT2025 have been announced!
Exciting topics, and impressive slate of speakers and events, on June 30! The workshops have calls for contributions (⏰ May 16, 19, and 25): check them out!
learningtheory.org/colt2025/ind...
Exciting topics, and impressive slate of speakers and events, on June 30! The workshops have calls for contributions (⏰ May 16, 19, and 25): check them out!
learningtheory.org/colt2025/ind...
Reposted by Antoine Moulin
Announcing the first workshop on Foundations of Post-Training (FoPT) at COLT 2025!
📝 Soliciting abstracts/posters exploring theoretical & practical aspects of post-training and RL with language models!
🗓️ Deadline: May 19, 2025
📝 Soliciting abstracts/posters exploring theoretical & practical aspects of post-training and RL with language models!
🗓️ Deadline: May 19, 2025

May 9, 2025 at 5:10 PM
Announcing the first workshop on Foundations of Post-Training (FoPT) at COLT 2025!
📝 Soliciting abstracts/posters exploring theoretical & practical aspects of post-training and RL with language models!
🗓️ Deadline: May 19, 2025
📝 Soliciting abstracts/posters exploring theoretical & practical aspects of post-training and RL with language models!
🗓️ Deadline: May 19, 2025
Reposted by Antoine Moulin
looking forward to giving a talk at the 2025 GHOST day in the beautiful city of Poznan (Poland) --- hope to see you there this weekend!

May 6, 2025 at 7:06 PM
looking forward to giving a talk at the 2025 GHOST day in the beautiful city of Poznan (Poland) --- hope to see you there this weekend!
Reposted by Antoine Moulin
Is Best-of-N really the best we can do for language model inference?
New paper (appearing at ICML) led by the amazing Audrey Huang (ahahaudrey.bsky.social) with Adam Block, Qinghua Liu, Nan Jiang, and Akshay Krishnamurthy (akshaykr.bsky.social).
1/11
New paper (appearing at ICML) led by the amazing Audrey Huang (ahahaudrey.bsky.social) with Adam Block, Qinghua Liu, Nan Jiang, and Akshay Krishnamurthy (akshaykr.bsky.social).
1/11
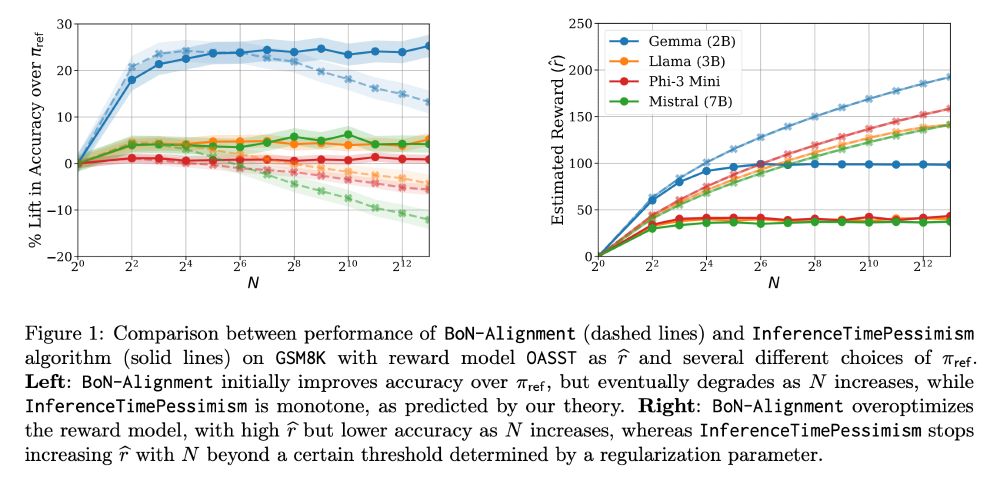

May 3, 2025 at 5:40 PM
Is Best-of-N really the best we can do for language model inference?
New paper (appearing at ICML) led by the amazing Audrey Huang (ahahaudrey.bsky.social) with Adam Block, Qinghua Liu, Nan Jiang, and Akshay Krishnamurthy (akshaykr.bsky.social).
1/11
New paper (appearing at ICML) led by the amazing Audrey Huang (ahahaudrey.bsky.social) with Adam Block, Qinghua Liu, Nan Jiang, and Akshay Krishnamurthy (akshaykr.bsky.social).
1/11
Reposted by Antoine Moulin
Spectral Representation for Causal Estimation with Hidden Confounders
at #AISTATS2025
A spectral method for causal effect estimation with hidden confounders, for instrumental variable and proxy causal learning
arxiv.org/abs/2407.10448
Haotian Sun, @antoine-mln.bsky.social, Tongzheng Ren, Bo Dai
at #AISTATS2025
A spectral method for causal effect estimation with hidden confounders, for instrumental variable and proxy causal learning
arxiv.org/abs/2407.10448
Haotian Sun, @antoine-mln.bsky.social, Tongzheng Ren, Bo Dai

May 2, 2025 at 12:36 PM
Spectral Representation for Causal Estimation with Hidden Confounders
at #AISTATS2025
A spectral method for causal effect estimation with hidden confounders, for instrumental variable and proxy causal learning
arxiv.org/abs/2407.10448
Haotian Sun, @antoine-mln.bsky.social, Tongzheng Ren, Bo Dai
at #AISTATS2025
A spectral method for causal effect estimation with hidden confounders, for instrumental variable and proxy causal learning
arxiv.org/abs/2407.10448
Haotian Sun, @antoine-mln.bsky.social, Tongzheng Ren, Bo Dai
Reposted by Antoine Moulin

We'll be presenting our work on Oracle-Efficient Reinforcement Learning for Max Value Ensembles at the RL theory seminar! Been following this series for a while, super excited we get to present some of our work. 🥳
Last seminars before the summer break:
04/29: Max Simchowitz (CMU)
05/06: Jeongyeol Kwon (Univ. of Widsconsin-Madison)
05/20: Sikata Sengupta & Marcel Hussing (Univ. of Pennsylvania)
05/27: Dhruv Rohatgi (MIT)
06/03: David Janz (Univ. of Oxford)
06/10: Nneka Okolo (MIT)
04/29: Max Simchowitz (CMU)
05/06: Jeongyeol Kwon (Univ. of Widsconsin-Madison)
05/20: Sikata Sengupta & Marcel Hussing (Univ. of Pennsylvania)
05/27: Dhruv Rohatgi (MIT)
06/03: David Janz (Univ. of Oxford)
06/10: Nneka Okolo (MIT)

April 25, 2025 at 2:22 PM
We'll be presenting our work on Oracle-Efficient Reinforcement Learning for Max Value Ensembles at the RL theory seminar! Been following this series for a while, super excited we get to present some of our work. 🥳
Reposted by Antoine Moulin
new paper online:
"CONFIDENCE SEQUENCES FOR GENERALIZED LINEAR MODELS VIA REGRET ANALYSIS"
TL;DR: we reduce the problem of designing tight confidence sets for statistical models to proving the existence of small regret bounds in an online prediction game
read on for a quick thread 👀👀👀
1/
"CONFIDENCE SEQUENCES FOR GENERALIZED LINEAR MODELS VIA REGRET ANALYSIS"
TL;DR: we reduce the problem of designing tight confidence sets for statistical models to proving the existence of small regret bounds in an online prediction game
read on for a quick thread 👀👀👀
1/

April 23, 2025 at 10:41 PM
new paper online:
"CONFIDENCE SEQUENCES FOR GENERALIZED LINEAR MODELS VIA REGRET ANALYSIS"
TL;DR: we reduce the problem of designing tight confidence sets for statistical models to proving the existence of small regret bounds in an online prediction game
read on for a quick thread 👀👀👀
1/
"CONFIDENCE SEQUENCES FOR GENERALIZED LINEAR MODELS VIA REGRET ANALYSIS"
TL;DR: we reduce the problem of designing tight confidence sets for statistical models to proving the existence of small regret bounds in an online prediction game
read on for a quick thread 👀👀👀
1/
Reposted by Antoine Moulin
Last seminars before the summer break:
04/29: Max Simchowitz (CMU)
05/06: Jeongyeol Kwon (Univ. of Widsconsin-Madison)
05/20: Sikata Sengupta & Marcel Hussing (Univ. of Pennsylvania)
05/27: Dhruv Rohatgi (MIT)
06/03: David Janz (Univ. of Oxford)
06/10: Nneka Okolo (MIT)
04/29: Max Simchowitz (CMU)
05/06: Jeongyeol Kwon (Univ. of Widsconsin-Madison)
05/20: Sikata Sengupta & Marcel Hussing (Univ. of Pennsylvania)
05/27: Dhruv Rohatgi (MIT)
06/03: David Janz (Univ. of Oxford)
06/10: Nneka Okolo (MIT)
April 16, 2025 at 5:20 PM
Last seminars before the summer break:
04/29: Max Simchowitz (CMU)
05/06: Jeongyeol Kwon (Univ. of Widsconsin-Madison)
05/20: Sikata Sengupta & Marcel Hussing (Univ. of Pennsylvania)
05/27: Dhruv Rohatgi (MIT)
06/03: David Janz (Univ. of Oxford)
06/10: Nneka Okolo (MIT)
04/29: Max Simchowitz (CMU)
05/06: Jeongyeol Kwon (Univ. of Widsconsin-Madison)
05/20: Sikata Sengupta & Marcel Hussing (Univ. of Pennsylvania)
05/27: Dhruv Rohatgi (MIT)
06/03: David Janz (Univ. of Oxford)
06/10: Nneka Okolo (MIT)