



Aakash Kumar Nain
@ak-nain.bsky.social
Sr. ML Engineer | Keras 3 Collaborator | @GoogleDevExpert in Machine Learning | @TensorFlow addons maintainer l ML is all I do | Views are my own!
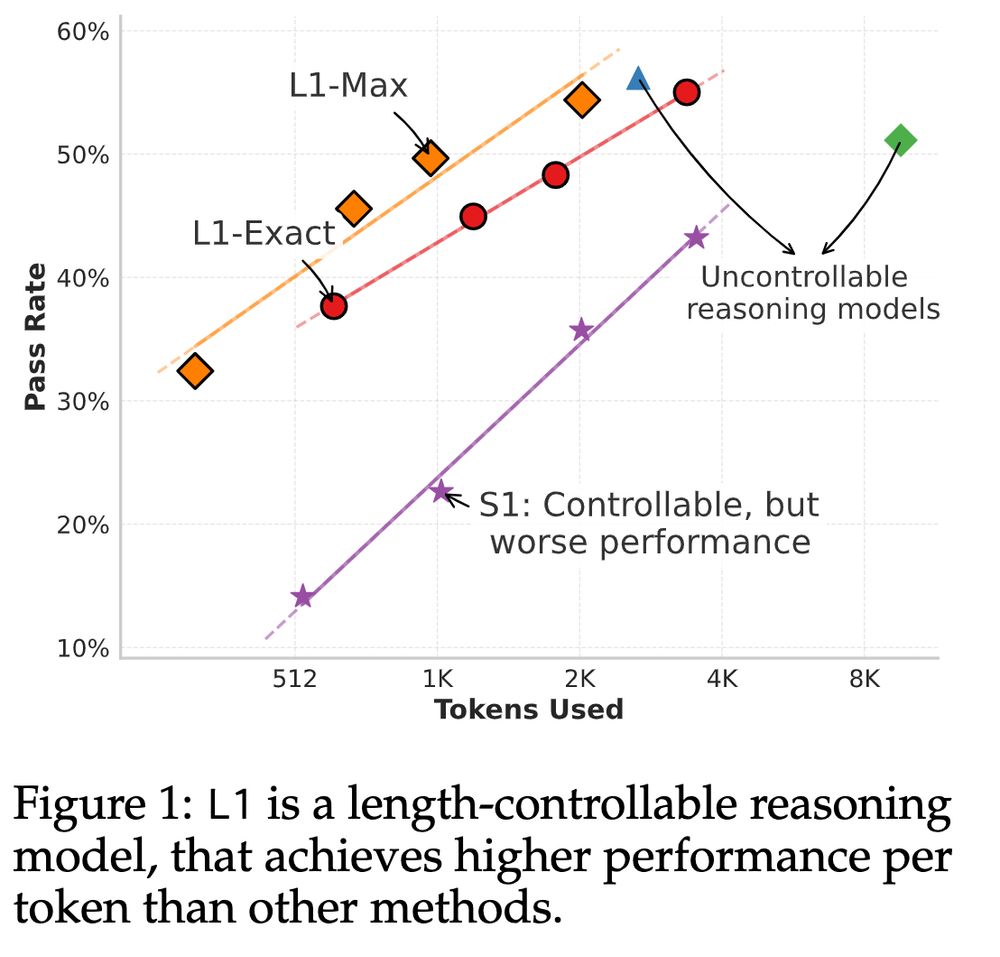
What if you want to control the length of CoT sequences? Can you put a budget constraint at test time for the reasoner models while maintaining performance? This latest paper from CMU addresses these two questions via RL. Here is a summary of LCPO in case you are interested:
March 10, 2025 at 1:51 AM
What if you want to control the length of CoT sequences? Can you put a budget constraint at test time for the reasoner models while maintaining performance? This latest paper from CMU addresses these two questions via RL. Here is a summary of LCPO in case you are interested:
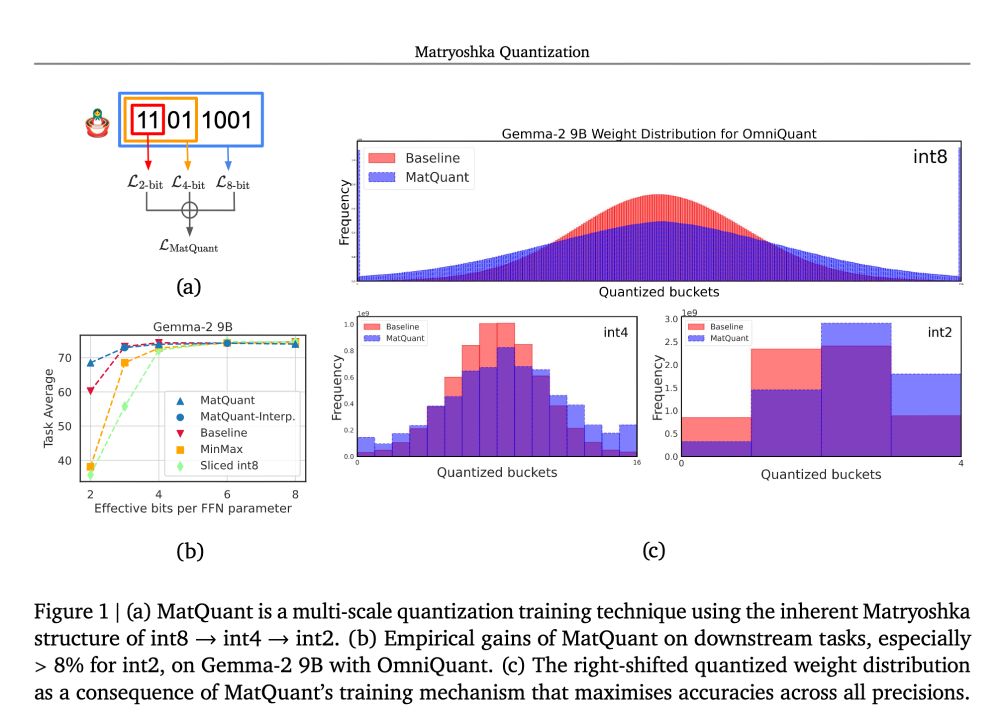
Matryoshka Quantization: Another fantastic paper from GDM! MatQuant came out last week. It was a very refreshing read. Here is a summary in case you are interested:
February 14, 2025 at 2:39 AM
Matryoshka Quantization: Another fantastic paper from GDM! MatQuant came out last week. It was a very refreshing read. Here is a summary in case you are interested:
JanusPro is here, the next generation of the Janus model, with a few surprises (even for me!). I liked JanusFlow a lot, but the JanusPro 1B is what caught my eye. Here is a summary of the paper in case you are interested:

January 28, 2025 at 2:20 AM
JanusPro is here, the next generation of the Janus model, with a few surprises (even for me!). I liked JanusFlow a lot, but the JanusPro 1B is what caught my eye. Here is a summary of the paper in case you are interested:
I read the R1 paper last night, and here is a summary cum highlights from the paper (technical report to be more precise)

January 21, 2025 at 2:22 AM
I read the R1 paper last night, and here is a summary cum highlights from the paper (technical report to be more precise)
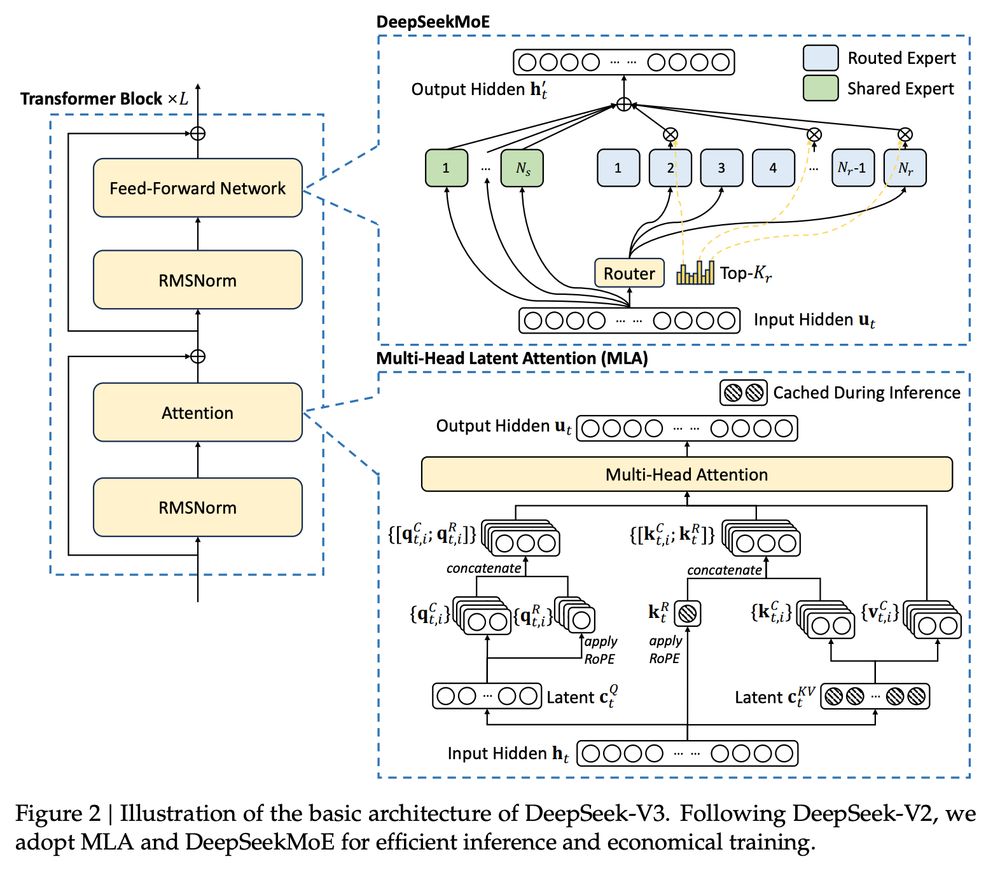
I just finished reading the DeepSeekv3 paper. Here is everything you need to know about it: 👇
x.com/A_K_Nain/sta...
x.com/A_K_Nain/sta...
December 27, 2024 at 1:14 PM
I just finished reading the DeepSeekv3 paper. Here is everything you need to know about it: 👇
x.com/A_K_Nain/sta...
x.com/A_K_Nain/sta...
I just finished reading one of the latest papers from Meta Research, MetaMorph. Except for two things (both not good), it is an okay paper, simple, concise, and to the point. Here is a quick summary in case you are interested:
x.com/A_K_Nain/sta...
x.com/A_K_Nain/sta...

December 20, 2024 at 11:34 AM
I just finished reading one of the latest papers from Meta Research, MetaMorph. Except for two things (both not good), it is an okay paper, simple, concise, and to the point. Here is a quick summary in case you are interested:
x.com/A_K_Nain/sta...
x.com/A_K_Nain/sta...
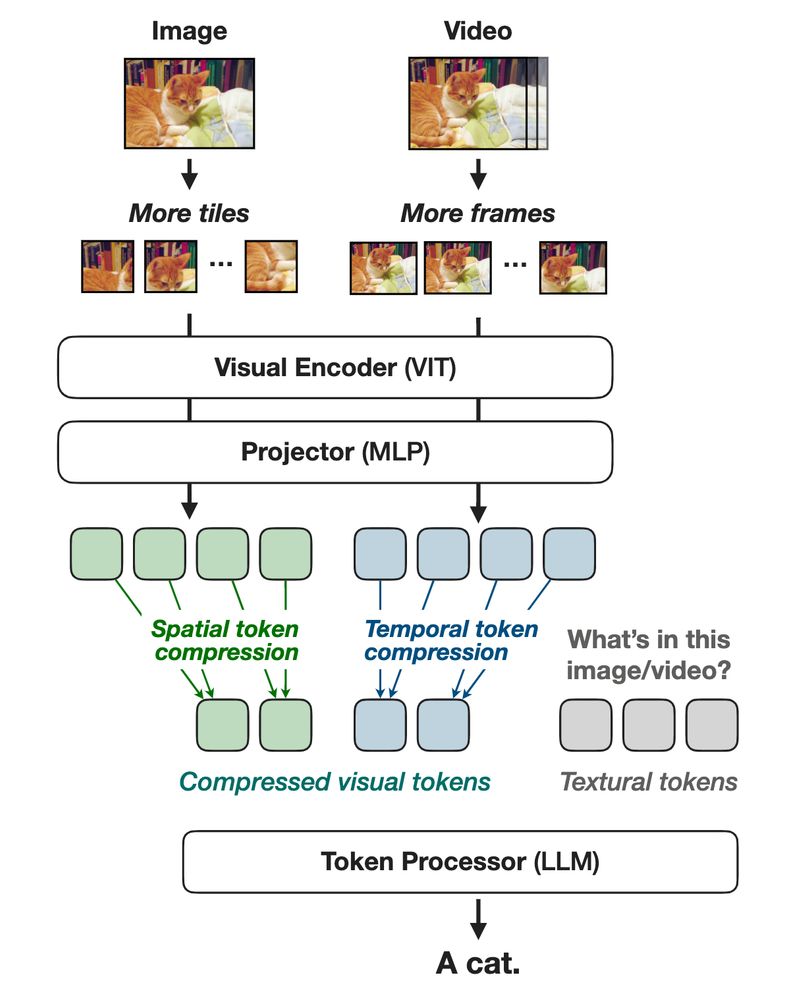
Can you pre-train and fine-tune your VLMs in FP8? Can you get more than 2x efficiency with some simple tricks? Nvidia presents NVILA, an efficient frontier VLM that achieves all of the above. I finished reading the paper, and here is a summary in case you are interested:
December 13, 2024 at 11:50 AM
Can you pre-train and fine-tune your VLMs in FP8? Can you get more than 2x efficiency with some simple tricks? Nvidia presents NVILA, an efficient frontier VLM that achieves all of the above. I finished reading the paper, and here is a summary in case you are interested:
I am back to writing math-heavy yet intuitive blog posts. Almost two years ago, I wrote the diffusion tutorials with a similar intention. This time, I am targeting the fundamental concepts of LLMs and MLLMs. And here is the first post in that direction: Rotary Position Encodings. Enjoy reading! 🍻

December 11, 2024 at 3:04 AM
I am back to writing math-heavy yet intuitive blog posts. Almost two years ago, I wrote the diffusion tutorials with a similar intention. This time, I am targeting the fundamental concepts of LLMs and MLLMs. And here is the first post in that direction: Rotary Position Encodings. Enjoy reading! 🍻
1/2
Google DeepMind announced PaliGemma 2 last week. It is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. What does this generation of PaliGemma bring to the table? I finished reading the technical report, and here is a summary:
Google DeepMind announced PaliGemma 2 last week. It is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. What does this generation of PaliGemma bring to the table? I finished reading the technical report, and here is a summary:

December 9, 2024 at 8:43 AM
1/2
Google DeepMind announced PaliGemma 2 last week. It is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. What does this generation of PaliGemma bring to the table? I finished reading the technical report, and here is a summary:
Google DeepMind announced PaliGemma 2 last week. It is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. What does this generation of PaliGemma bring to the table? I finished reading the technical report, and here is a summary:
The multimodality space is now evolving in a much better way. The focus has shifted to finding the bottlenecks and fixing things on the fundamental level. This paper from **Apple** introduces **AIMv2**, and effort is in a similar direction, except that they only do it for the autoregressive models.

November 27, 2024 at 2:47 AM
The multimodality space is now evolving in a much better way. The focus has shifted to finding the bottlenecks and fixing things on the fundamental level. This paper from **Apple** introduces **AIMv2**, and effort is in a similar direction, except that they only do it for the autoregressive models.
1/2
We all have been impressed by the quality of models produced by Deepseek. I thought Qwen was good, but the main highlight is JanusFlow. Apart from the MM1 paper from Apple, I believe JanusFlow is one of the best papers on modern MLLMs.
We all have been impressed by the quality of models produced by Deepseek. I thought Qwen was good, but the main highlight is JanusFlow. Apart from the MM1 paper from Apple, I believe JanusFlow is one of the best papers on modern MLLMs.

November 25, 2024 at 2:40 AM
1/2
We all have been impressed by the quality of models produced by Deepseek. I thought Qwen was good, but the main highlight is JanusFlow. Apart from the MM1 paper from Apple, I believe JanusFlow is one of the best papers on modern MLLMs.
We all have been impressed by the quality of models produced by Deepseek. I thought Qwen was good, but the main highlight is JanusFlow. Apart from the MM1 paper from Apple, I believe JanusFlow is one of the best papers on modern MLLMs.
Here is the forward-backward pass for log-sum-exp part

November 20, 2024 at 5:22 AM
Here is the forward-backward pass for log-sum-exp part
The backward pass can be merged with the backward pass of the log-sum-exp operation, which will be discussed shortly.

November 20, 2024 at 5:00 AM
The backward pass can be merged with the backward pass of the log-sum-exp operation, which will be discussed shortly.
Cross-entropy loss can be written as a combination of two terms, as shown below. The first term is a combination of an indexing operation and matrix multiplication. The second term is a joint log-sum-exp and matrix multiplication operation.

November 20, 2024 at 4:57 AM
Cross-entropy loss can be written as a combination of two terms, as shown below. The first term is a combination of an indexing operation and matrix multiplication. The second term is a joint log-sum-exp and matrix multiplication operation.