



Thibaut Loiseau
@thibautloiseau.bsky.social
PhD Student at IMAGINE (ENPC)
Working on camera pose estimation
thibautloiseau.github.io
Working on camera pose estimation
thibautloiseau.github.io
Pinned

1/13 🐊 Introducing our latest work on improving relative camera pose regression with a novel pre-training approach Alligat0R (arxiv.org/abs/2503.07561)!
@gbourmaud.bsky.social @vincentlepetit.bsky.social
@gbourmaud.bsky.social @vincentlepetit.bsky.social
Reposted by Thibaut Loiseau

🚀 DinoV3 just became the new go-to backbone for geoloc!
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.

August 18, 2025 at 3:14 PM
🚀 DinoV3 just became the new go-to backbone for geoloc!
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.



Reposted by Thibaut Loiseau

I am heartbroken that I am not at the conference, but seeing what the government is doing to its people and the world, I simply couldn't go there.
June 14, 2025 at 9:51 AM
I am heartbroken that I am not at the conference, but seeing what the government is doing to its people and the world, I simply couldn't go there.
Reposted by Thibaut Loiseau
This is an idea I've had for a while, but wow, it's working way better than expected! 🚀
The model looks really promising, even though it's just 256px for now.
The model looks really promising, even though it's just 256px for now.

April 24, 2025 at 12:40 PM
This is an idea I've had for a while, but wow, it's working way better than expected! 🚀
The model looks really promising, even though it's just 256px for now.
The model looks really promising, even though it's just 256px for now.
Reposted by Thibaut Loiseau

Introducing Chapter-Llama #CVPR2025, a framework for 𝐯𝐢𝐝𝐞𝐨 𝐜𝐡𝐚𝐩𝐭𝐞𝐫𝐢𝐧𝐠 using Large Language Models! 🎬🦙
Check it out:
📄 Paper: arxiv.org/abs/2504.00072
🔗 Project: imagine.enpc.fr/~lucas.ventu...
💻 Code: github.com/lucas-ventur...
🤗 Demo: huggingface.co/spaces/lucas...
Check it out:
📄 Paper: arxiv.org/abs/2504.00072
🔗 Project: imagine.enpc.fr/~lucas.ventu...
💻 Code: github.com/lucas-ventur...
🤗 Demo: huggingface.co/spaces/lucas...
April 4, 2025 at 3:56 PM
Introducing Chapter-Llama #CVPR2025, a framework for 𝐯𝐢𝐝𝐞𝐨 𝐜𝐡𝐚𝐩𝐭𝐞𝐫𝐢𝐧𝐠 using Large Language Models! 🎬🦙
Check it out:
📄 Paper: arxiv.org/abs/2504.00072
🔗 Project: imagine.enpc.fr/~lucas.ventu...
💻 Code: github.com/lucas-ventur...
🤗 Demo: huggingface.co/spaces/lucas...
Check it out:
📄 Paper: arxiv.org/abs/2504.00072
🔗 Project: imagine.enpc.fr/~lucas.ventu...
💻 Code: github.com/lucas-ventur...
🤗 Demo: huggingface.co/spaces/lucas...
Reposted by Thibaut Loiseau

🔥🔥🔥 CV Folks, I have some news! We're organizing a 1-day meeting in center Paris on June 6th before CVPR called CVPR@Paris (similar as NeurIPS@Paris) 🥐🍾🥖🍷
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!


March 21, 2025 at 6:43 AM
🔥🔥🔥 CV Folks, I have some news! We're organizing a 1-day meeting in center Paris on June 6th before CVPR called CVPR@Paris (similar as NeurIPS@Paris) 🥐🍾🥖🍷
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!
Reposted by Thibaut Loiseau

Starter pack including some of the lab members: go.bsky.app/QK8j87w
March 14, 2025 at 10:34 AM
Starter pack including some of the lab members: go.bsky.app/QK8j87w
Reposted by Thibaut Loiseau

Introducing DaD, Part 2, a pretty cool keypoint detector.
Introducing DaD (arxiv.org/abs/2503.07347), a pretty cool keypoint detector.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
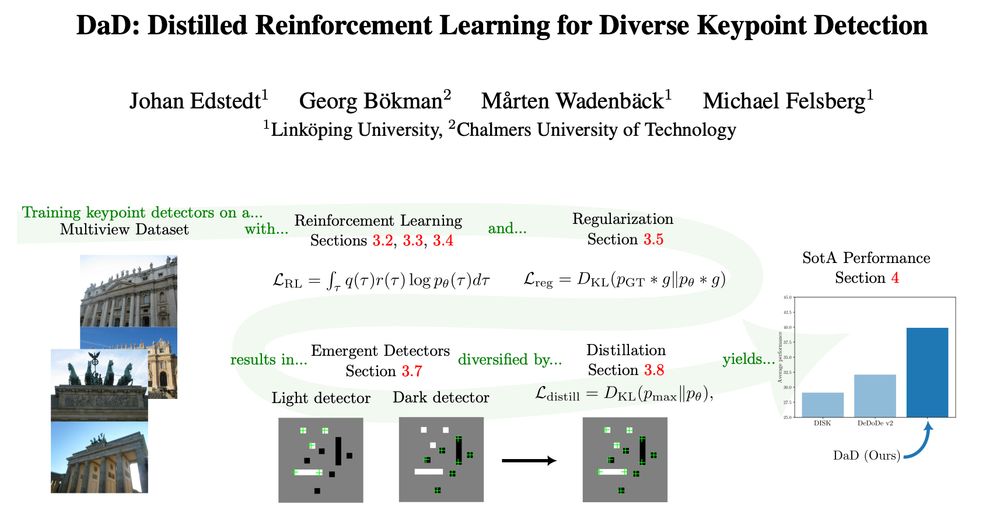
March 11, 2025 at 4:00 AM
Introducing DaD, Part 2, a pretty cool keypoint detector.
1/13 🐊 Introducing our latest work on improving relative camera pose regression with a novel pre-training approach Alligat0R (arxiv.org/abs/2503.07561)!
@gbourmaud.bsky.social @vincentlepetit.bsky.social
@gbourmaud.bsky.social @vincentlepetit.bsky.social
March 11, 2025 at 10:52 AM
1/13 🐊 Introducing our latest work on improving relative camera pose regression with a novel pre-training approach Alligat0R (arxiv.org/abs/2503.07561)!
@gbourmaud.bsky.social @vincentlepetit.bsky.social
@gbourmaud.bsky.social @vincentlepetit.bsky.social
Reposted by Thibaut Loiseau

Alligat0R: Pre-Training Through Co-Visibility Segmentation for Relative Camera Pose Regression
@thibautloiseau.bsky.social, Guillaume Bourmaud, @vincentlepetit.bsky.social
tl;dr: CroCo based; pixel in 1st image->co-visible or occluded or outside FOV in 2nd image
arxiv.org/abs/2503.07561
@thibautloiseau.bsky.social, Guillaume Bourmaud, @vincentlepetit.bsky.social
tl;dr: CroCo based; pixel in 1st image->co-visible or occluded or outside FOV in 2nd image
arxiv.org/abs/2503.07561




March 11, 2025 at 8:48 AM
Alligat0R: Pre-Training Through Co-Visibility Segmentation for Relative Camera Pose Regression
@thibautloiseau.bsky.social, Guillaume Bourmaud, @vincentlepetit.bsky.social
tl;dr: CroCo based; pixel in 1st image->co-visible or occluded or outside FOV in 2nd image
arxiv.org/abs/2503.07561
@thibautloiseau.bsky.social, Guillaume Bourmaud, @vincentlepetit.bsky.social
tl;dr: CroCo based; pixel in 1st image->co-visible or occluded or outside FOV in 2nd image
arxiv.org/abs/2503.07561
Reposted by Thibaut Loiseau

🚨 News! 🚨
We have released the models from our latest paper "How far can we go with ImageNet for text-to-image generation?"
Check out the models on HuggingFace:
🤗 huggingface.co/Lucasdegeorg...
📜 arxiv.org/abs/2502.21318
We have released the models from our latest paper "How far can we go with ImageNet for text-to-image generation?"
Check out the models on HuggingFace:
🤗 huggingface.co/Lucasdegeorg...
📜 arxiv.org/abs/2502.21318
March 5, 2025 at 11:52 AM
🚨 News! 🚨
We have released the models from our latest paper "How far can we go with ImageNet for text-to-image generation?"
Check out the models on HuggingFace:
🤗 huggingface.co/Lucasdegeorg...
📜 arxiv.org/abs/2502.21318
We have released the models from our latest paper "How far can we go with ImageNet for text-to-image generation?"
Check out the models on HuggingFace:
🤗 huggingface.co/Lucasdegeorg...
📜 arxiv.org/abs/2502.21318
Reposted by Thibaut Loiseau
Check out our latest work on Text-to-Image generation! We've successfully trained a T2I model using only ImageNet data by leveraging captioning and data augmentation.
🚨 New preprint!
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇

March 3, 2025 at 10:32 AM
Check out our latest work on Text-to-Image generation! We've successfully trained a T2I model using only ImageNet data by leveraging captioning and data augmentation.
Reposted by Thibaut Loiseau
🚨 New preprint!
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
March 3, 2025 at 10:19 AM
🚨 New preprint!
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
🧩 Excited to share our paper "RUBIK: A Structured Benchmark for Image Matching across Geometric Challenges" (arxiv.org/abs/2502.19955) accepted to #CVPR2025! We created a benchmark that systematically evaluates image matching methods across well-defined geometric difficulty levels. 🔍

February 28, 2025 at 3:23 PM
🧩 Excited to share our paper "RUBIK: A Structured Benchmark for Image Matching across Geometric Challenges" (arxiv.org/abs/2502.19955) accepted to #CVPR2025! We created a benchmark that systematically evaluates image matching methods across well-defined geometric difficulty levels. 🔍
Reposted by Thibaut Loiseau

🤔 What if embedding multimodal EO data was as easy as using a ResNet on images?
Introducing AnySat: one model for any resolution (0.2m–250m), scale (0.3–2600 hectares), and modalities (choose from 11 sensors & time series)!
Try it with just a few lines of code:
Introducing AnySat: one model for any resolution (0.2m–250m), scale (0.3–2600 hectares), and modalities (choose from 11 sensors & time series)!
Try it with just a few lines of code:

December 19, 2024 at 10:46 AM
🤔 What if embedding multimodal EO data was as easy as using a ResNet on images?
Introducing AnySat: one model for any resolution (0.2m–250m), scale (0.3–2600 hectares), and modalities (choose from 11 sensors & time series)!
Try it with just a few lines of code:
Introducing AnySat: one model for any resolution (0.2m–250m), scale (0.3–2600 hectares), and modalities (choose from 11 sensors & time series)!
Try it with just a few lines of code:
Reposted by Thibaut Loiseau
We @imagineenpc.bsky.social are slowly but surely entering our proposals for master's degree internships here: docs.google.com/document/d/1...
These are 6 months projects that typically correspond to the end-of-study project in the French curriculum.
Probably more offers to come, check it regularly.
These are 6 months projects that typically correspond to the end-of-study project in the French curriculum.
Probably more offers to come, check it regularly.

2025 IMAGINE Internships
2025 Internship proposals at IMAGINE IMAGINE is a top research group on computer vision and machine learning. It is part of the LIGM lab and hosted at École des Ponts ParisTech (ENPC), about 25 min f...
docs.google.com
December 12, 2024 at 10:08 AM
We @imagineenpc.bsky.social are slowly but surely entering our proposals for master's degree internships here: docs.google.com/document/d/1...
These are 6 months projects that typically correspond to the end-of-study project in the French curriculum.
Probably more offers to come, check it regularly.
These are 6 months projects that typically correspond to the end-of-study project in the French curriculum.
Probably more offers to come, check it regularly.