




Donato Crisostomi ✈️ NeurIPS
@crisostomi.bsky.social
🧑🎓 PhD stud. @ Sapienza, Rome
🥷stealth-mode CEO
🔬prev visiting @ Cambridge | RS intern @ Amazon Search | RS intern @ Alexa.
🆓 time 🎭improv theater, 🤿scuba diving, ⛰️hiking
🥷stealth-mode CEO
🔬prev visiting @ Cambridge | RS intern @ Amazon Search | RS intern @ Alexa.
🆓 time 🎭improv theater, 🤿scuba diving, ⛰️hiking
By orthogonalizing the (low-rank approximated) task singular vectors, we effectively eliminate interference.
This leads to an impressive +15% gain without any test-time adaptation!
The improvement is consistent across all datasets.
🧵(5/6)
This leads to an impressive +15% gain without any test-time adaptation!
The improvement is consistent across all datasets.
🧵(5/6)
January 8, 2025 at 7:00 PM
By orthogonalizing the (low-rank approximated) task singular vectors, we effectively eliminate interference.
This leads to an impressive +15% gain without any test-time adaptation!
The improvement is consistent across all datasets.
🧵(5/6)
This leads to an impressive +15% gain without any test-time adaptation!
The improvement is consistent across all datasets.
🧵(5/6)
We believe this happens due to inter-task interference, which we measure as the interplay between singular vectors from different tasks (A).
(B) This interference is higher in shallower (more general) layers and lower in deeper (more task-specific) layers!
🧵(4/6)
(B) This interference is higher in shallower (more general) layers and lower in deeper (more task-specific) layers!
🧵(4/6)

January 8, 2025 at 7:00 PM
We believe this happens due to inter-task interference, which we measure as the interplay between singular vectors from different tasks (A).
(B) This interference is higher in shallower (more general) layers and lower in deeper (more task-specific) layers!
🧵(4/6)
(B) This interference is higher in shallower (more general) layers and lower in deeper (more task-specific) layers!
🧵(4/6)
But is low-rank approximation enough to achieve effective multi-task merging?
The answer is NO! In fact, it can even be detrimental.
Why is that?
🧵(3/6)
The answer is NO! In fact, it can even be detrimental.
Why is that?
🧵(3/6)

January 8, 2025 at 7:00 PM
But is low-rank approximation enough to achieve effective multi-task merging?
The answer is NO! In fact, it can even be detrimental.
Why is that?
🧵(3/6)
The answer is NO! In fact, it can even be detrimental.
Why is that?
🧵(3/6)
Let’s start with the low-rank structure:
By keeping only a small fraction (e.g., 10%) of task singular vectors for each model, average accuracy is preserved!
🧵(2/6)
By keeping only a small fraction (e.g., 10%) of task singular vectors for each model, average accuracy is preserved!
🧵(2/6)

January 8, 2025 at 7:00 PM
Let’s start with the low-rank structure:
By keeping only a small fraction (e.g., 10%) of task singular vectors for each model, average accuracy is preserved!
🧵(2/6)
By keeping only a small fraction (e.g., 10%) of task singular vectors for each model, average accuracy is preserved!
🧵(2/6)
📢Prepend “Singular” to “Task Vectors” and get +15% average accuracy for free!
1. Perform a low-rank approximation of layer-wise task vectors.
2. Minimize task interference by orthogonalizing inter-task singular vectors.
🧵(1/6)
1. Perform a low-rank approximation of layer-wise task vectors.
2. Minimize task interference by orthogonalizing inter-task singular vectors.
🧵(1/6)
January 8, 2025 at 7:00 PM
📢Prepend “Singular” to “Task Vectors” and get +15% average accuracy for free!
1. Perform a low-rank approximation of layer-wise task vectors.
2. Minimize task interference by orthogonalizing inter-task singular vectors.
🧵(1/6)
1. Perform a low-rank approximation of layer-wise task vectors.
2. Minimize task interference by orthogonalizing inter-task singular vectors.
🧵(1/6)
Yes, and it works best when applying Repair (Jordan et al, 2022) to fix the activation statistics!
The approach is designed to merge 3+ models (as CC doesn't make much sense otherwise), but if you are curious about applying Frank-Wolfe for n=2, please check the paper!
(5/6)
The approach is designed to merge 3+ models (as CC doesn't make much sense otherwise), but if you are curious about applying Frank-Wolfe for n=2, please check the paper!
(5/6)

December 5, 2024 at 8:38 AM
Yes, and it works best when applying Repair (Jordan et al, 2022) to fix the activation statistics!
The approach is designed to merge 3+ models (as CC doesn't make much sense otherwise), but if you are curious about applying Frank-Wolfe for n=2, please check the paper!
(5/6)
The approach is designed to merge 3+ models (as CC doesn't make much sense otherwise), but if you are curious about applying Frank-Wolfe for n=2, please check the paper!
(5/6)
Yeah but why bother?
1) Optimizing globally, we don't have any more variance from the random layer order
2) The models in the universe are much more linearly connected than before
3) The models in the universe are much more similar
Does this result in better merging?
(4/6)
1) Optimizing globally, we don't have any more variance from the random layer order
2) The models in the universe are much more linearly connected than before
3) The models in the universe are much more similar
Does this result in better merging?
(4/6)

December 5, 2024 at 8:38 AM
Yeah but why bother?
1) Optimizing globally, we don't have any more variance from the random layer order
2) The models in the universe are much more linearly connected than before
3) The models in the universe are much more similar
Does this result in better merging?
(4/6)
1) Optimizing globally, we don't have any more variance from the random layer order
2) The models in the universe are much more linearly connected than before
3) The models in the universe are much more similar
Does this result in better merging?
(4/6)
Ok but how?
1) Start from the weight-matching equation introduced by Git Re-Basin
2) Consider perms between all possible pairs
3) Replace each permutation A->B with one mapping to the universe A -> U and one mapping back U -> B
4) Optimize with Frank-Wolfe
(3/6)
1) Start from the weight-matching equation introduced by Git Re-Basin
2) Consider perms between all possible pairs
3) Replace each permutation A->B with one mapping to the universe A -> U and one mapping back U -> B
4) Optimize with Frank-Wolfe
(3/6)

December 5, 2024 at 8:38 AM
Ok but how?
1) Start from the weight-matching equation introduced by Git Re-Basin
2) Consider perms between all possible pairs
3) Replace each permutation A->B with one mapping to the universe A -> U and one mapping back U -> B
4) Optimize with Frank-Wolfe
(3/6)
1) Start from the weight-matching equation introduced by Git Re-Basin
2) Consider perms between all possible pairs
3) Replace each permutation A->B with one mapping to the universe A -> U and one mapping back U -> B
4) Optimize with Frank-Wolfe
(3/6)
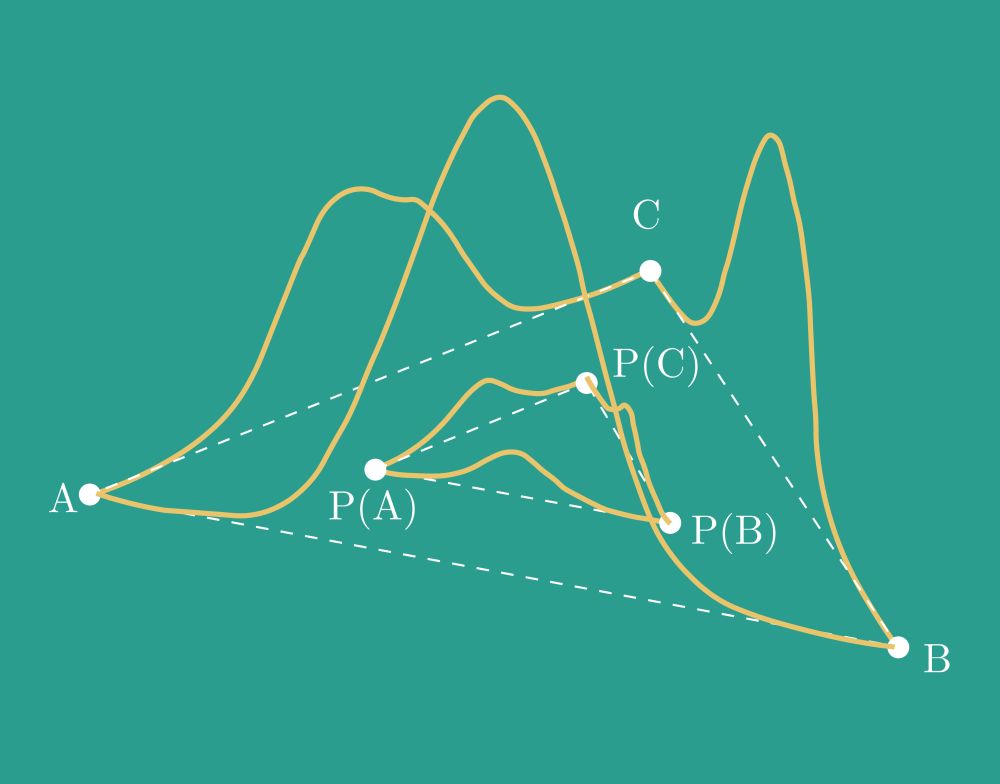
If you have 3+ models A, B, and C, permitting neurons from A to B to C and back to A gets you to a different model, as the composition of the perms is not the identity!
What then? Introduce a Universe space 🌌and use it as a midpoint 🔀
This way, CC is guaranteed!
(2/6)
What then? Introduce a Universe space 🌌and use it as a midpoint 🔀
This way, CC is guaranteed!
(2/6)

December 5, 2024 at 8:38 AM
If you have 3+ models A, B, and C, permitting neurons from A to B to C and back to A gets you to a different model, as the composition of the perms is not the identity!
What then? Introduce a Universe space 🌌and use it as a midpoint 🔀
This way, CC is guaranteed!
(2/6)
What then? Introduce a Universe space 🌌and use it as a midpoint 🔀
This way, CC is guaranteed!
(2/6)
I know you're probably thinking, "Yeah, these neuron-permutation-based model merging methods are cool.. but are they cycle-consistent (CC)?"
Say no more!
It just so happens that our new #NeurIPS24 paper covers exactly this!
Huh? No idea what I am talking about? Read on
(1/6)
Say no more!
It just so happens that our new #NeurIPS24 paper covers exactly this!
Huh? No idea what I am talking about? Read on
(1/6)
December 5, 2024 at 8:38 AM
I know you're probably thinking, "Yeah, these neuron-permutation-based model merging methods are cool.. but are they cycle-consistent (CC)?"
Say no more!
It just so happens that our new #NeurIPS24 paper covers exactly this!
Huh? No idea what I am talking about? Read on
(1/6)
Say no more!
It just so happens that our new #NeurIPS24 paper covers exactly this!
Huh? No idea what I am talking about? Read on
(1/6)