


Stella Frank
@scfrank.bsky.social
Thinking about multimodal representations | Postdoc at UCPH/Pioneer Centre for AI (DK).
Reposted by Stella Frank

1/8 🧵 GPT-5's storytelling problems reveal a deeper AI safety issue. I've been testing its creative writing capabilities, and the results are concerning - not just for literature, but for AI development more broadly. 🚨
August 26, 2025 at 3:15 PM
1/8 🧵 GPT-5's storytelling problems reveal a deeper AI safety issue. I've been testing its creative writing capabilities, and the results are concerning - not just for literature, but for AI development more broadly. 🚨
Reposted by Stella Frank

My Lab at the University of Edinburgh🇬🇧 has funded PhD positions for this cycle!
We study the computational principles of how people learn, reason, and communicate.
It's a new lab, and you will be playing a big role in shaping its culture and foundations.
Spread the words!
We study the computational principles of how people learn, reason, and communicate.
It's a new lab, and you will be playing a big role in shaping its culture and foundations.
Spread the words!

August 17, 2025 at 11:52 AM
My Lab at the University of Edinburgh🇬🇧 has funded PhD positions for this cycle!
We study the computational principles of how people learn, reason, and communicate.
It's a new lab, and you will be playing a big role in shaping its culture and foundations.
Spread the words!
We study the computational principles of how people learn, reason, and communicate.
It's a new lab, and you will be playing a big role in shaping its culture and foundations.
Spread the words!
Reposted by Stella Frank

🚀 DinoV3 just became the new go-to backbone for geoloc!
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.

August 18, 2025 at 3:14 PM
🚀 DinoV3 just became the new go-to backbone for geoloc!
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.
Reposted by Stella Frank

I wrote a short rant about what irks me when people anthropomorphize LLMs:
addxorrol.blogspot.com/2025/07/a-no...
addxorrol.blogspot.com/2025/07/a-no...
A non-anthropomorphized view of LLMs
In many discussions where questions of "alignment" or "AI safety" crop up, I am baffled by seriously intelligent people imbuing almost magic...
addxorrol.blogspot.com
July 7, 2025 at 6:37 AM
I wrote a short rant about what irks me when people anthropomorphize LLMs:
addxorrol.blogspot.com/2025/07/a-no...
addxorrol.blogspot.com/2025/07/a-no...
Reposted by Stella Frank

📢I am hiring a Postdoc to work on post-training methods for low-resource languages. Apply by August 15 employment.ku.dk/faculty/?sho....
Let's talk at #ACL2025NLP in Vienna if you want to know more about the position and life in Denmark.
Let's talk at #ACL2025NLP in Vienna if you want to know more about the position and life in Denmark.

Postdoc in Natural Language Processing
employment.ku.dk
July 7, 2025 at 12:47 PM
📢I am hiring a Postdoc to work on post-training methods for low-resource languages. Apply by August 15 employment.ku.dk/faculty/?sho....
Let's talk at #ACL2025NLP in Vienna if you want to know more about the position and life in Denmark.
Let's talk at #ACL2025NLP in Vienna if you want to know more about the position and life in Denmark.
Reposted by Stella Frank

New paper hot off the press www.nature.com/articles/s41...
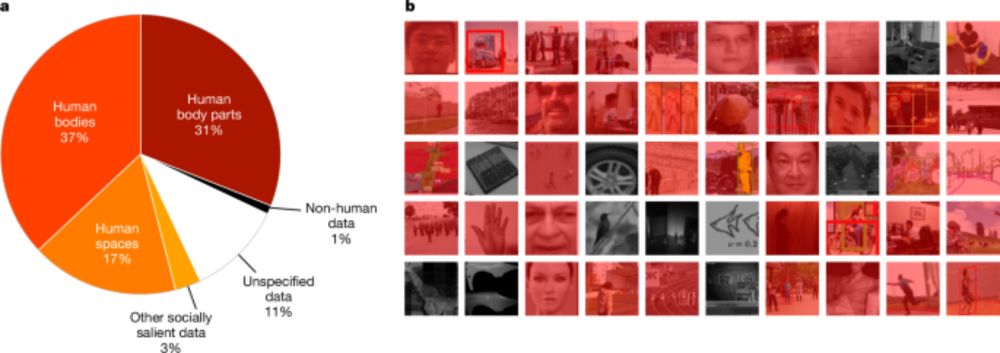
We analysed over 40,000 computer vision papers from CVPR (the longest standing CV conf) & associated patents tracing pathways from research to application. We found that 90% of papers & 86% of downstream patents power surveillance
1/
We analysed over 40,000 computer vision papers from CVPR (the longest standing CV conf) & associated patents tracing pathways from research to application. We found that 90% of papers & 86% of downstream patents power surveillance
1/
Computer-vision research powers surveillance technology - Nature
An analysis of research papers and citing patents indicates the extensive ties between computer-vision research and surveillance.
www.nature.com
June 25, 2025 at 5:29 PM
New paper hot off the press www.nature.com/articles/s41...
We analysed over 40,000 computer vision papers from CVPR (the longest standing CV conf) & associated patents tracing pathways from research to application. We found that 90% of papers & 86% of downstream patents power surveillance
1/
We analysed over 40,000 computer vision papers from CVPR (the longest standing CV conf) & associated patents tracing pathways from research to application. We found that 90% of papers & 86% of downstream patents power surveillance
1/
Reposted by Stella Frank

"Researching and reflecting on the harms of AI is not itself harm reduction. It may even contribute to rationalizing, normalizing, and enabling harm. Critical reflection without appropriate action is thus quintessentially critical washing."

Critical AI Literacy: Beyond hegemonic perspectives on sustainability
open.substack.com/pub/rcsc/p/c...
open.substack.com/pub/rcsc/p/c...

Critical AI Literacy: Beyond hegemonic perspectives on sustainability
How can universities resist being coopted and corrupted by the AI industries’ agendas?
open.substack.com
June 15, 2025 at 2:18 PM
"Researching and reflecting on the harms of AI is not itself harm reduction. It may even contribute to rationalizing, normalizing, and enabling harm. Critical reflection without appropriate action is thus quintessentially critical washing."
Fallacy of the Day:
Calling two different things by the same name doesn't make them the same (jingle) and calling the same thing by different names doesn't make them different (jangle)
en.wikipedia.org/wiki/Jingle-...
(this is going to be so useful for reviewing)
Calling two different things by the same name doesn't make them the same (jingle) and calling the same thing by different names doesn't make them different (jangle)
en.wikipedia.org/wiki/Jingle-...
(this is going to be so useful for reviewing)
Jingle-jangle fallacies - Wikipedia
en.wikipedia.org
June 17, 2025 at 3:32 PM
Fallacy of the Day:
Calling two different things by the same name doesn't make them the same (jingle) and calling the same thing by different names doesn't make them different (jangle)
en.wikipedia.org/wiki/Jingle-...
(this is going to be so useful for reviewing)
Calling two different things by the same name doesn't make them the same (jingle) and calling the same thing by different names doesn't make them different (jangle)
en.wikipedia.org/wiki/Jingle-...
(this is going to be so useful for reviewing)
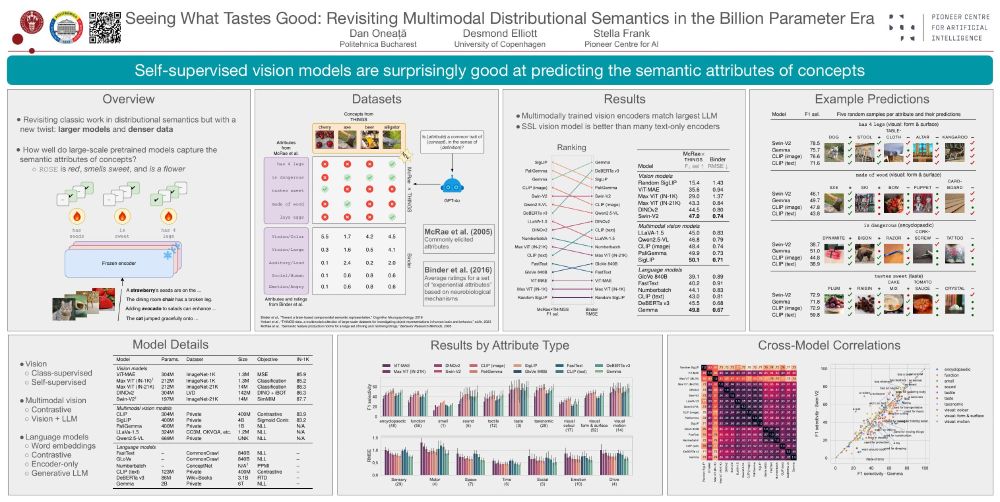
📯 Best Paper Award at CVPR workshop on Visual concepts for our (@doneata.bsky.social + @delliott.bsky.social) paper on probing vision/lang/ vision+lang models for semantic norms!
TLDR: SSL vision models (swinV2, dinoV2) are surprisingly similar to LLM & VLMs even w/o lang 👀
arxiv.org/abs/2506.03994
TLDR: SSL vision models (swinV2, dinoV2) are surprisingly similar to LLM & VLMs even w/o lang 👀
arxiv.org/abs/2506.03994
June 13, 2025 at 3:15 PM
📯 Best Paper Award at CVPR workshop on Visual concepts for our (@doneata.bsky.social + @delliott.bsky.social) paper on probing vision/lang/ vision+lang models for semantic norms!
TLDR: SSL vision models (swinV2, dinoV2) are surprisingly similar to LLM & VLMs even w/o lang 👀
arxiv.org/abs/2506.03994
TLDR: SSL vision models (swinV2, dinoV2) are surprisingly similar to LLM & VLMs even w/o lang 👀
arxiv.org/abs/2506.03994
Reposted by Stella Frank

I am excited to announce our latest work 🎉 "Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory". We review recent works on culture in VLMs and argue for deeper grounding in cultural theory to enable more inclusive evaluations.
Paper 🔗: arxiv.org/pdf/2505.22793
Paper 🔗: arxiv.org/pdf/2505.22793

June 2, 2025 at 10:36 AM
I am excited to announce our latest work 🎉 "Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory". We review recent works on culture in VLMs and argue for deeper grounding in cultural theory to enable more inclusive evaluations.
Paper 🔗: arxiv.org/pdf/2505.22793
Paper 🔗: arxiv.org/pdf/2505.22793
Reposted by Stella Frank

Check out our new paper led by @srishtiy.bsky.social and @nolauren.bsky.social! This work brings together computer vision, cultural theory, semiotics, and visual studies to provide new tools and perspectives for the study of ~culture~ in VLMs.
I am excited to announce our latest work 🎉 "Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory". We review recent works on culture in VLMs and argue for deeper grounding in cultural theory to enable more inclusive evaluations.
Paper 🔗: arxiv.org/pdf/2505.22793
Paper 🔗: arxiv.org/pdf/2505.22793
June 2, 2025 at 12:37 PM
Check out our new paper led by @srishtiy.bsky.social and @nolauren.bsky.social! This work brings together computer vision, cultural theory, semiotics, and visual studies to provide new tools and perspectives for the study of ~culture~ in VLMs.
Reposted by Stella Frank

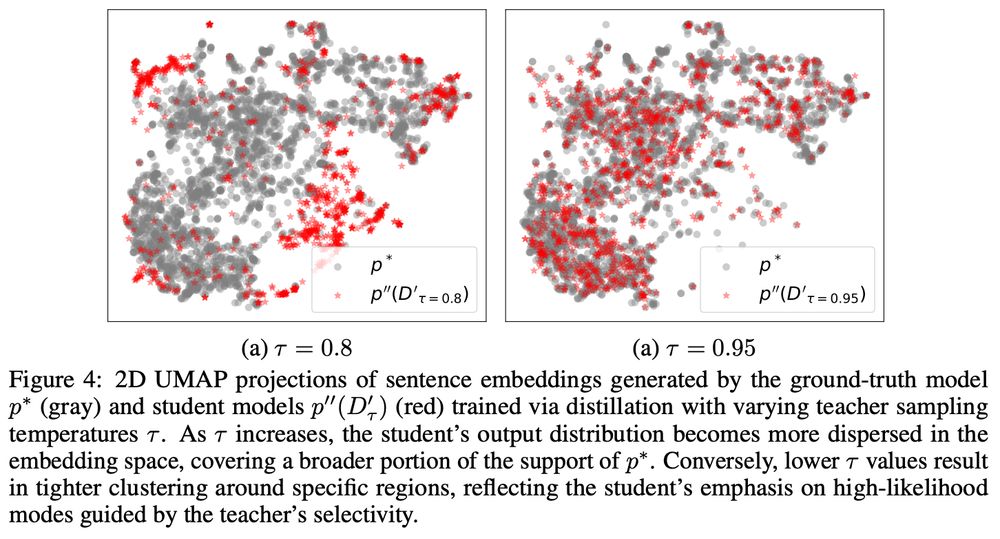
as an extra take-away, this implies that our eval tends to be overly precision focused. we should really think of what we lose in terms of recalls, as this directly relates to what we miss out for whom when we build these large-scale, general-purpose models.
(4/4)
(4/4)
May 20, 2025 at 12:18 PM
as an extra take-away, this implies that our eval tends to be overly precision focused. we should really think of what we lose in terms of recalls, as this directly relates to what we miss out for whom when we build these large-scale, general-purpose models.
(4/4)
(4/4)
Reposted by Stella Frank

🚀 We are excited to introduce Kaleidoscope, the largest culturally-authentic exam benchmark.
📌 Most VLM benchmarks are English-centric or rely on translations—missing linguistic & cultural nuance. Kaleidoscope expands in-language multilingual 🌎 & multimodal 👀 VLMs evaluation
📌 Most VLM benchmarks are English-centric or rely on translations—missing linguistic & cultural nuance. Kaleidoscope expands in-language multilingual 🌎 & multimodal 👀 VLMs evaluation

April 10, 2025 at 8:24 PM
🚀 We are excited to introduce Kaleidoscope, the largest culturally-authentic exam benchmark.
📌 Most VLM benchmarks are English-centric or rely on translations—missing linguistic & cultural nuance. Kaleidoscope expands in-language multilingual 🌎 & multimodal 👀 VLMs evaluation
📌 Most VLM benchmarks are English-centric or rely on translations—missing linguistic & cultural nuance. Kaleidoscope expands in-language multilingual 🌎 & multimodal 👀 VLMs evaluation
Reposted by Stella Frank

Join us and revolutionize Life Science Lab Automation! 🎓🤖💉
I am hiring a Postdoc in Robotics and Computer Vision for Life Science Laboratory Automation, in Copenhagen, Denmark.
Is that you? 🙋♀️
efzu.fa.em2.oraclecloud.com/hcmUI/Candid...
I am hiring a Postdoc in Robotics and Computer Vision for Life Science Laboratory Automation, in Copenhagen, Denmark.
Is that you? 🙋♀️
efzu.fa.em2.oraclecloud.com/hcmUI/Candid...

Postdoc in Robotics and Computer Vision for Life Science Laboratory Automation - DTU Electro
As part of a joint research collaboration between DTU and Novo Nordisk, we are looking for a postdoc to join our multidisciplinary research program focusing on the interplay between AI-Protein design,...
efzu.fa.em2.oraclecloud.com
April 11, 2025 at 1:53 PM
Join us and revolutionize Life Science Lab Automation! 🎓🤖💉
I am hiring a Postdoc in Robotics and Computer Vision for Life Science Laboratory Automation, in Copenhagen, Denmark.
Is that you? 🙋♀️
efzu.fa.em2.oraclecloud.com/hcmUI/Candid...
I am hiring a Postdoc in Robotics and Computer Vision for Life Science Laboratory Automation, in Copenhagen, Denmark.
Is that you? 🙋♀️
efzu.fa.em2.oraclecloud.com/hcmUI/Candid...
Reposted by Stella Frank

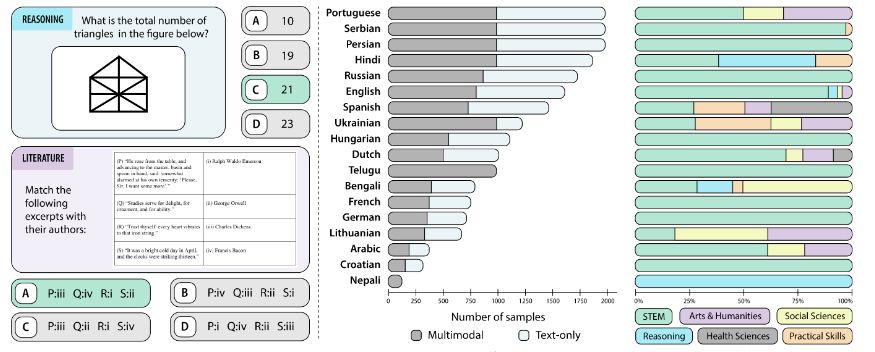
Today we are releasing Kaleidoscope 🎉
A comprehensive multimodal & multilingual benchmark for VLMs! It contains real questions from exams in different languages.
🌍 20,911 questions and 18 languages
📚 14 subjects (STEM → Humanities)
📸 55% multimodal questions
A comprehensive multimodal & multilingual benchmark for VLMs! It contains real questions from exams in different languages.
🌍 20,911 questions and 18 languages
📚 14 subjects (STEM → Humanities)
📸 55% multimodal questions
April 10, 2025 at 10:31 AM
Today we are releasing Kaleidoscope 🎉
A comprehensive multimodal & multilingual benchmark for VLMs! It contains real questions from exams in different languages.
🌍 20,911 questions and 18 languages
📚 14 subjects (STEM → Humanities)
📸 55% multimodal questions
A comprehensive multimodal & multilingual benchmark for VLMs! It contains real questions from exams in different languages.
🌍 20,911 questions and 18 languages
📚 14 subjects (STEM → Humanities)
📸 55% multimodal questions
Reposted by Stella Frank

We are looking for two PhD students at our institute in Munich.
Both postions are open-topic, so anything between cognitive science and machine learning is possible.
More information: hcai-munich.com/PhDHCAI.pdf
Feel free to share broadly!
Both postions are open-topic, so anything between cognitive science and machine learning is possible.
More information: hcai-munich.com/PhDHCAI.pdf
Feel free to share broadly!
hcai-munich.com
April 9, 2025 at 12:11 PM
We are looking for two PhD students at our institute in Munich.
Both postions are open-topic, so anything between cognitive science and machine learning is possible.
More information: hcai-munich.com/PhDHCAI.pdf
Feel free to share broadly!
Both postions are open-topic, so anything between cognitive science and machine learning is possible.
More information: hcai-munich.com/PhDHCAI.pdf
Feel free to share broadly!
Reposted by Stella Frank

📢Excited to announce our upcoming workshop - Vision Language Models For All: Building Geo-Diverse and Culturally Aware Vision-Language Models (VLMs-4-All) @CVPR 2025!
🌐 sites.google.com/view/vlms4all
🌐 sites.google.com/view/vlms4all

March 14, 2025 at 3:55 PM
📢Excited to announce our upcoming workshop - Vision Language Models For All: Building Geo-Diverse and Culturally Aware Vision-Language Models (VLMs-4-All) @CVPR 2025!
🌐 sites.google.com/view/vlms4all
🌐 sites.google.com/view/vlms4all
Reposted by Stella Frank

BirdCLEF25: Audio-based species identification focused on birds, amphibians, mammals, and insects in Colombia.
👉 www.kaggle.com/competitions...
@cvprconference.bsky.social @kaggle.com
#FGVC #CVPR #CVPR2025 #LifeCLEF
[1/4]
👉 www.kaggle.com/competitions...
@cvprconference.bsky.social @kaggle.com
#FGVC #CVPR #CVPR2025 #LifeCLEF
[1/4]

April 9, 2025 at 10:22 AM
BirdCLEF25: Audio-based species identification focused on birds, amphibians, mammals, and insects in Colombia.
👉 www.kaggle.com/competitions...
@cvprconference.bsky.social @kaggle.com
#FGVC #CVPR #CVPR2025 #LifeCLEF
[1/4]
👉 www.kaggle.com/competitions...
@cvprconference.bsky.social @kaggle.com
#FGVC #CVPR #CVPR2025 #LifeCLEF
[1/4]
Reposted by Stella Frank

Thanks to these insects, we can now study environmental microplastics retrospectively. 🔍 Even before Duprat began his now famous experiments with caddisfly larvae, insects in the wild were already experimenting with plastic... 🐛 14/x

April 9, 2025 at 10:07 AM
Thanks to these insects, we can now study environmental microplastics retrospectively. 🔍 Even before Duprat began his now famous experiments with caddisfly larvae, insects in the wild were already experimenting with plastic... 🐛 14/x
Reposted by Stella Frank

The Wikimedia Foundation, which owns Wikipedia, says its bandwidth costs have gone up 50% since Jan 2024 — a rise they attribute to AI crawlers.
AI companies are killing the open web by stealing visitors from the sources of information and making them pay for the privilege
AI companies are killing the open web by stealing visitors from the sources of information and making them pay for the privilege

April 2, 2025 at 9:12 AM
The Wikimedia Foundation, which owns Wikipedia, says its bandwidth costs have gone up 50% since Jan 2024 — a rise they attribute to AI crawlers.
AI companies are killing the open web by stealing visitors from the sources of information and making them pay for the privilege
AI companies are killing the open web by stealing visitors from the sources of information and making them pay for the privilege
What a weekend to find Heinrich von Kleist's Erzählungen next to the skip, in which the first story is literally about a man wreaking murderous havoc because of the imposition of arbitrary trade tariffs en.wikipedia.org/wiki/Michael...
April 6, 2025 at 6:15 PM
What a weekend to find Heinrich von Kleist's Erzählungen next to the skip, in which the first story is literally about a man wreaking murderous havoc because of the imposition of arbitrary trade tariffs en.wikipedia.org/wiki/Michael...

Reposted by Stella Frank

The world's 500 richest people saw their combined wealth fall by a combined $208 billion, the most since Covid, as tariffs sent markets into a tailspin

Billionaires Lose Combined $208 Billion in One Day From Trump Tariffs
The world’s 500 richest people saw their combined wealth plunge by $208 billion Thursday as broad tariffs announced by President Donald Trump sent global markets into a tailspin.
www.bloomberg.com
April 3, 2025 at 9:55 PM
The world's 500 richest people saw their combined wealth fall by a combined $208 billion, the most since Covid, as tariffs sent markets into a tailspin
Reposted by Stella Frank

I’m excited to share our newest paper which is the first to analyze all of our in our TINTIN Corpus: 1,030 comics from 144 countries. We asked: How much are comic layouts influenced by the writing systems of their authors? www.sciencedirect.com/science/arti...
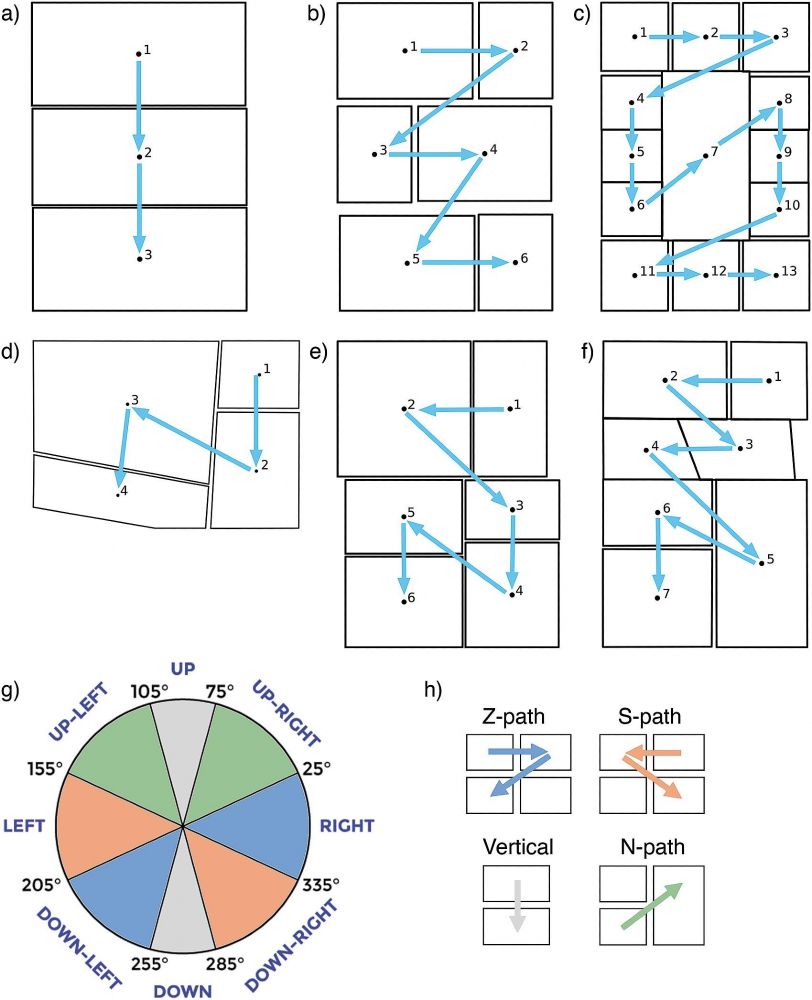
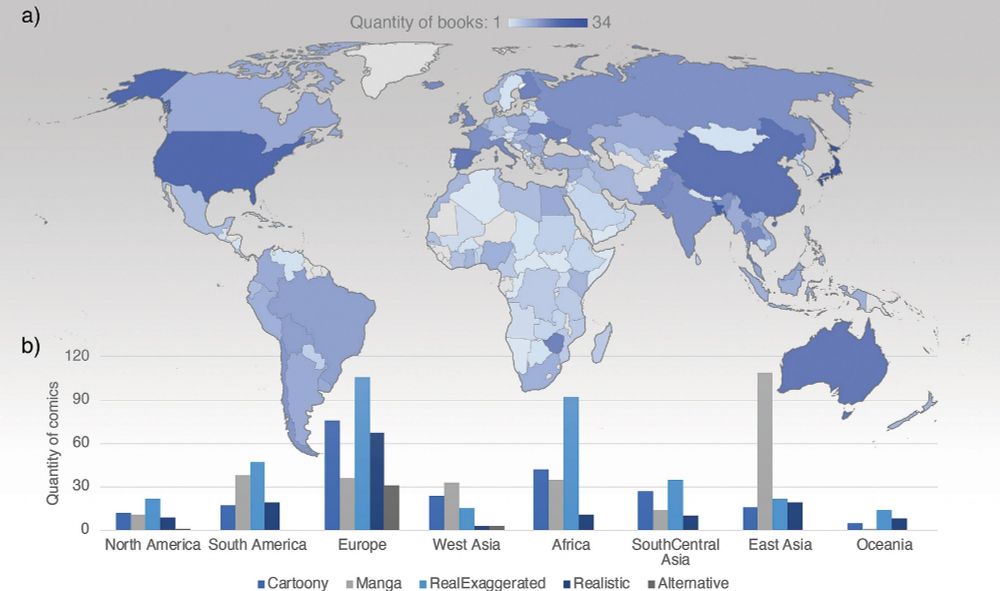
April 4, 2025 at 11:36 AM
I’m excited to share our newest paper which is the first to analyze all of our in our TINTIN Corpus: 1,030 comics from 144 countries. We asked: How much are comic layouts influenced by the writing systems of their authors? www.sciencedirect.com/science/arti...