




Rob Cavanaugh
@rbcavanaugh.bsky.social
Assistant Professor in quantitative methods @mghinstitute, speech-language pathologist by training. Enthusiastic about quantitative methods in rehabilitation research and health services research for aphasia. 🥾🏔️🦮🍕
Psychology adjacent here but Google scholar searches index article bodies; I’ve had some success searching something like “favorite journal name(s)” AND “lme4” AND “osf.io” AND “randomized”
December 15, 2025 at 1:02 PM
Psychology adjacent here but Google scholar searches index article bodies; I’ve had some success searching something like “favorite journal name(s)” AND “lme4” AND “osf.io” AND “randomized”
Reposted by Rob Cavanaugh

I'm teaching Statistical Rethinking again starting Jan 2026. This time with live lectures, divided into Beginner and Experienced sections. Will be a lot more work for me, but I hope much better for students.
I will record lectures & all will be found at this link: github.com/rmcelreath/s...
I will record lectures & all will be found at this link: github.com/rmcelreath/s...

December 9, 2025 at 1:58 PM
I'm teaching Statistical Rethinking again starting Jan 2026. This time with live lectures, divided into Beginner and Experienced sections. Will be a lot more work for me, but I hope much better for students.
I will record lectures & all will be found at this link: github.com/rmcelreath/s...
I will record lectures & all will be found at this link: github.com/rmcelreath/s...
Numerically. The same pp difference at baseline becomes very exaggerated in pomp terms as baseline scores improve.
December 9, 2025 at 2:04 PM
Numerically. The same pp difference at baseline becomes very exaggerated in pomp terms as baseline scores improve.
Right. 16.7 vs 20 in pomp terms even with the exact same % point gain. More exaggerated at the tails too. I’m skeptical that requiring those with worse baseline scores to improve more in %point terms to have the same pomp scores is a desirable measurement property in most circumstances.
December 9, 2025 at 12:34 PM
Right. 16.7 vs 20 in pomp terms even with the exact same % point gain. More exaggerated at the tails too. I’m skeptical that requiring those with worse baseline scores to improve more in %point terms to have the same pomp scores is a desirable measurement property in most circumstances.
Doesn’t pomp potentially conflate differences baseline ratings with group differences? Both groups could have similar improvements on the ordinal scale but quite different pomp scores if they start with different satisfaction ratings.
December 9, 2025 at 12:13 PM
Doesn’t pomp potentially conflate differences baseline ratings with group differences? Both groups could have similar improvements on the ordinal scale but quite different pomp scores if they start with different satisfaction ratings.
Or at least that using a linear model on an ordinal outcome risks mis-specifying the difference between men and women if the variances of their sleep satisfaction also differ.
December 9, 2025 at 11:55 AM
Or at least that using a linear model on an ordinal outcome risks mis-specifying the difference between men and women if the variances of their sleep satisfaction also differ.
Reposted by Rob Cavanaugh

Call for papers 👇👇👇🚨 clinicalaphasiologyconference.org/cac-2026/

CAC 2026
The 55th Clinical Aphasiology Conference Tuesday May 26th – Friday May 29th, 2026Sheraton Hotel at Station Square, Pittsburgh, Pennsylvania, USA The annual Clinical Aphasiology Conference (CA…
clinicalaphasiologyconference.org
December 4, 2025 at 12:12 PM
Call for papers 👇👇👇🚨 clinicalaphasiologyconference.org/cac-2026/
“The gang goes to city hall” in which the gang compete to fix a clerical error with the city. Mac and Dennis try to resolve the issue amicably at city hall. Dee tries secretly dating an officer of the liquor control board. Charlie and Frank hatch a plan to get Frank elected mayor.
December 2, 2025 at 12:19 AM
“The gang goes to city hall” in which the gang compete to fix a clerical error with the city. Mac and Dennis try to resolve the issue amicably at city hall. Dee tries secretly dating an officer of the liquor control board. Charlie and Frank hatch a plan to get Frank elected mayor.
For those unfamiliar: adding this fantastic recorded lecture on the topic from John Kruschke. media.dlib.indiana.edu/media_object...

Analyzing ordinal data with metric models: What could possibly go wrong? - Media Collections Online
media.dlib.indiana.edu
December 1, 2025 at 4:56 PM
For those unfamiliar: adding this fantastic recorded lecture on the topic from John Kruschke. media.dlib.indiana.edu/media_object...
Folks who teach stats to graduate students in applied fields - do you discuss ordinal methods in depth? The Liddell and Kruschke paper? (Analyzing ordinal data with metric models: What could possibly go wrong?)
What do you recommend to students who often use ordinal outcomes? #statssky
What do you recommend to students who often use ordinal outcomes? #statssky
December 1, 2025 at 4:56 PM
Folks who teach stats to graduate students in applied fields - do you discuss ordinal methods in depth? The Liddell and Kruschke paper? (Analyzing ordinal data with metric models: What could possibly go wrong?)
What do you recommend to students who often use ordinal outcomes? #statssky
What do you recommend to students who often use ordinal outcomes? #statssky
Reposted by Rob Cavanaugh
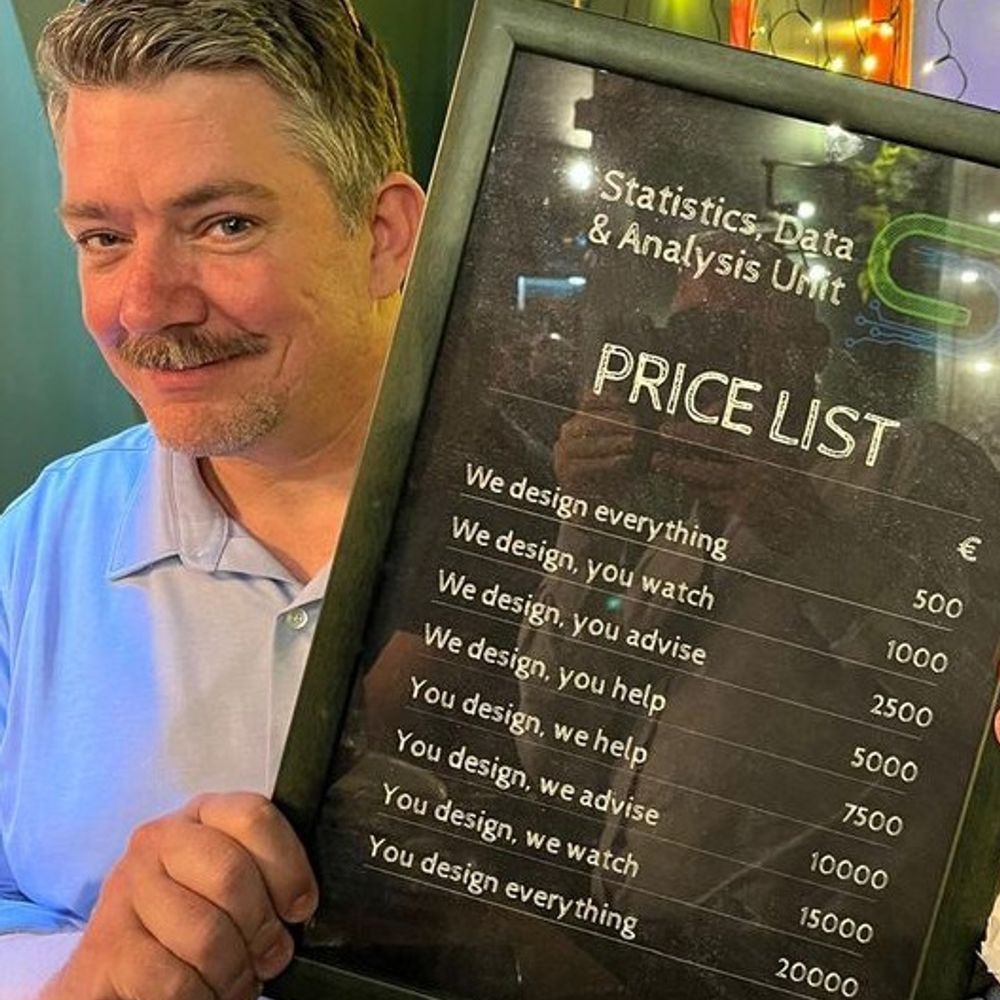

oh that is slick!
November 10, 2025 at 7:23 PM
oh that is slick!
I know it’s often not identifiable and challenging to fit but I get very nervous about the exclusion of the time|id random slope in these models based on the 2013 Barr paper.
November 10, 2025 at 7:08 PM
I know it’s often not identifiable and challenging to fit but I get very nervous about the exclusion of the time|id random slope in these models based on the 2013 Barr paper.
Oh you know I assumed you were plotting the RE estimates like this. If its just the observed data, probably min/max if few estimates/group and Q3/Q1 if many. You could probably even do tiny box plots if you didn't have too many groups.


October 28, 2025 at 9:57 PM
Oh you know I assumed you were plotting the RE estimates like this. If its just the observed data, probably min/max if few estimates/group and Q3/Q1 if many. You could probably even do tiny box plots if you didn't have too many groups.
I think to some extent the knee jerk reaction against the strong claim in the paper is due to the muddiness that (unfortunately) exists between prediction and causal claims. "Who is most as risk" as you state vs. why.
October 28, 2025 at 1:14 PM
I think to some extent the knee jerk reaction against the strong claim in the paper is due to the muddiness that (unfortunately) exists between prediction and causal claims. "Who is most as risk" as you state vs. why.
If they were bars it would be a caterpillar plot right? What about blupergram. Has a nice ring to it
October 28, 2025 at 11:25 AM
If they were bars it would be a caterpillar plot right? What about blupergram. Has a nice ring to it
Reposted by Rob Cavanaugh

We wrote an article explaining why you shouldn't put several variables into a regression model and report which are statistically significant - even as exploratory research. bmjmedicine.bmj.com/content/4/1/.... How did we do?

October 27, 2025 at 5:39 PM
We wrote an article explaining why you shouldn't put several variables into a regression model and report which are statistically significant - even as exploratory research. bmjmedicine.bmj.com/content/4/1/.... How did we do?
Pretty sure this is one of those sexy offers two very smart podcasters told me to run away from. So I’m going to say maybe 😂
October 24, 2025 at 12:05 AM
Pretty sure this is one of those sexy offers two very smart podcasters told me to run away from. So I’m going to say maybe 😂
Love it! Will you be sharing data? (You know… for those of us teaching stats to CSD PhD students struggling to find cool and salient datasets)
October 23, 2025 at 9:21 PM
Love it! Will you be sharing data? (You know… for those of us teaching stats to CSD PhD students struggling to find cool and salient datasets)
Reposted by Rob Cavanaugh
Monty Python understood p-hacking
October 23, 2025 at 8:43 AM
Monty Python understood p-hacking
In all fairness, glmer does spit out a warning about non integers.
October 22, 2025 at 7:32 PM
In all fairness, glmer does spit out a warning about non integers.
Anything can be an integer with round(x, 0)!
October 22, 2025 at 7:27 PM
Anything can be an integer with round(x, 0)!
I’m very curious about what the third one is doing. Modeling a proportion without weighting by the number of trials? Could this could be useful if the proportion is not built out of independent Bernoulli trials?
October 22, 2025 at 4:06 PM
I’m very curious about what the third one is doing. Modeling a proportion without weighting by the number of trials? Could this could be useful if the proportion is not built out of independent Bernoulli trials?
Reposted by Rob Cavanaugh

We need to have a conversation about random seeds. Don't use 42.
blog.genesmindsmachines.com/p/if-your-ra...
blog.genesmindsmachines.com/p/if-your-ra...
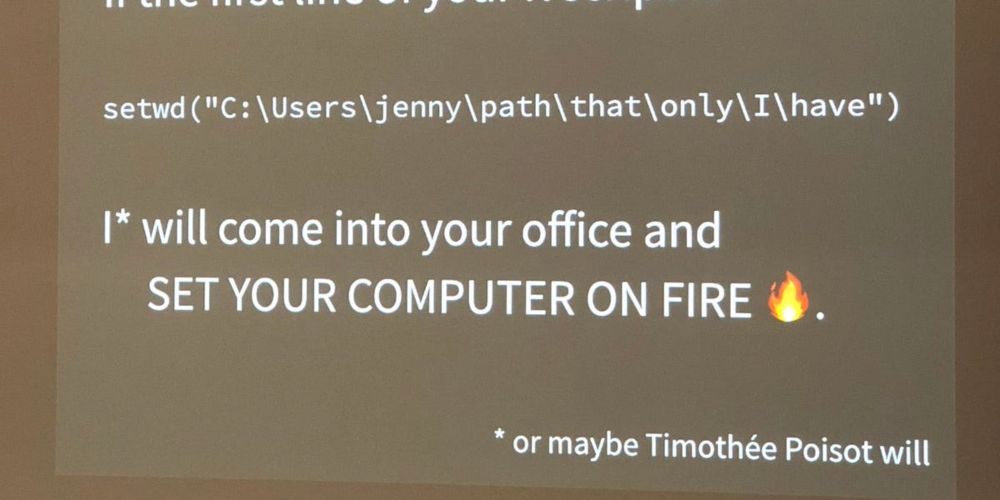
If your random seed is 42 I will come to your office and set your computer on fire🔥
Figuratively. More likely you'll get a stern talking to.
blog.genesmindsmachines.com
October 22, 2025 at 12:49 PM
We need to have a conversation about random seeds. Don't use 42.
blog.genesmindsmachines.com/p/if-your-ra...
blog.genesmindsmachines.com/p/if-your-ra...
Any #rstats folks know the differences in lme4::glmer()'s specification for aggregated binomials? (or reading rec's?) I'd like to confirm my understanding of these:
cbind(successes, failures) ~ ...
successes/trials ~ ..., weights = trials
successes/trials ~ ..., weights = NULL (or unspecified)
cbind(successes, failures) ~ ...
successes/trials ~ ..., weights = trials
successes/trials ~ ..., weights = NULL (or unspecified)
October 22, 2025 at 2:42 PM
Any #rstats folks know the differences in lme4::glmer()'s specification for aggregated binomials? (or reading rec's?) I'd like to confirm my understanding of these:
cbind(successes, failures) ~ ...
successes/trials ~ ..., weights = trials
successes/trials ~ ..., weights = NULL (or unspecified)
cbind(successes, failures) ~ ...
successes/trials ~ ..., weights = trials
successes/trials ~ ..., weights = NULL (or unspecified)