




Simone Scardapane
@sscardapane.bsky.social
I fall in love with a new #machinelearning topic every month 🙄
Ass. Prof. Sapienza (Rome) | Author: Alice in a differentiable wonderland (https://www.sscardapane.it/alice-book/)
Ass. Prof. Sapienza (Rome) | Author: Alice in a differentiable wonderland (https://www.sscardapane.it/alice-book/)
Pinned

Just landed here! 🔥 A nice news to start: *Alice in a differentiable wonderland* has gone over 1000 copies sold on Amazon and I am super happy about the feedback! If you happen to buy a copy feel free to drop a review and/or send me suggestions on the material: www.sscardapane.it/alice-book/
Reposted by Simone Scardapane

Thanks a lot to all my amazing co-authors @alessiodevoto.bsky.social @sscardapane.bsky.social @yuzhaouoe.bsky.social @neuralnoise.com Eric de la Clergerie @bensagot.bsky.social
And a special thanks to @edoardo-ponti.bsky.social for the academic visit that made this work possible!
And a special thanks to @edoardo-ponti.bsky.social for the academic visit that made this work possible!
March 6, 2025 at 4:02 PM
Thanks a lot to all my amazing co-authors @alessiodevoto.bsky.social @sscardapane.bsky.social @yuzhaouoe.bsky.social @neuralnoise.com Eric de la Clergerie @bensagot.bsky.social
And a special thanks to @edoardo-ponti.bsky.social for the academic visit that made this work possible!
And a special thanks to @edoardo-ponti.bsky.social for the academic visit that made this work possible!
Reposted by Simone Scardapane

Will present this at #CVPR ✈️ See you in Nashville 🇺🇸!
Kudos to the team 👏
Antonio A. Gargiulo, @mariasofiab.bsky.social, @sscardapane.bsky.social, Fabrizio Silvestri, Emanuele Rodolà.
Kudos to the team 👏
Antonio A. Gargiulo, @mariasofiab.bsky.social, @sscardapane.bsky.social, Fabrizio Silvestri, Emanuele Rodolà.
📢Prepend “Singular” to “Task Vectors” and get +15% average accuracy for free!
1. Perform a low-rank approximation of layer-wise task vectors.
2. Minimize task interference by orthogonalizing inter-task singular vectors.
🧵(1/6)
1. Perform a low-rank approximation of layer-wise task vectors.
2. Minimize task interference by orthogonalizing inter-task singular vectors.
🧵(1/6)
March 11, 2025 at 8:02 AM
Will present this at #CVPR ✈️ See you in Nashville 🇺🇸!
Kudos to the team 👏
Antonio A. Gargiulo, @mariasofiab.bsky.social, @sscardapane.bsky.social, Fabrizio Silvestri, Emanuele Rodolà.
Kudos to the team 👏
Antonio A. Gargiulo, @mariasofiab.bsky.social, @sscardapane.bsky.social, Fabrizio Silvestri, Emanuele Rodolà.
Reposted by Simone Scardapane

Please share it within your circles! edin.ac/3DDQK1o

March 13, 2025 at 11:59 AM
Please share it within your circles! edin.ac/3DDQK1o
Reposted by Simone Scardapane
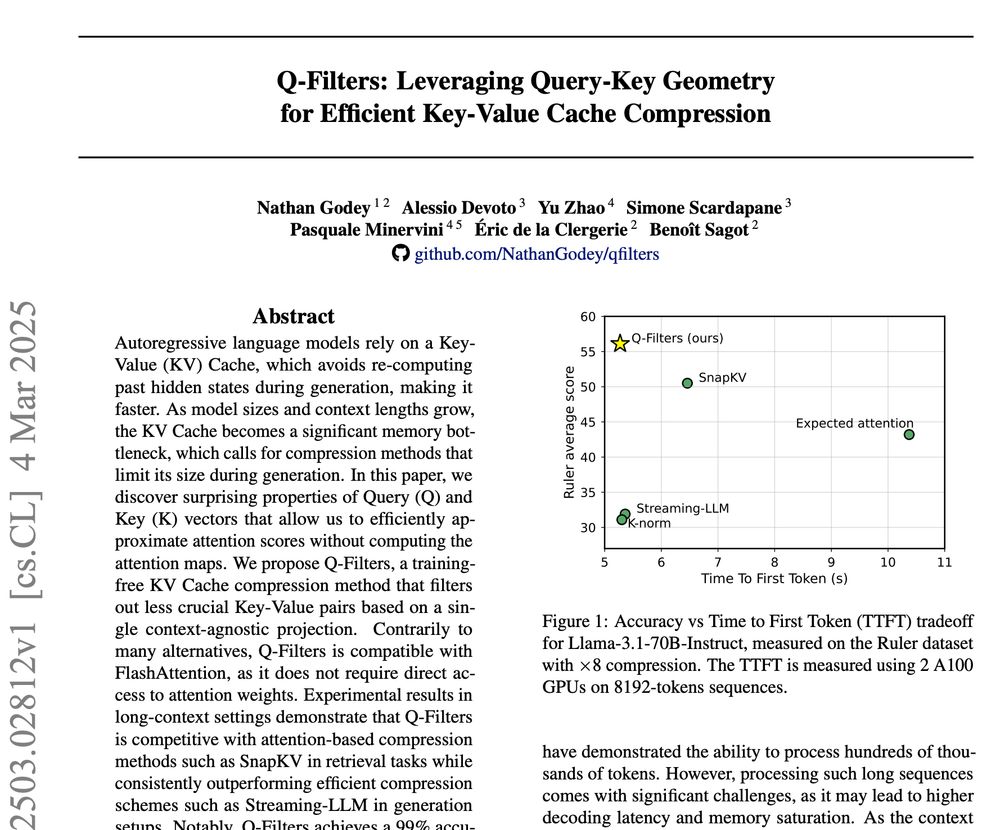
🚀 New Paper Alert! 🚀
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
March 6, 2025 at 4:02 PM
🚀 New Paper Alert! 🚀
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
Reposted by Simone Scardapane
Q-Filters is very efficient which allows streaming compression at virtually no latency cost, just like Streaming-LLM...
...but it is also much better at retaining relevant KV pairs compared to fast alternatives (and can even beat slower algorithms such as SnapKV)
...but it is also much better at retaining relevant KV pairs compared to fast alternatives (and can even beat slower algorithms such as SnapKV)

March 6, 2025 at 1:41 PM
Q-Filters is very efficient which allows streaming compression at virtually no latency cost, just like Streaming-LLM...
...but it is also much better at retaining relevant KV pairs compared to fast alternatives (and can even beat slower algorithms such as SnapKV)
...but it is also much better at retaining relevant KV pairs compared to fast alternatives (and can even beat slower algorithms such as SnapKV)
*Compositionality and Ambiguity: Latent Co-occurrence and Interpretable Subspaces*
by @maclarke.bsky.social et al.
Studies co-occurence of SAE features and how they can be understood as composite / ambiguous concepts.
www.lesswrong.com/posts/WNoqEi...
by @maclarke.bsky.social et al.
Studies co-occurence of SAE features and how they can be understood as composite / ambiguous concepts.
www.lesswrong.com/posts/WNoqEi...

Compositionality and Ambiguity:
Latent Co-occurrence and Interpretable Subspaces — LessWrong
Matthew A. Clarke, Hardik Bhatnagar and Joseph Bloom
www.lesswrong.com
February 27, 2025 at 8:33 AM
*Compositionality and Ambiguity: Latent Co-occurrence and Interpretable Subspaces*
by @maclarke.bsky.social et al.
Studies co-occurence of SAE features and how they can be understood as composite / ambiguous concepts.
www.lesswrong.com/posts/WNoqEi...
by @maclarke.bsky.social et al.
Studies co-occurence of SAE features and how they can be understood as composite / ambiguous concepts.
www.lesswrong.com/posts/WNoqEi...
*Weighted Skip Connections are Not Harmful for Deep Nets*
by @rupspace.bsky.social
Cool blog post "in defense" of weighted variants of ResNets (aka HighwayNets) - as a follow up to a previous post by @giffmana.ai.
rupeshks.cc/blog/skip.html
by @rupspace.bsky.social
Cool blog post "in defense" of weighted variants of ResNets (aka HighwayNets) - as a follow up to a previous post by @giffmana.ai.
rupeshks.cc/blog/skip.html

Weighted Skip Connections are Not Harmful for Deep Nets
Give Gates a Chance
rupeshks.cc
February 18, 2025 at 9:49 AM
*Weighted Skip Connections are Not Harmful for Deep Nets*
by @rupspace.bsky.social
Cool blog post "in defense" of weighted variants of ResNets (aka HighwayNets) - as a follow up to a previous post by @giffmana.ai.
rupeshks.cc/blog/skip.html
by @rupspace.bsky.social
Cool blog post "in defense" of weighted variants of ResNets (aka HighwayNets) - as a follow up to a previous post by @giffmana.ai.
rupeshks.cc/blog/skip.html
*CAT: Content-Adaptive Image Tokenization*
by @junhongshen1.bsky.social @lukezettlemoyer.bsky.social et al.
They use an LLM to predict a "complexity score" for each image token, which in turns decides the size of its VAE latent representation.
arxiv.org/abs/2501.03120
by @junhongshen1.bsky.social @lukezettlemoyer.bsky.social et al.
They use an LLM to predict a "complexity score" for each image token, which in turns decides the size of its VAE latent representation.
arxiv.org/abs/2501.03120

February 17, 2025 at 2:57 PM
*CAT: Content-Adaptive Image Tokenization*
by @junhongshen1.bsky.social @lukezettlemoyer.bsky.social et al.
They use an LLM to predict a "complexity score" for each image token, which in turns decides the size of its VAE latent representation.
arxiv.org/abs/2501.03120
by @junhongshen1.bsky.social @lukezettlemoyer.bsky.social et al.
They use an LLM to predict a "complexity score" for each image token, which in turns decides the size of its VAE latent representation.
arxiv.org/abs/2501.03120
*Accurate predictions on small data with a tabular foundation model*
by Noah Hollmann et al.
A transformer for tabular data that takes an entire training set as input and provides predictions - trained on millions of synthetic datasets.
www.nature.com/articles/s41...
by Noah Hollmann et al.
A transformer for tabular data that takes an entire training set as input and provides predictions - trained on millions of synthetic datasets.
www.nature.com/articles/s41...

February 14, 2025 at 3:52 PM
*Accurate predictions on small data with a tabular foundation model*
by Noah Hollmann et al.
A transformer for tabular data that takes an entire training set as input and provides predictions - trained on millions of synthetic datasets.
www.nature.com/articles/s41...
by Noah Hollmann et al.
A transformer for tabular data that takes an entire training set as input and provides predictions - trained on millions of synthetic datasets.
www.nature.com/articles/s41...
*Insights on Galaxy Evolution from Interpretable Sparse Feature Networks*
by @jwuphysics.bsky.social
Integrates a sparse dictionary step on the last layer of a CNN to obtain a set of interpretable features on multiple astronomical prediction tasks.
arxiv.org/abs/2501.00089
by @jwuphysics.bsky.social
Integrates a sparse dictionary step on the last layer of a CNN to obtain a set of interpretable features on multiple astronomical prediction tasks.
arxiv.org/abs/2501.00089

February 13, 2025 at 1:54 PM
*Insights on Galaxy Evolution from Interpretable Sparse Feature Networks*
by @jwuphysics.bsky.social
Integrates a sparse dictionary step on the last layer of a CNN to obtain a set of interpretable features on multiple astronomical prediction tasks.
arxiv.org/abs/2501.00089
by @jwuphysics.bsky.social
Integrates a sparse dictionary step on the last layer of a CNN to obtain a set of interpretable features on multiple astronomical prediction tasks.
arxiv.org/abs/2501.00089
*Round and Round We Go! What makes Rotary Positional Encodings useful?*
by @petar-v.bsky.social et al.
They show RoPE has distinct behavior for different rotation angles - high freq for position, low freq for semantics.
arxiv.org/abs/2410.06205
by @petar-v.bsky.social et al.
They show RoPE has distinct behavior for different rotation angles - high freq for position, low freq for semantics.
arxiv.org/abs/2410.06205

February 10, 2025 at 11:23 AM
*Round and Round We Go! What makes Rotary Positional Encodings useful?*
by @petar-v.bsky.social et al.
They show RoPE has distinct behavior for different rotation angles - high freq for position, low freq for semantics.
arxiv.org/abs/2410.06205
by @petar-v.bsky.social et al.
They show RoPE has distinct behavior for different rotation angles - high freq for position, low freq for semantics.
arxiv.org/abs/2410.06205
*Cautious Optimizers: Improving Training with One Line of Code*
by Liang et al.
Adding a simple masking operation to momentum-based optimizers can significantly boost their speed.
arxiv.org/abs/2411.16085
by Liang et al.
Adding a simple masking operation to momentum-based optimizers can significantly boost their speed.
arxiv.org/abs/2411.16085

February 3, 2025 at 12:30 PM
*Cautious Optimizers: Improving Training with One Line of Code*
by Liang et al.
Adding a simple masking operation to momentum-based optimizers can significantly boost their speed.
arxiv.org/abs/2411.16085
by Liang et al.
Adding a simple masking operation to momentum-based optimizers can significantly boost their speed.
arxiv.org/abs/2411.16085
*Byte Latent Transformer: Patches Scale Better Than Tokens*
by @artidoro.bsky.social et al.
Trains a small encoder to dynamically aggregate bytes into tokens, which are input to a standard autoregressive model. Nice direction!
arxiv.org/abs/2412.09871
by @artidoro.bsky.social et al.
Trains a small encoder to dynamically aggregate bytes into tokens, which are input to a standard autoregressive model. Nice direction!
arxiv.org/abs/2412.09871

January 31, 2025 at 9:56 AM
*Byte Latent Transformer: Patches Scale Better Than Tokens*
by @artidoro.bsky.social et al.
Trains a small encoder to dynamically aggregate bytes into tokens, which are input to a standard autoregressive model. Nice direction!
arxiv.org/abs/2412.09871
by @artidoro.bsky.social et al.
Trains a small encoder to dynamically aggregate bytes into tokens, which are input to a standard autoregressive model. Nice direction!
arxiv.org/abs/2412.09871
*Understanding Gradient Descent through the Training Jacobian*
by @norabelrose.bsky.social @eleutherai.bsky.social
Analyzes training through the spectrum of the "training Jacobian" (∇ of trained weights wrt initial weights), identifying a large inactive subspace.
arxiv.org/abs/2412.07003
by @norabelrose.bsky.social @eleutherai.bsky.social
Analyzes training through the spectrum of the "training Jacobian" (∇ of trained weights wrt initial weights), identifying a large inactive subspace.
arxiv.org/abs/2412.07003

January 28, 2025 at 11:47 AM
*Understanding Gradient Descent through the Training Jacobian*
by @norabelrose.bsky.social @eleutherai.bsky.social
Analyzes training through the spectrum of the "training Jacobian" (∇ of trained weights wrt initial weights), identifying a large inactive subspace.
arxiv.org/abs/2412.07003
by @norabelrose.bsky.social @eleutherai.bsky.social
Analyzes training through the spectrum of the "training Jacobian" (∇ of trained weights wrt initial weights), identifying a large inactive subspace.
arxiv.org/abs/2412.07003
*Mixture of A Million Experts*
by Xu Owen He
Scales a MoE architecture up to millions of experts by implementing a fast retrieval method in the router, inspired by recent MoE scaling laws.
arxiv.org/abs/2407.04153
by Xu Owen He
Scales a MoE architecture up to millions of experts by implementing a fast retrieval method in the router, inspired by recent MoE scaling laws.
arxiv.org/abs/2407.04153

January 27, 2025 at 2:00 PM
*Mixture of A Million Experts*
by Xu Owen He
Scales a MoE architecture up to millions of experts by implementing a fast retrieval method in the router, inspired by recent MoE scaling laws.
arxiv.org/abs/2407.04153
by Xu Owen He
Scales a MoE architecture up to millions of experts by implementing a fast retrieval method in the router, inspired by recent MoE scaling laws.
arxiv.org/abs/2407.04153
*Restructuring Vector Quantization with the Rotation Trick*
by Fifty et al.
Replaces the "closest codebook" operation in vector quantization with a rotation and rescaling operations to improve the back-propagation of gradients.
arxiv.org/abs/2410.06424
by Fifty et al.
Replaces the "closest codebook" operation in vector quantization with a rotation and rescaling operations to improve the back-propagation of gradients.
arxiv.org/abs/2410.06424

January 23, 2025 at 11:31 AM
*Restructuring Vector Quantization with the Rotation Trick*
by Fifty et al.
Replaces the "closest codebook" operation in vector quantization with a rotation and rescaling operations to improve the back-propagation of gradients.
arxiv.org/abs/2410.06424
by Fifty et al.
Replaces the "closest codebook" operation in vector quantization with a rotation and rescaling operations to improve the back-propagation of gradients.
arxiv.org/abs/2410.06424
*On the Surprising Effectiveness of Attention Transfer
for Vision Transformers*
by Li et al.
Shows that distilling attention patterns in ViTs is competitive with standard fine-tuning.
arxiv.org/abs/2411.09702
for Vision Transformers*
by Li et al.
Shows that distilling attention patterns in ViTs is competitive with standard fine-tuning.
arxiv.org/abs/2411.09702

January 21, 2025 at 11:35 AM
*On the Surprising Effectiveness of Attention Transfer
for Vision Transformers*
by Li et al.
Shows that distilling attention patterns in ViTs is competitive with standard fine-tuning.
arxiv.org/abs/2411.09702
for Vision Transformers*
by Li et al.
Shows that distilling attention patterns in ViTs is competitive with standard fine-tuning.
arxiv.org/abs/2411.09702
*The Super Weight in Large Language Models*
by Yu et al.
Identifies single weights in LLMs that destroy inference when deactivated. Tracks their mechanisms through the LLM and proposes quantization-specific techniques.
arxiv.org/abs/2411.07191
by Yu et al.
Identifies single weights in LLMs that destroy inference when deactivated. Tracks their mechanisms through the LLM and proposes quantization-specific techniques.
arxiv.org/abs/2411.07191

January 17, 2025 at 10:55 AM
*The Super Weight in Large Language Models*
by Yu et al.
Identifies single weights in LLMs that destroy inference when deactivated. Tracks their mechanisms through the LLM and proposes quantization-specific techniques.
arxiv.org/abs/2411.07191
by Yu et al.
Identifies single weights in LLMs that destroy inference when deactivated. Tracks their mechanisms through the LLM and proposes quantization-specific techniques.
arxiv.org/abs/2411.07191
*The Surprising Effectiveness of Test-Time Training for Abstract Reasoning*
by @ekinakyurek.bsky.social et al.
Shows that test-time training (fine-tuning at inference time) strongly improves performance on the ARC dataset.
arxiv.org/abs/2411.07279
by @ekinakyurek.bsky.social et al.
Shows that test-time training (fine-tuning at inference time) strongly improves performance on the ARC dataset.
arxiv.org/abs/2411.07279

January 16, 2025 at 10:50 AM
*The Surprising Effectiveness of Test-Time Training for Abstract Reasoning*
by @ekinakyurek.bsky.social et al.
Shows that test-time training (fine-tuning at inference time) strongly improves performance on the ARC dataset.
arxiv.org/abs/2411.07279
by @ekinakyurek.bsky.social et al.
Shows that test-time training (fine-tuning at inference time) strongly improves performance on the ARC dataset.
arxiv.org/abs/2411.07279
Reposted by Simone Scardapane

Our paper “A Survey on Dynamic Neural Networks: from Computer Vision to Multi-modal Sensor Fusion" is out as preprint!
By myself, @sscardapane.bsky.social, @rgring.bsky.social and @lanalpa.bsky.social
📄 arxiv.org/abs/2501.07451
By myself, @sscardapane.bsky.social, @rgring.bsky.social and @lanalpa.bsky.social
📄 arxiv.org/abs/2501.07451

A Survey on Dynamic Neural Networks: from Computer Vision to Multi-modal Sensor Fusion
Model compression is essential in the deployment of large Computer Vision models on embedded devices. However, static optimization techniques (e.g. pruning, quantization, etc.) neglect the fact that d...
arxiv.org
January 15, 2025 at 4:58 PM
Our paper “A Survey on Dynamic Neural Networks: from Computer Vision to Multi-modal Sensor Fusion" is out as preprint!
By myself, @sscardapane.bsky.social, @rgring.bsky.social and @lanalpa.bsky.social
📄 arxiv.org/abs/2501.07451
By myself, @sscardapane.bsky.social, @rgring.bsky.social and @lanalpa.bsky.social
📄 arxiv.org/abs/2501.07451
*Large Concept Models*
by Barrault et al.
Builds an autoregressive model in a "concept" space by wrapping the LLM in a pre-trained sentence embedder (also works with diffusion models).
arxiv.org/abs/2412.08821
by Barrault et al.
Builds an autoregressive model in a "concept" space by wrapping the LLM in a pre-trained sentence embedder (also works with diffusion models).
arxiv.org/abs/2412.08821

January 15, 2025 at 4:09 PM
*Large Concept Models*
by Barrault et al.
Builds an autoregressive model in a "concept" space by wrapping the LLM in a pre-trained sentence embedder (also works with diffusion models).
arxiv.org/abs/2412.08821
by Barrault et al.
Builds an autoregressive model in a "concept" space by wrapping the LLM in a pre-trained sentence embedder (also works with diffusion models).
arxiv.org/abs/2412.08821
Reposted by Simone Scardapane

"Task Singular Vectors: Reducing Task Interference in Model Merging" by Antonio Andrea Gargiulo, @crisostomi.bsky.social , @mariasofiab.bsky.social , @sscardapane.bsky.social, Fabrizio Silvestri, Emanuele Rodolà
Paper: arxiv.org/abs/2412.00081
Code: github.com/AntoAndGar/t...
#machinelearning
Paper: arxiv.org/abs/2412.00081
Code: github.com/AntoAndGar/t...
#machinelearning

January 15, 2025 at 9:36 AM
"Task Singular Vectors: Reducing Task Interference in Model Merging" by Antonio Andrea Gargiulo, @crisostomi.bsky.social , @mariasofiab.bsky.social , @sscardapane.bsky.social, Fabrizio Silvestri, Emanuele Rodolà
Paper: arxiv.org/abs/2412.00081
Code: github.com/AntoAndGar/t...
#machinelearning
Paper: arxiv.org/abs/2412.00081
Code: github.com/AntoAndGar/t...
#machinelearning
*Adaptive Length Image Tokenization via Recurrent Allocation*
by @phillipisola.bsky.social et al.
An encoder to compress an image into a sequence of 1D tokens whose length can dynamically vary depending on the specific image.
arxiv.org/abs/2411.02393
by @phillipisola.bsky.social et al.
An encoder to compress an image into a sequence of 1D tokens whose length can dynamically vary depending on the specific image.
arxiv.org/abs/2411.02393

January 14, 2025 at 11:11 AM
*Adaptive Length Image Tokenization via Recurrent Allocation*
by @phillipisola.bsky.social et al.
An encoder to compress an image into a sequence of 1D tokens whose length can dynamically vary depending on the specific image.
arxiv.org/abs/2411.02393
by @phillipisola.bsky.social et al.
An encoder to compress an image into a sequence of 1D tokens whose length can dynamically vary depending on the specific image.
arxiv.org/abs/2411.02393
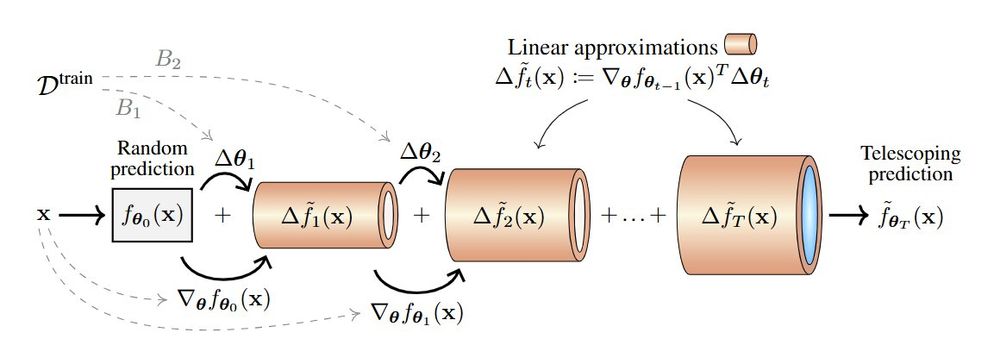
*Deep Learning Through A Telescoping Lens*
by @alanjeffares.bsky.social @aliciacurth.bsky.social
Shows that tracking 1st-order approximations to the training dynamics provides insights into many phenomena (e.g., double descent, grokking).
arxiv.org/abs/2411.00247
by @alanjeffares.bsky.social @aliciacurth.bsky.social
Shows that tracking 1st-order approximations to the training dynamics provides insights into many phenomena (e.g., double descent, grokking).
arxiv.org/abs/2411.00247
January 14, 2025 at 10:43 AM
*Deep Learning Through A Telescoping Lens*
by @alanjeffares.bsky.social @aliciacurth.bsky.social
Shows that tracking 1st-order approximations to the training dynamics provides insights into many phenomena (e.g., double descent, grokking).
arxiv.org/abs/2411.00247
by @alanjeffares.bsky.social @aliciacurth.bsky.social
Shows that tracking 1st-order approximations to the training dynamics provides insights into many phenomena (e.g., double descent, grokking).
arxiv.org/abs/2411.00247
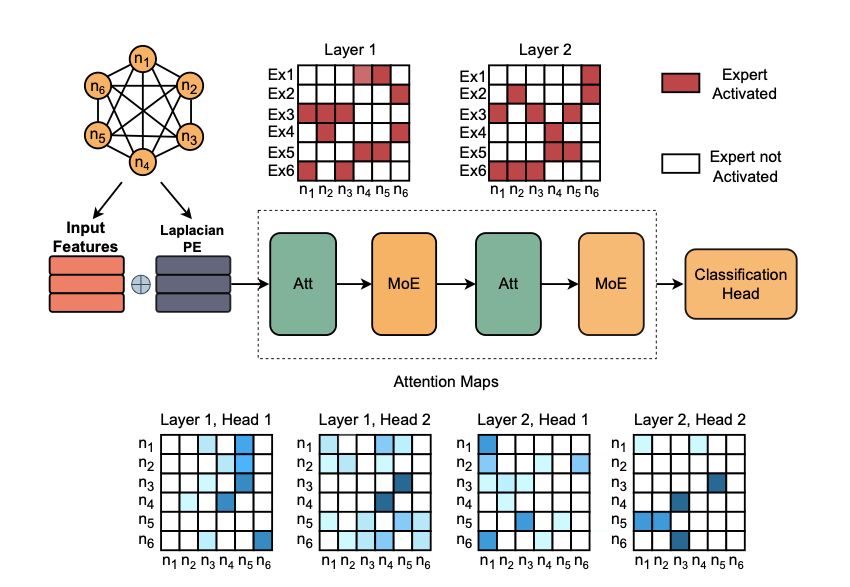
*MoE Graph Transformers for Interpretable Particle Collision Detection*
by @alessiodevoto.bsky.social @sgiagu.bsky.social et al.
We propose a MoE graph transformer for particle collision analysis, with many nice interpretability insights (e.g., expert specialization).
arxiv.org/abs/2501.03432
by @alessiodevoto.bsky.social @sgiagu.bsky.social et al.
We propose a MoE graph transformer for particle collision analysis, with many nice interpretability insights (e.g., expert specialization).
arxiv.org/abs/2501.03432
January 10, 2025 at 2:12 PM
*MoE Graph Transformers for Interpretable Particle Collision Detection*
by @alessiodevoto.bsky.social @sgiagu.bsky.social et al.
We propose a MoE graph transformer for particle collision analysis, with many nice interpretability insights (e.g., expert specialization).
arxiv.org/abs/2501.03432
by @alessiodevoto.bsky.social @sgiagu.bsky.social et al.
We propose a MoE graph transformer for particle collision analysis, with many nice interpretability insights (e.g., expert specialization).
arxiv.org/abs/2501.03432