




Donato Crisostomi ✈️ NeurIPS
@crisostomi.bsky.social
🧑🎓 PhD stud. @ Sapienza, Rome
🥷stealth-mode CEO
🔬prev visiting @ Cambridge | RS intern @ Amazon Search | RS intern @ Alexa.
🆓 time 🎭improv theater, 🤿scuba diving, ⛰️hiking
🥷stealth-mode CEO
🔬prev visiting @ Cambridge | RS intern @ Amazon Search | RS intern @ Alexa.
🆓 time 🎭improv theater, 🤿scuba diving, ⛰️hiking
Will present this at #CVPR ✈️ See you in Nashville 🇺🇸!
Kudos to the team 👏
Antonio A. Gargiulo, @mariasofiab.bsky.social, @sscardapane.bsky.social, Fabrizio Silvestri, Emanuele Rodolà.
Kudos to the team 👏
Antonio A. Gargiulo, @mariasofiab.bsky.social, @sscardapane.bsky.social, Fabrizio Silvestri, Emanuele Rodolà.
📢Prepend “Singular” to “Task Vectors” and get +15% average accuracy for free!
1. Perform a low-rank approximation of layer-wise task vectors.
2. Minimize task interference by orthogonalizing inter-task singular vectors.
🧵(1/6)
1. Perform a low-rank approximation of layer-wise task vectors.
2. Minimize task interference by orthogonalizing inter-task singular vectors.
🧵(1/6)
March 11, 2025 at 8:02 AM
Will present this at #CVPR ✈️ See you in Nashville 🇺🇸!
Kudos to the team 👏
Antonio A. Gargiulo, @mariasofiab.bsky.social, @sscardapane.bsky.social, Fabrizio Silvestri, Emanuele Rodolà.
Kudos to the team 👏
Antonio A. Gargiulo, @mariasofiab.bsky.social, @sscardapane.bsky.social, Fabrizio Silvestri, Emanuele Rodolà.
📢Prepend “Singular” to “Task Vectors” and get +15% average accuracy for free!
1. Perform a low-rank approximation of layer-wise task vectors.
2. Minimize task interference by orthogonalizing inter-task singular vectors.
🧵(1/6)
1. Perform a low-rank approximation of layer-wise task vectors.
2. Minimize task interference by orthogonalizing inter-task singular vectors.
🧵(1/6)
January 8, 2025 at 7:00 PM
📢Prepend “Singular” to “Task Vectors” and get +15% average accuracy for free!
1. Perform a low-rank approximation of layer-wise task vectors.
2. Minimize task interference by orthogonalizing inter-task singular vectors.
🧵(1/6)
1. Perform a low-rank approximation of layer-wise task vectors.
2. Minimize task interference by orthogonalizing inter-task singular vectors.
🧵(1/6)
📣 Come check it this Friday at #NeurIPS!
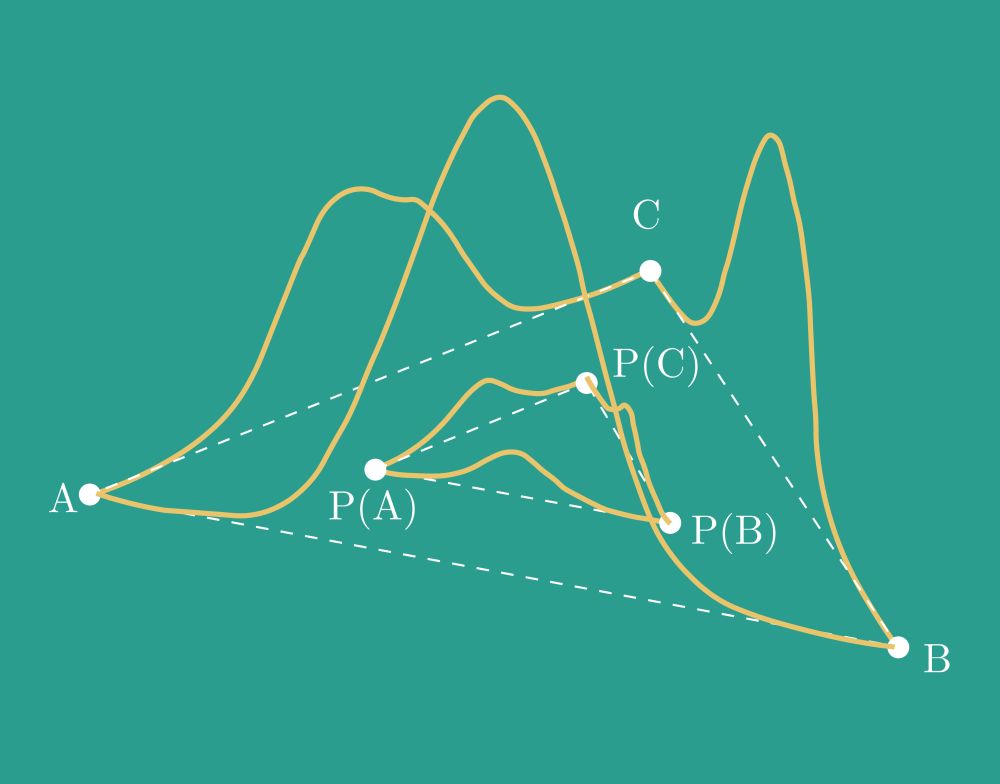
I know you're probably thinking, "Yeah, these neuron-permutation-based model merging methods are cool.. but are they cycle-consistent (CC)?"
Say no more!
It just so happens that our new #NeurIPS24 paper covers exactly this!
Huh? No idea what I am talking about? Read on
(1/6)
Say no more!
It just so happens that our new #NeurIPS24 paper covers exactly this!
Huh? No idea what I am talking about? Read on
(1/6)
December 9, 2024 at 4:38 PM
📣 Come check it this Friday at #NeurIPS!
I know you're probably thinking, "Yeah, these neuron-permutation-based model merging methods are cool.. but are they cycle-consistent (CC)?"
Say no more!
It just so happens that our new #NeurIPS24 paper covers exactly this!
Huh? No idea what I am talking about? Read on
(1/6)
Say no more!
It just so happens that our new #NeurIPS24 paper covers exactly this!
Huh? No idea what I am talking about? Read on
(1/6)
December 5, 2024 at 8:38 AM
I know you're probably thinking, "Yeah, these neuron-permutation-based model merging methods are cool.. but are they cycle-consistent (CC)?"
Say no more!
It just so happens that our new #NeurIPS24 paper covers exactly this!
Huh? No idea what I am talking about? Read on
(1/6)
Say no more!
It just so happens that our new #NeurIPS24 paper covers exactly this!
Huh? No idea what I am talking about? Read on
(1/6)
First blue post (still have to figure out how tweets are called here)
💡idea: we consider task vectors at the layer level and reduce task interference by decorrelating the task-specific singular vectors of any matrix-structured layer
🔬results: large-margin improvements across all vision benchmarks
💡idea: we consider task vectors at the layer level and reduce task interference by decorrelating the task-specific singular vectors of any matrix-structured layer
🔬results: large-margin improvements across all vision benchmarks

*Task Singular Vectors: Reducing Task Interference in Model Merging*
We show that task vectors are inherently low-rank, and we propose a merging method that significantly improves SOTA.
arxiv.org/abs/2412.00081
We show that task vectors are inherently low-rank, and we propose a merging method that significantly improves SOTA.
arxiv.org/abs/2412.00081


December 5, 2024 at 8:11 AM
First blue post (still have to figure out how tweets are called here)
💡idea: we consider task vectors at the layer level and reduce task interference by decorrelating the task-specific singular vectors of any matrix-structured layer
🔬results: large-margin improvements across all vision benchmarks
💡idea: we consider task vectors at the layer level and reduce task interference by decorrelating the task-specific singular vectors of any matrix-structured layer
🔬results: large-margin improvements across all vision benchmarks