



Aakash Kumar Nain
@ak-nain.bsky.social
Sr. ML Engineer | Keras 3 Collaborator | @GoogleDevExpert in Machine Learning | @TensorFlow addons maintainer l ML is all I do | Views are my own!
Reposted by Aakash Kumar Nain

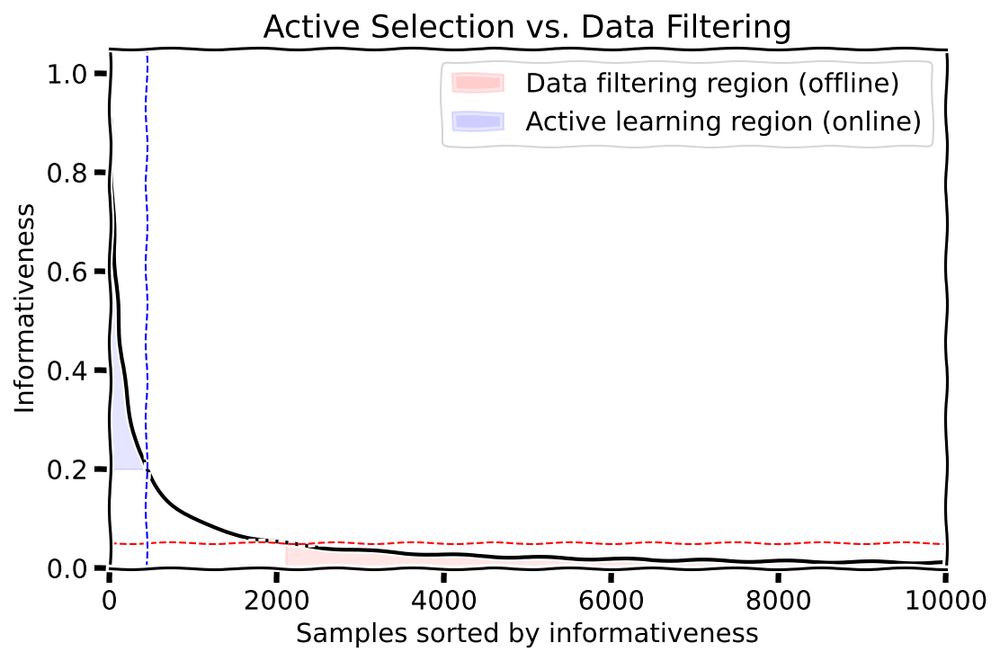
I want to share my latest (very short) blog post: "Active Learning vs. Data Filtering: Selection vs. Rejection."
What is the fundamental difference between active learning and data filtering?
Well, obviously, the difference is that:
1/11
What is the fundamental difference between active learning and data filtering?
Well, obviously, the difference is that:
1/11
May 17, 2025 at 11:47 AM
I want to share my latest (very short) blog post: "Active Learning vs. Data Filtering: Selection vs. Rejection."
What is the fundamental difference between active learning and data filtering?
Well, obviously, the difference is that:
1/11
What is the fundamental difference between active learning and data filtering?
Well, obviously, the difference is that:
1/11
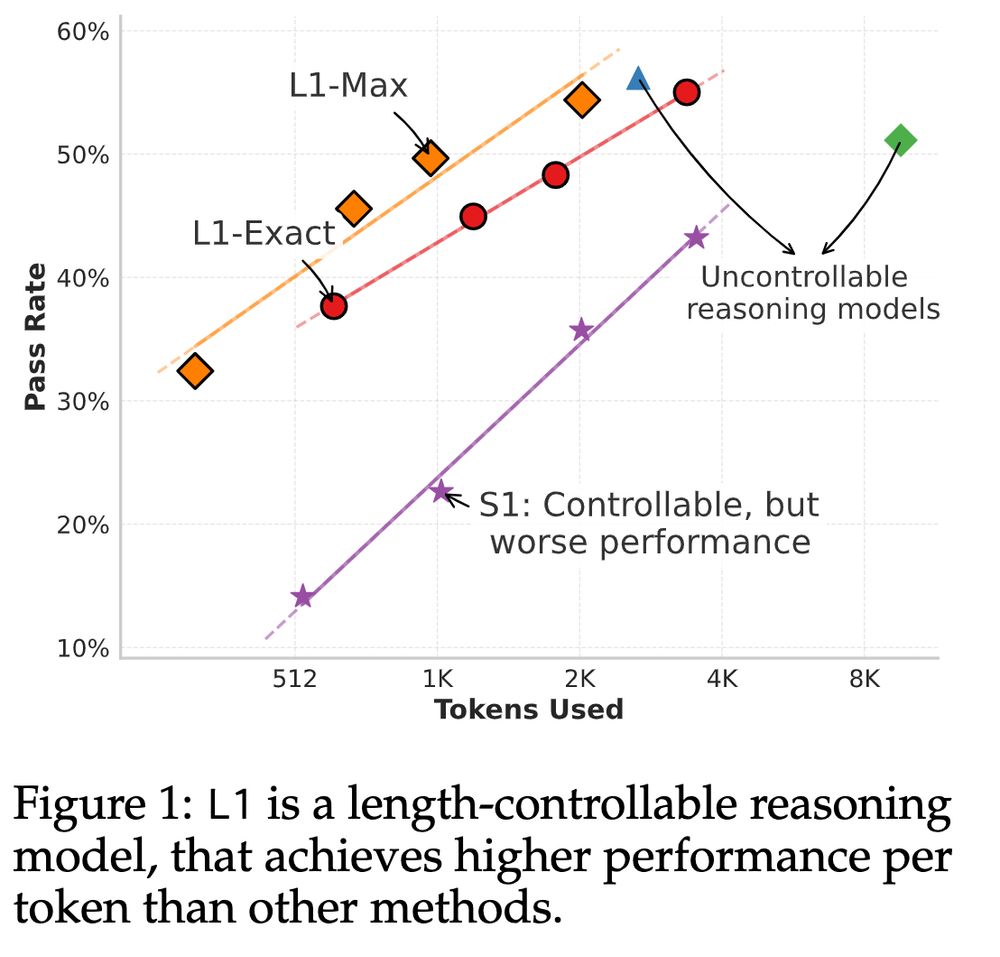
What if you want to control the length of CoT sequences? Can you put a budget constraint at test time for the reasoner models while maintaining performance? This latest paper from CMU addresses these two questions via RL. Here is a summary of LCPO in case you are interested:
March 10, 2025 at 1:51 AM
What if you want to control the length of CoT sequences? Can you put a budget constraint at test time for the reasoner models while maintaining performance? This latest paper from CMU addresses these two questions via RL. Here is a summary of LCPO in case you are interested:
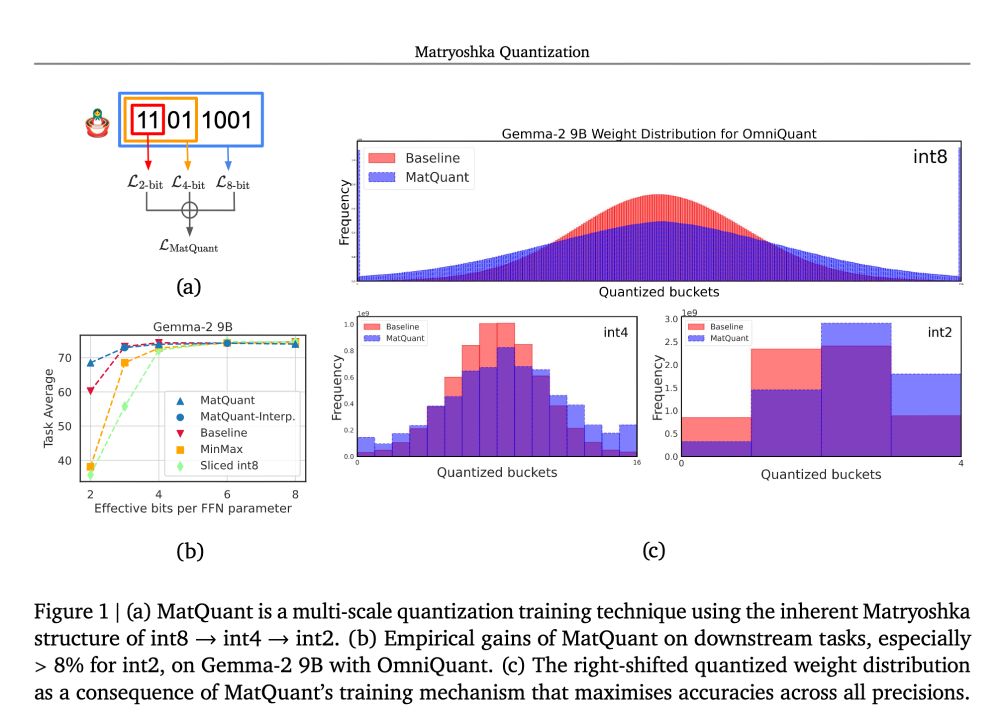
Matryoshka Quantization: Another fantastic paper from GDM! MatQuant came out last week. It was a very refreshing read. Here is a summary in case you are interested:
February 14, 2025 at 2:39 AM
Matryoshka Quantization: Another fantastic paper from GDM! MatQuant came out last week. It was a very refreshing read. Here is a summary in case you are interested:
1/3
Two years ago, we started a series on Diffusion Models that covered everything related to these models in-depth. We decided to write those tutorials covering intuition and the fundamentals because we could not find any high-quality diffusion tutorials then.
Two years ago, we started a series on Diffusion Models that covered everything related to these models in-depth. We decided to write those tutorials covering intuition and the fundamentals because we could not find any high-quality diffusion tutorials then.
February 12, 2025 at 2:40 AM
1/3
Two years ago, we started a series on Diffusion Models that covered everything related to these models in-depth. We decided to write those tutorials covering intuition and the fundamentals because we could not find any high-quality diffusion tutorials then.
Two years ago, we started a series on Diffusion Models that covered everything related to these models in-depth. We decided to write those tutorials covering intuition and the fundamentals because we could not find any high-quality diffusion tutorials then.
JanusPro is here, the next generation of the Janus model, with a few surprises (even for me!). I liked JanusFlow a lot, but the JanusPro 1B is what caught my eye. Here is a summary of the paper in case you are interested:

January 28, 2025 at 2:20 AM
JanusPro is here, the next generation of the Janus model, with a few surprises (even for me!). I liked JanusFlow a lot, but the JanusPro 1B is what caught my eye. Here is a summary of the paper in case you are interested:
I read the R1 paper last night, and here is a summary cum highlights from the paper (technical report to be more precise)

January 21, 2025 at 2:22 AM
I read the R1 paper last night, and here is a summary cum highlights from the paper (technical report to be more precise)
Everyone has heard enough about the scaling inference-time compute for LLMs in the past month. Diffusion models, on the other hand, have an innate flexibility for allocating varied compute at inference time. Here is a summary of how researchers at GDM exploit this property: 👇
January 20, 2025 at 3:53 AM
Everyone has heard enough about the scaling inference-time compute for LLMs in the past month. Diffusion models, on the other hand, have an innate flexibility for allocating varied compute at inference time. Here is a summary of how researchers at GDM exploit this property: 👇
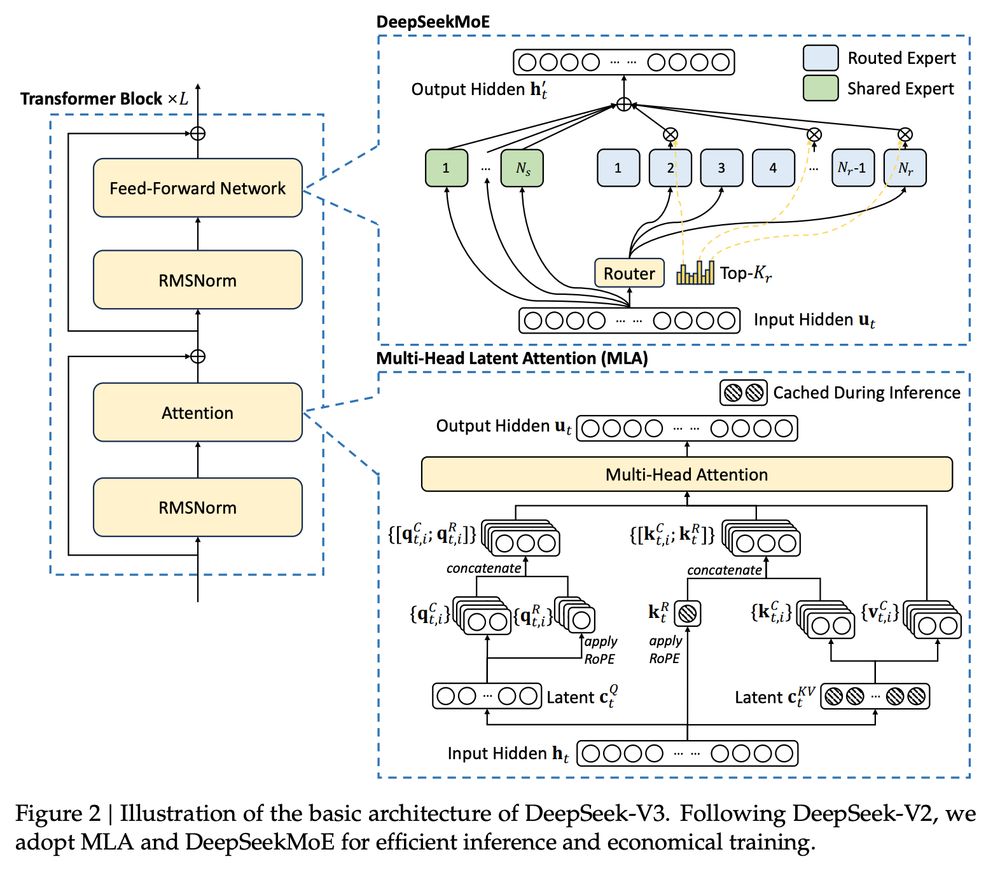
I just finished reading the DeepSeekv3 paper. Here is everything you need to know about it: 👇
x.com/A_K_Nain/sta...
x.com/A_K_Nain/sta...
December 27, 2024 at 1:14 PM
I just finished reading the DeepSeekv3 paper. Here is everything you need to know about it: 👇
x.com/A_K_Nain/sta...
x.com/A_K_Nain/sta...
I just finished reading one of the latest papers from Meta Research, MetaMorph. Except for two things (both not good), it is an okay paper, simple, concise, and to the point. Here is a quick summary in case you are interested:
x.com/A_K_Nain/sta...
x.com/A_K_Nain/sta...

December 20, 2024 at 11:34 AM
I just finished reading one of the latest papers from Meta Research, MetaMorph. Except for two things (both not good), it is an okay paper, simple, concise, and to the point. Here is a quick summary in case you are interested:
x.com/A_K_Nain/sta...
x.com/A_K_Nain/sta...
Reposted by Aakash Kumar Nain

Proud to see the release of Veo V2! deepmind.google/technologies...
"Veo has achieved state of the art results in head-to-head comparisons of outputs by human raters over top video generation models"
"Veo has achieved state of the art results in head-to-head comparisons of outputs by human raters over top video generation models"

Veo 2
Veo is our state-of-the-art video generation model. It creates high quality video clips that match the style and content of a user's prompts, in resolutions up to 4K resolution.
deepmind.google
December 16, 2024 at 5:15 PM
Proud to see the release of Veo V2! deepmind.google/technologies...
"Veo has achieved state of the art results in head-to-head comparisons of outputs by human raters over top video generation models"
"Veo has achieved state of the art results in head-to-head comparisons of outputs by human raters over top video generation models"
What if I tell you you can train a SOTA Gaze estimation model in 1 hour on an RTX4090 GPU? Too good to be true? I was also skeptical of that claim made in the Gaze-LLE paper, but it is true. DINOv2 FTW! I finished reading the paper, and here is a summary :
x.com/A_K_Nain/sta...
x.com/A_K_Nain/sta...
x.com
x.com
December 16, 2024 at 8:06 AM
What if I tell you you can train a SOTA Gaze estimation model in 1 hour on an RTX4090 GPU? Too good to be true? I was also skeptical of that claim made in the Gaze-LLE paper, but it is true. DINOv2 FTW! I finished reading the paper, and here is a summary :
x.com/A_K_Nain/sta...
x.com/A_K_Nain/sta...
Can you pre-train and fine-tune your VLMs in FP8? Can you get more than 2x efficiency with some simple tricks? Nvidia presents NVILA, an efficient frontier VLM that achieves all of the above. I finished reading the paper, and here is a summary in case you are interested:
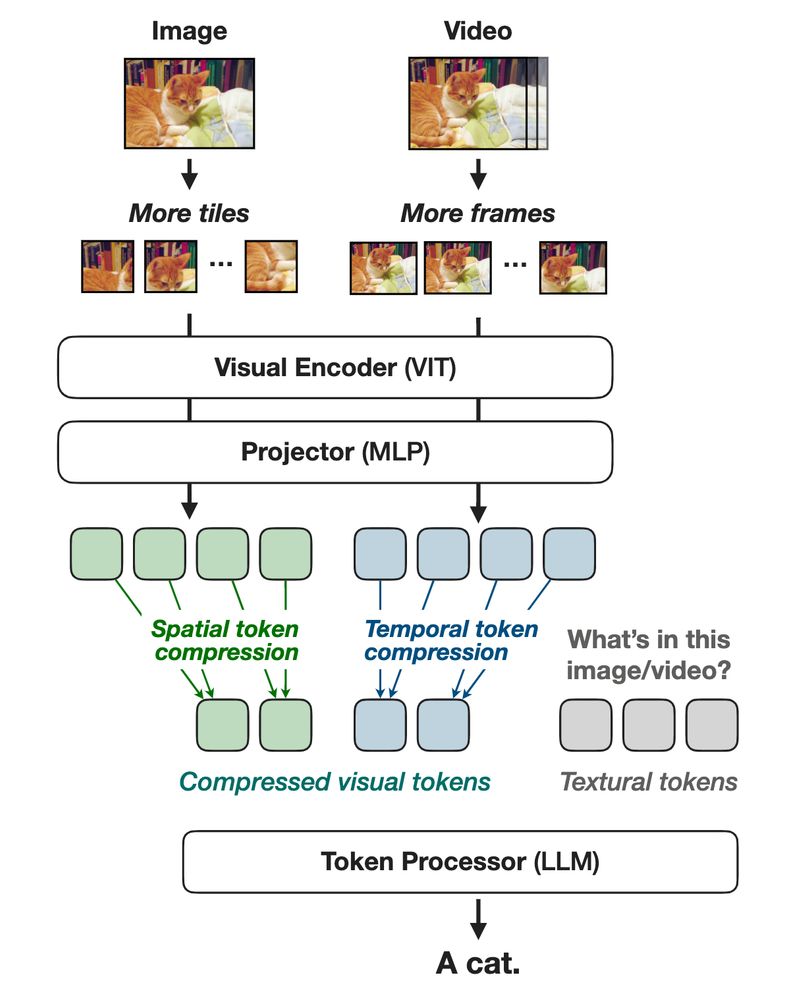
December 13, 2024 at 11:50 AM
Can you pre-train and fine-tune your VLMs in FP8? Can you get more than 2x efficiency with some simple tricks? Nvidia presents NVILA, an efficient frontier VLM that achieves all of the above. I finished reading the paper, and here is a summary in case you are interested:
I am back to writing math-heavy yet intuitive blog posts. Almost two years ago, I wrote the diffusion tutorials with a similar intention. This time, I am targeting the fundamental concepts of LLMs and MLLMs. And here is the first post in that direction: Rotary Position Encodings. Enjoy reading! 🍻

December 11, 2024 at 3:04 AM
I am back to writing math-heavy yet intuitive blog posts. Almost two years ago, I wrote the diffusion tutorials with a similar intention. This time, I am targeting the fundamental concepts of LLMs and MLLMs. And here is the first post in that direction: Rotary Position Encodings. Enjoy reading! 🍻
1/2
Google DeepMind announced PaliGemma 2 last week. It is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. What does this generation of PaliGemma bring to the table? I finished reading the technical report, and here is a summary:
Google DeepMind announced PaliGemma 2 last week. It is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. What does this generation of PaliGemma bring to the table? I finished reading the technical report, and here is a summary:

December 9, 2024 at 8:43 AM
1/2
Google DeepMind announced PaliGemma 2 last week. It is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. What does this generation of PaliGemma bring to the table? I finished reading the technical report, and here is a summary:
Google DeepMind announced PaliGemma 2 last week. It is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. What does this generation of PaliGemma bring to the table? I finished reading the technical report, and here is a summary:
Gemini 2.0 (if we are calling it 2.0 now) will be an interesting development. Why? It will be a good indicator of "Do we need test-time compute for now, or is there more left to juice out the transformers with some neat tricks?"
December 8, 2024 at 5:30 PM
Gemini 2.0 (if we are calling it 2.0 now) will be an interesting development. Why? It will be a good indicator of "Do we need test-time compute for now, or is there more left to juice out the transformers with some neat tricks?"
Though the TTT used by the winners in ARC Prize 2024 definitely gave a huge boost to the performance and is a promising direction, I personally feel that in a few years we would have a solid model that will do all the tricks in a single forward pass. And it won't be a LLM
December 7, 2024 at 4:48 PM
Though the TTT used by the winners in ARC Prize 2024 definitely gave a huge boost to the performance and is a promising direction, I personally feel that in a few years we would have a solid model that will do all the tricks in a single forward pass. And it won't be a LLM
Launch day! 💥💥
venturebeat.com/ai/emergence...
venturebeat.com/ai/emergence...

Emergence’s AI orchestrator launches to do what big tech offerings can’t: play well with others
It aims to sit above the fray and work well with any application and vendor that the enterprise uses, uniting them all with its orchestrator.
venturebeat.com
December 4, 2024 at 4:05 AM
Launch day! 💥💥
venturebeat.com/ai/emergence...
venturebeat.com/ai/emergence...
Nvidia presents Star Attention to improve LLM inference efficiency over long sequences. I was skeptical when I read the abstract the day it was published, but now that I have read the full paper, I think this is another good research
x.com/A_K_Nain/sta...
x.com/A_K_Nain/sta...
x.com
x.com
December 2, 2024 at 4:27 AM
Nvidia presents Star Attention to improve LLM inference efficiency over long sequences. I was skeptical when I read the abstract the day it was published, but now that I have read the full paper, I think this is another good research
x.com/A_K_Nain/sta...
x.com/A_K_Nain/sta...
Okay I like the idea of this app, but TBH this platform needs to step up to become what we need it to be. As of now:
1. Laggy
2. Half the time the tabs don't work
3. Feed is still broken
4. No bookmarks yet
5. Hyperlinks work randomly
1. Laggy
2. Half the time the tabs don't work
3. Feed is still broken
4. No bookmarks yet
5. Hyperlinks work randomly
November 27, 2024 at 10:26 AM
Okay I like the idea of this app, but TBH this platform needs to step up to become what we need it to be. As of now:
1. Laggy
2. Half the time the tabs don't work
3. Feed is still broken
4. No bookmarks yet
5. Hyperlinks work randomly
1. Laggy
2. Half the time the tabs don't work
3. Feed is still broken
4. No bookmarks yet
5. Hyperlinks work randomly
The multimodality space is now evolving in a much better way. The focus has shifted to finding the bottlenecks and fixing things on the fundamental level. This paper from **Apple** introduces **AIMv2**, and effort is in a similar direction, except that they only do it for the autoregressive models.

November 27, 2024 at 2:47 AM
The multimodality space is now evolving in a much better way. The focus has shifted to finding the bottlenecks and fixing things on the fundamental level. This paper from **Apple** introduces **AIMv2**, and effort is in a similar direction, except that they only do it for the autoregressive models.
Shameless plug but this is all you need to understand the fundamental of diffusion models:
magic-with-latents.github.io/latent/posts...
magic-with-latents.github.io/latent/posts...
The Latent: Code the Maths - A deep dive into DDPMs
magic-with-latents.github.io
November 26, 2024 at 4:13 AM
Shameless plug but this is all you need to understand the fundamental of diffusion models:
magic-with-latents.github.io/latent/posts...
magic-with-latents.github.io/latent/posts...
Generative World Explorer from John Hopkins University: an egocentric world exploration framework that allows an agent to mentally explore a large-scale 3D world
arxiv.org/abs/2411.11844
arxiv.org/abs/2411.11844

Generative World Explorer
Planning with partial observation is a central challenge in embodied AI. A majority of prior works have tackled this challenge by developing agents that physically explore their environment to update ...
arxiv.org
November 26, 2024 at 4:12 AM
Generative World Explorer from John Hopkins University: an egocentric world exploration framework that allows an agent to mentally explore a large-scale 3D world
arxiv.org/abs/2411.11844
arxiv.org/abs/2411.11844
Nvidia presents Hymba, another hybrid of attention and SSMs but for small family models:
arxiv.org/abs/2411.13676
arxiv.org/abs/2411.13676
Hymba: A Hybrid-head Architecture for Small Language Models
We propose Hymba, a family of small language models featuring a hybrid-head parallel architecture that integrates transformer attention mechanisms with state space models (SSMs) for enhanced efficienc...
arxiv.org
November 26, 2024 at 4:10 AM
Nvidia presents Hymba, another hybrid of attention and SSMs but for small family models:
arxiv.org/abs/2411.13676
arxiv.org/abs/2411.13676
Efficient long video tokenization
arxiv.org/abs/2411.14762
arxiv.org/abs/2411.14762
Efficient Long Video Tokenization via Coordinated-based Patch Reconstruction
Efficient tokenization of videos remains a challenge in training vision models that can process long videos. One promising direction is to develop a tokenizer that can encode long video clips, as it w...
arxiv.org
November 26, 2024 at 4:08 AM
Efficient long video tokenization
arxiv.org/abs/2411.14762
arxiv.org/abs/2411.14762
Ignoring the many missing features, the one thing that is a true delight on this app is to see your feed full of papers and ML discussions. 👌👌
November 25, 2024 at 4:31 PM
Ignoring the many missing features, the one thing that is a true delight on this app is to see your feed full of papers and ML discussions. 👌👌