




Will Smith
@willsmithvision.bsky.social
Professor in Computer Vision at the University of York, vision/graphics/ML research, Boro @mfc.co.uk fan and climber
📍York, UK
🔗 https://www-users.york.ac.uk/~waps101/
📍York, UK
🔗 https://www-users.york.ac.uk/~waps101/
Has anyone ever tried a very non-standard tone for a rebuttal? I'm thinking something like "Hey reviewers! Sit back, relax and let me convince you that you actually want to accept this paper..." or "You wouldn't let a little thing like that stop you accepting the paper would you? WOULD YOU?!!!"
May 11, 2025 at 9:56 AM
Has anyone ever tried a very non-standard tone for a rebuttal? I'm thinking something like "Hey reviewers! Sit back, relax and let me convince you that you actually want to accept this paper..." or "You wouldn't let a little thing like that stop you accepting the paper would you? WOULD YOU?!!!"
So, we wrote a neural net library entirely in LaTeX...

April 1, 2025 at 12:30 PM
So, we wrote a neural net library entirely in LaTeX...
Reposted by Will Smith

I just pushed a new paper to arXiv. I realized that a lot of my previous work on robust losses and nerf-y things was dancing around something simpler: a slight tweak to the classic Box-Cox power transform that makes it much more useful and stable. It's this f(x, λ) here:
February 18, 2025 at 6:43 PM
I just pushed a new paper to arXiv. I realized that a lot of my previous work on robust losses and nerf-y things was dancing around something simpler: a slight tweak to the classic Box-Cox power transform that makes it much more useful and stable. It's this f(x, λ) here:
#CVPR2025 Area Chair update: depending on which time zone the review deadline is specified in, we are past or close to the review deadline. Of the 60 reviews needed for my batch, I currently have 52 and they have been coming in quite fast this morning. In general, review standard looks good.
January 14, 2025 at 8:09 AM
#CVPR2025 Area Chair update: depending on which time zone the review deadline is specified in, we are past or close to the review deadline. Of the 60 reviews needed for my batch, I currently have 52 and they have been coming in quite fast this morning. In general, review standard looks good.
Reposted by Will Smith

Image matching and ChatGPT - new post in the wide baseline stereo blog.
tl;dr: it is good, even feels like human, but not perfect.
ducha-aiki.github.io/wide-baselin...
tl;dr: it is good, even feels like human, but not perfect.
ducha-aiki.github.io/wide-baselin...
ChatGPT and Image Matching – Wide baseline stereo meets deep learning
Are we done yet?
ducha-aiki.github.io
January 2, 2025 at 9:01 PM
Image matching and ChatGPT - new post in the wide baseline stereo blog.
tl;dr: it is good, even feels like human, but not perfect.
ducha-aiki.github.io/wide-baselin...
tl;dr: it is good, even feels like human, but not perfect.
ducha-aiki.github.io/wide-baselin...
Reposted by Will Smith

This simple pytorch trick will cut in half your GPU memory use / double your batch size (for real). Instead of adding losses and then computing backward, it's better to compute the backward on each loss (which frees the computational graph). Results will be exactly identical

December 19, 2024 at 4:59 AM
This simple pytorch trick will cut in half your GPU memory use / double your batch size (for real). Instead of adding losses and then computing backward, it's better to compute the backward on each loss (which frees the computational graph). Results will be exactly identical
Me and my friend-since-before-school @ekd.bsky.social (a law academic) have written a blog post about the NotebookLM podcast generator in the style of, well, a corny podcast dialogue: slsablog.co.uk/blog/blog-po... 1/5

Turning scholarship into an "engaging" podcast using AI: interdisciplinary perspectives
by Dr Edward Kirton-Darling, Senior Lecturer at the University of Bristol Law School, and Professor Will Smith, Department for Computer Science, University of York,
Ed & Will in 1987 (or is it?)
...
slsablog.co.uk
December 18, 2024 at 12:20 PM
Me and my friend-since-before-school @ekd.bsky.social (a law academic) have written a blog post about the NotebookLM podcast generator in the style of, well, a corny podcast dialogue: slsablog.co.uk/blog/blog-po... 1/5
Reposted by Will Smith

Entropy is one of those formulas that many of us learn, swallow whole, and even use regularly without really understanding.
(E.g., where does that “log” come from? Are there other possible formulas?)
Yet there's an intuitive & almost inevitable way to arrive at this expression.
(E.g., where does that “log” come from? Are there other possible formulas?)
Yet there's an intuitive & almost inevitable way to arrive at this expression.
December 9, 2024 at 10:44 PM
Entropy is one of those formulas that many of us learn, swallow whole, and even use regularly without really understanding.
(E.g., where does that “log” come from? Are there other possible formulas?)
Yet there's an intuitive & almost inevitable way to arrive at this expression.
(E.g., where does that “log” come from? Are there other possible formulas?)
Yet there's an intuitive & almost inevitable way to arrive at this expression.
Reposted by Will Smith

"Sora is a data-driven physics engine."
x.com/chrisoffner3...
x.com/chrisoffner3...
December 10, 2024 at 12:42 PM
"Sora is a data-driven physics engine."
x.com/chrisoffner3...
x.com/chrisoffner3...
Reposted by Will Smith

Multistable Shape from Shading Emerges from Patch Diffusion #NeurIPS2024 Spotlight
X. Nicole Han, T. Zickler and K. Nishino (Harvard+Kyoto)
Diffusion-based SFS lets you sample multistable shape perception!
Nicole at poster on Th 12/12 11am East A-C 1308
vision.ist.i.kyoto-u.ac.jp/research/mss...
X. Nicole Han, T. Zickler and K. Nishino (Harvard+Kyoto)
Diffusion-based SFS lets you sample multistable shape perception!
Nicole at poster on Th 12/12 11am East A-C 1308
vision.ist.i.kyoto-u.ac.jp/research/mss...

December 10, 2024 at 8:13 AM
Multistable Shape from Shading Emerges from Patch Diffusion #NeurIPS2024 Spotlight
X. Nicole Han, T. Zickler and K. Nishino (Harvard+Kyoto)
Diffusion-based SFS lets you sample multistable shape perception!
Nicole at poster on Th 12/12 11am East A-C 1308
vision.ist.i.kyoto-u.ac.jp/research/mss...
X. Nicole Han, T. Zickler and K. Nishino (Harvard+Kyoto)
Diffusion-based SFS lets you sample multistable shape perception!
Nicole at poster on Th 12/12 11am East A-C 1308
vision.ist.i.kyoto-u.ac.jp/research/mss...
Reposted by Will Smith

To kick off using Bluesky: our new dataset called Oxford Spires. Synchronised, multi-color cameras and lidar in multiple Oxford colleges. Ground-Truth highly accurate 3D maps from tripod scanners. The ideal basis for NeRF/3DGS SLAM research.
dynamic.robots.ox.ac.uk/datasets/oxf...
dynamic.robots.ox.ac.uk/datasets/oxf...

December 9, 2024 at 10:29 AM
To kick off using Bluesky: our new dataset called Oxford Spires. Synchronised, multi-color cameras and lidar in multiple Oxford colleges. Ground-Truth highly accurate 3D maps from tripod scanners. The ideal basis for NeRF/3DGS SLAM research.
dynamic.robots.ox.ac.uk/datasets/oxf...
dynamic.robots.ox.ac.uk/datasets/oxf...
Reposted by Will Smith

Introducing MegaSaM!
Accurate, fast, & robust structure + camera estimation from casual monocular videos of dynamic scenes!
MegaSaM outputs camera parameters and consistent video depth, scaling to long videos with unconstrained camera paths and complex scene dynamics!
Accurate, fast, & robust structure + camera estimation from casual monocular videos of dynamic scenes!
MegaSaM outputs camera parameters and consistent video depth, scaling to long videos with unconstrained camera paths and complex scene dynamics!
December 6, 2024 at 5:43 PM
Introducing MegaSaM!
Accurate, fast, & robust structure + camera estimation from casual monocular videos of dynamic scenes!
MegaSaM outputs camera parameters and consistent video depth, scaling to long videos with unconstrained camera paths and complex scene dynamics!
Accurate, fast, & robust structure + camera estimation from casual monocular videos of dynamic scenes!
MegaSaM outputs camera parameters and consistent video depth, scaling to long videos with unconstrained camera paths and complex scene dynamics!
Reposted by Will Smith

OK If we are moving to Bluesky I am rescuing my favourite ever twitter thread (Jan 2019).
The renamed:
Bluesky-sized history of neuroscience (biased by my interests)
The renamed:
Bluesky-sized history of neuroscience (biased by my interests)
December 1, 2024 at 8:29 PM
OK If we are moving to Bluesky I am rescuing my favourite ever twitter thread (Jan 2019).
The renamed:
Bluesky-sized history of neuroscience (biased by my interests)
The renamed:
Bluesky-sized history of neuroscience (biased by my interests)
Reposted by Will Smith

Really cool new work out of Deep Mind for video game world generation using latent diffusion! Soon you'll be able to speed run a game just by tricking a model to morph you from one location to another.
deepmind.google/discover/blo...
deepmind.google/discover/blo...
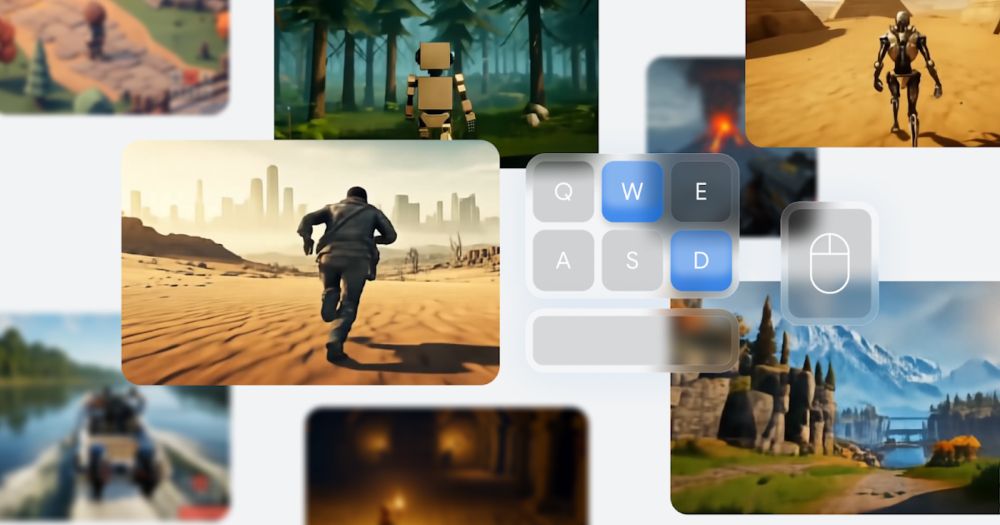
Genie 2: A large-scale foundation world model
Generating unlimited diverse training environments for future general agents
deepmind.google
December 4, 2024 at 4:31 PM
Really cool new work out of Deep Mind for video game world generation using latent diffusion! Soon you'll be able to speed run a game just by tricking a model to morph you from one location to another.
deepmind.google/discover/blo...
deepmind.google/discover/blo...
Reposted by Will Smith

How to drive your research forward?
“I tested the idea we discussed last time. Here are some results. It does not work. (… awkward silence)”
Such conversations happen so many times when meetings with students. How do we move forward?
You need …
“I tested the idea we discussed last time. Here are some results. It does not work. (… awkward silence)”
Such conversations happen so many times when meetings with students. How do we move forward?
You need …
December 1, 2024 at 10:09 PM
How to drive your research forward?
“I tested the idea we discussed last time. Here are some results. It does not work. (… awkward silence)”
Such conversations happen so many times when meetings with students. How do we move forward?
You need …
“I tested the idea we discussed last time. Here are some results. It does not work. (… awkward silence)”
Such conversations happen so many times when meetings with students. How do we move forward?
You need …
Reposted by Will Smith

For my first post on Bluesky, this recent talk I did at the recent BMVA one day meeting on World Models is a good summary of my work on Computer Vision, Robotics and SLAM, and my thoughts on a bigger picture of #SpatialAI.
youtu.be/NLnPG95vNhQ?...
youtu.be/NLnPG95vNhQ?...

1 Andrew Davison, Imperial College London - BMVA Symposium: Robotics Foundation & World Models
YouTube video by BMVA: British Machine Vision Association
youtu.be
November 28, 2024 at 2:22 PM
For my first post on Bluesky, this recent talk I did at the recent BMVA one day meeting on World Models is a good summary of my work on Computer Vision, Robotics and SLAM, and my thoughts on a bigger picture of #SpatialAI.
youtu.be/NLnPG95vNhQ?...
youtu.be/NLnPG95vNhQ?...
I am a first time Area Chair for #CVPR2025 so, in the interests of transparency, I'll post some updates here on the various stages of the process. There are 708 (!) ACs (not that long ago, CVPR could have coped with 708 *reviewers*!) We've been allocated 18.27 papers on average (I have 20).
November 28, 2024 at 9:27 AM
I am a first time Area Chair for #CVPR2025 so, in the interests of transparency, I'll post some updates here on the various stages of the process. There are 708 (!) ACs (not that long ago, CVPR could have coped with 708 *reviewers*!) We've been allocated 18.27 papers on average (I have 20).
Reposted by Will Smith

Hello Bluesky! 🔵 We start our account by having our third guess for Ask Me Anything session #3DV2025AMA!
Noah Snavely @snavely.bsky.social from Cornell & Google DeepMind! 🌟
🕒 You have now 24 HOURS to ask him anything — drop your questions in the comments below!
Keep it engaging but respectful!
Noah Snavely @snavely.bsky.social from Cornell & Google DeepMind! 🌟
🕒 You have now 24 HOURS to ask him anything — drop your questions in the comments below!
Keep it engaging but respectful!

November 26, 2024 at 3:33 PM
Hello Bluesky! 🔵 We start our account by having our third guess for Ask Me Anything session #3DV2025AMA!
Noah Snavely @snavely.bsky.social from Cornell & Google DeepMind! 🌟
🕒 You have now 24 HOURS to ask him anything — drop your questions in the comments below!
Keep it engaging but respectful!
Noah Snavely @snavely.bsky.social from Cornell & Google DeepMind! 🌟
🕒 You have now 24 HOURS to ask him anything — drop your questions in the comments below!
Keep it engaging but respectful!
Reposted by Will Smith
Introducing Generative Omnimatte:
A method for decomposing a video into complete layers, including objects and their associated effects (e.g., shadows, reflections).
It enables a wide range of cool applications, such as video stylization, compositions, moment retiming, and object removal.
A method for decomposing a video into complete layers, including objects and their associated effects (e.g., shadows, reflections).
It enables a wide range of cool applications, such as video stylization, compositions, moment retiming, and object removal.
November 26, 2024 at 3:55 PM
Introducing Generative Omnimatte:
A method for decomposing a video into complete layers, including objects and their associated effects (e.g., shadows, reflections).
It enables a wide range of cool applications, such as video stylization, compositions, moment retiming, and object removal.
A method for decomposing a video into complete layers, including objects and their associated effects (e.g., shadows, reflections).
It enables a wide range of cool applications, such as video stylization, compositions, moment retiming, and object removal.
Reposted by Will Smith

A real-time (or very fast) open-source txt2video model dropped: LTXV.
HF: huggingface.co/Lightricks/L...
Gradio: huggingface.co/spaces/Light...
Github: github.com/Lightricks/L...
Look at that prompt example though. Need to be a proper writer to get that quality.
HF: huggingface.co/Lightricks/L...
Gradio: huggingface.co/spaces/Light...
Github: github.com/Lightricks/L...
Look at that prompt example though. Need to be a proper writer to get that quality.


November 23, 2024 at 8:03 PM
A real-time (or very fast) open-source txt2video model dropped: LTXV.
HF: huggingface.co/Lightricks/L...
Gradio: huggingface.co/spaces/Light...
Github: github.com/Lightricks/L...
Look at that prompt example though. Need to be a proper writer to get that quality.
HF: huggingface.co/Lightricks/L...
Gradio: huggingface.co/spaces/Light...
Github: github.com/Lightricks/L...
Look at that prompt example though. Need to be a proper writer to get that quality.
Reposted by Will Smith
I used 📍🔗 emojis to maximize Twitter/Bluesky parity in my profile. This is definitely pointless, but it's fun.


November 22, 2024 at 4:44 PM
I used 📍🔗 emojis to maximize Twitter/Bluesky parity in my profile. This is definitely pointless, but it's fun.
Reposted by Will Smith

NeurIPS Conference is now Live on Bluesky!
-NeurIPS2024 Communication Chairs
-NeurIPS2024 Communication Chairs
November 22, 2024 at 1:33 AM
NeurIPS Conference is now Live on Bluesky!
-NeurIPS2024 Communication Chairs
-NeurIPS2024 Communication Chairs
Reposted by Will Smith

We've released our paper "Generating 3D-Consistent Videos from Unposed Internet Photos"! Video models like Luma generate pretty videos, but sometimes struggle with 3D consistency. We can do better by scaling them with 3D-aware objectives. 1/N
page: genechou.com/kfcw
page: genechou.com/kfcw
November 21, 2024 at 4:19 PM
We've released our paper "Generating 3D-Consistent Videos from Unposed Internet Photos"! Video models like Luma generate pretty videos, but sometimes struggle with 3D consistency. We can do better by scaling them with 3D-aware objectives. 1/N
page: genechou.com/kfcw
page: genechou.com/kfcw
Reposted by Will Smith

For those who missed this post on the-network-that-is-not-to-be-named, I made public my "secrets" for writing a good CVPR paper (or any scientific paper). I've compiled these tips of many years. It's long but hopefully it helps people write better papers. perceiving-systems.blog/en/post/writ...

Writing a good scientific paper
perceiving-systems.blog
November 20, 2024 at 10:18 AM
For those who missed this post on the-network-that-is-not-to-be-named, I made public my "secrets" for writing a good CVPR paper (or any scientific paper). I've compiled these tips of many years. It's long but hopefully it helps people write better papers. perceiving-systems.blog/en/post/writ...
As we approach the one year anniversary of a T-PAMI submission still waiting for first reviews, I imagine "With Associate Editor" to mean they sit in a lotus position atop a Himalayan peak, our paper and the reviews in their hand as they meditate (indefinitely) on what recommendation to make.
November 20, 2024 at 9:46 AM
As we approach the one year anniversary of a T-PAMI submission still waiting for first reviews, I imagine "With Associate Editor" to mean they sit in a lotus position atop a Himalayan peak, our paper and the reviews in their hand as they meditate (indefinitely) on what recommendation to make.