




Quanquan Gu
@quanquangu.bsky.social
Professor @UCLA, Research Scientist @ByteDance | Recent work: SPIN, SPPO, DPLM 1/2, GPM, MARS | Opinions are my own
Reposted by Quanquan Gu

Papers #2-3: arxiv.org/abs/2402.10210 and arxiv.org/abs/2405.00675 from the incredible
@quanquangu.bsky.social. I really like how they explore new techniques for RLHF
@quanquangu.bsky.social. I really like how they explore new techniques for RLHF

Self-Play Fine-Tuning of Diffusion Models for Text-to-Image Generation
Fine-tuning Diffusion Models remains an underexplored frontier in generative artificial intelligence (GenAI), especially when compared with the remarkable progress made in fine-tuning Large Language M...
arxiv.org
December 20, 2024 at 4:53 PM
Papers #2-3: arxiv.org/abs/2402.10210 and arxiv.org/abs/2405.00675 from the incredible
@quanquangu.bsky.social. I really like how they explore new techniques for RLHF
@quanquangu.bsky.social. I really like how they explore new techniques for RLHF
Pretraining will only end once we find the optimal scaling law.
December 14, 2024 at 8:07 AM
Pretraining will only end once we find the optimal scaling law.
With the delivery of MARS complete, the focus now shifts to delivering new architectures.
GitHub - AGI-Arena/MARS: The official implementation of MARS: Unleashing the Power of Variance Reduction for Training Large Models
The official implementation of MARS: Unleashing the Power of Variance Reduction for Training Large Models - AGI-Arena/MARS
buff.ly
December 3, 2024 at 11:48 PM
With the delivery of MARS complete, the focus now shifts to delivering new architectures.
This Thanksgiving, I want to express my heartfelt gratitude to all the students, colleagues, and collaborators who have contributed to the success of SPIN, SPPO, DPLM, GPM, MARS, and many other projects. Your hard work and dedication continue to be truly inspiring.
November 29, 2024 at 3:22 AM
This Thanksgiving, I want to express my heartfelt gratitude to all the students, colleagues, and collaborators who have contributed to the success of SPIN, SPPO, DPLM, GPM, MARS, and many other projects. Your hard work and dedication continue to be truly inspiring.
Please reply to this message or DM me if you’d like to be added!
Just put together a starter pack for Deep Learning Theory. Let me know if you'd like to be included or suggest someone to add to the list!
go.bsky.app/2qnppia
go.bsky.app/2qnppia
November 27, 2024 at 8:48 PM
Please reply to this message or DM me if you’d like to be added!
Reposted by Quanquan Gu

Tulu 3 SFT mix trending on HuggingFace :D , next step make preferences and RL datasets more accessible.
November 26, 2024 at 4:57 PM
Tulu 3 SFT mix trending on HuggingFace :D , next step make preferences and RL datasets more accessible.
Reposted by Quanquan Gu

OLMo 2 is out 🥳 7B and 13B trained on 5T tokens, and meticulousy instruction tuned using Tulu 3 recipe.
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
November 26, 2024 at 9:12 PM
OLMo 2 is out 🥳 7B and 13B trained on 5T tokens, and meticulousy instruction tuned using Tulu 3 recipe.
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
Reposted by Quanquan Gu

Scene thru my window, today, Pittsburgh.

November 26, 2024 at 3:58 AM
Scene thru my window, today, Pittsburgh.


Reposted by Quanquan Gu

PSGD ❤️ MARS
MARS is a new exciting variance reduction technique from @quanquangu.bsky.social 's group which can help stabilize and accelerate your deep learning pipeline. All that is needed is a gradient buffer. Here MARS speeds up the convergence of PSGD ultimately leading to a better solution.
MARS is a new exciting variance reduction technique from @quanquangu.bsky.social 's group which can help stabilize and accelerate your deep learning pipeline. All that is needed is a gradient buffer. Here MARS speeds up the convergence of PSGD ultimately leading to a better solution.

November 26, 2024 at 4:21 AM
PSGD ❤️ MARS
MARS is a new exciting variance reduction technique from @quanquangu.bsky.social 's group which can help stabilize and accelerate your deep learning pipeline. All that is needed is a gradient buffer. Here MARS speeds up the convergence of PSGD ultimately leading to a better solution.
MARS is a new exciting variance reduction technique from @quanquangu.bsky.social 's group which can help stabilize and accelerate your deep learning pipeline. All that is needed is a gradient buffer. Here MARS speeds up the convergence of PSGD ultimately leading to a better solution.
Reposted by Quanquan Gu

Deep learning theory has arrived (on blue sky)!
Just put together a starter pack for Deep Learning Theory. Let me know if you'd like to be included or suggest someone to add to the list!
go.bsky.app/2qnppia
go.bsky.app/2qnppia
November 26, 2024 at 12:41 AM
Deep learning theory has arrived (on blue sky)!
Reposted by Quanquan Gu

Tomorrow at 6 PM UTC, Asaf Cassel will talk about "Warm-Up Free Policy Optimization: Improved Regret in Linear Markov Decision Processes".

November 25, 2024 at 10:00 PM
Tomorrow at 6 PM UTC, Asaf Cassel will talk about "Warm-Up Free Policy Optimization: Improved Regret in Linear Markov Decision Processes".
Reposted by Quanquan Gu
We are on Bluesky as well! We will keep posting on both X and here.
November 25, 2024 at 9:57 PM
We are on Bluesky as well! We will keep posting on both X and here.
Reposted by Quanquan Gu
Just created the Starter Pack for Optimization Researchers to help you on your journey into optimization! 🚀
Did I miss anyone? Tag them or let me know what to add!
go.bsky.app/VjpyyRw
Did I miss anyone? Tag them or let me know what to add!
go.bsky.app/VjpyyRw
November 23, 2024 at 11:59 PM
Just created the Starter Pack for Optimization Researchers to help you on your journey into optimization! 🚀
Did I miss anyone? Tag them or let me know what to add!
go.bsky.app/VjpyyRw
Did I miss anyone? Tag them or let me know what to add!
go.bsky.app/VjpyyRw
Reposted by Quanquan Gu

The Oregon coast is incredibly beautiful




November 24, 2024 at 9:11 PM
The Oregon coast is incredibly beautiful
Reposted by Quanquan Gu

Join us tomorrow for the:
AI for Science summit.
In person places are full, but you can still join us online (click on the below to sign up).
science.ai.cam.ac.uk/events/ai-fo...
AI for Science summit.
In person places are full, but you can still join us online (click on the below to sign up).
science.ai.cam.ac.uk/events/ai-fo...

AI for Science Summit 2024
On Monday 25 and Tuesday 26 November the Accelerate Programme for Scientific Discovery are inviting members of the AI for Science community to attend an AI for Science Summit, bringing together our co...
science.ai.cam.ac.uk
November 24, 2024 at 4:14 PM
Join us tomorrow for the:
AI for Science summit.
In person places are full, but you can still join us online (click on the below to sign up).
science.ai.cam.ac.uk/events/ai-fo...
AI for Science summit.
In person places are full, but you can still join us online (click on the below to sign up).
science.ai.cam.ac.uk/events/ai-fo...
Reposted by Quanquan Gu
In addition to the Deep Learning Theory starter pack, I've also put together a starter pack for Reinforcement Learning Theory. Let me know if you'd like to be included or suggest someone to add to the list!
go.bsky.app/LWyGAAu
go.bsky.app/LWyGAAu
November 22, 2024 at 9:56 PM
In addition to the Deep Learning Theory starter pack, I've also put together a starter pack for Reinforcement Learning Theory. Let me know if you'd like to be included or suggest someone to add to the list!
go.bsky.app/LWyGAAu
go.bsky.app/LWyGAAu
Graduate school application season is here again, and I just spent the whole weekend writing a few letters! 🎓 When submitting, many schools still require overly detailed forms filled with endless questions and checkboxes. Isn’t it time to simplify this process and focus on what truly matters?
November 25, 2024 at 2:39 AM
Graduate school application season is here again, and I just spent the whole weekend writing a few letters! 🎓 When submitting, many schools still require overly detailed forms filled with endless questions and checkboxes. Isn’t it time to simplify this process and focus on what truly matters?
A gentle reminder to @iclr-conf.bsky.social authors: your revision must not exceed 10 pages, adhering to the same requirements as the original submission.
November 25, 2024 at 2:01 AM
A gentle reminder to @iclr-conf.bsky.social authors: your revision must not exceed 10 pages, adhering to the same requirements as the original submission.
Reposted by Quanquan Gu

This is accurate af

November 24, 2024 at 9:07 PM
This is accurate af
Reposted by Quanquan Gu
Just put together a starter pack for Deep Learning Theory. Let me know if you'd like to be included or suggest someone to add to the list!
go.bsky.app/2qnppia
go.bsky.app/2qnppia
November 22, 2024 at 9:35 PM
Just put together a starter pack for Deep Learning Theory. Let me know if you'd like to be included or suggest someone to add to the list!
go.bsky.app/2qnppia
go.bsky.app/2qnppia
Reposted by Quanquan Gu

RLC will be held at the Univ. of Alberta, Edmonton, in 2025. I'm happy to say that we now have the conference's website out: rl-conference.cc/index.html
Looking forward to seeing you all there!
@rl-conference.bsky.social
#reinforcementlearning
Looking forward to seeing you all there!
@rl-conference.bsky.social
#reinforcementlearning
November 22, 2024 at 10:46 PM
RLC will be held at the Univ. of Alberta, Edmonton, in 2025. I'm happy to say that we now have the conference's website out: rl-conference.cc/index.html
Looking forward to seeing you all there!
@rl-conference.bsky.social
#reinforcementlearning
Looking forward to seeing you all there!
@rl-conference.bsky.social
#reinforcementlearning
Reposted by Quanquan Gu

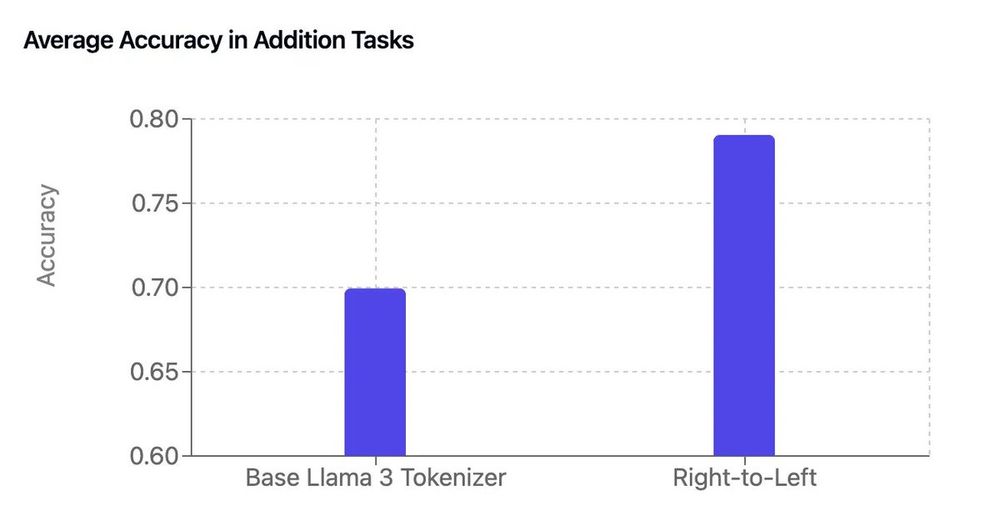
It's Sunday morning so taking a minute for a nerdy thread (on math, tokenizers and LLMs) of the work of our intern Garreth
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
November 24, 2024 at 11:05 AM
It's Sunday morning so taking a minute for a nerdy thread (on math, tokenizers and LLMs) of the work of our intern Garreth
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
Reposted by Quanquan Gu

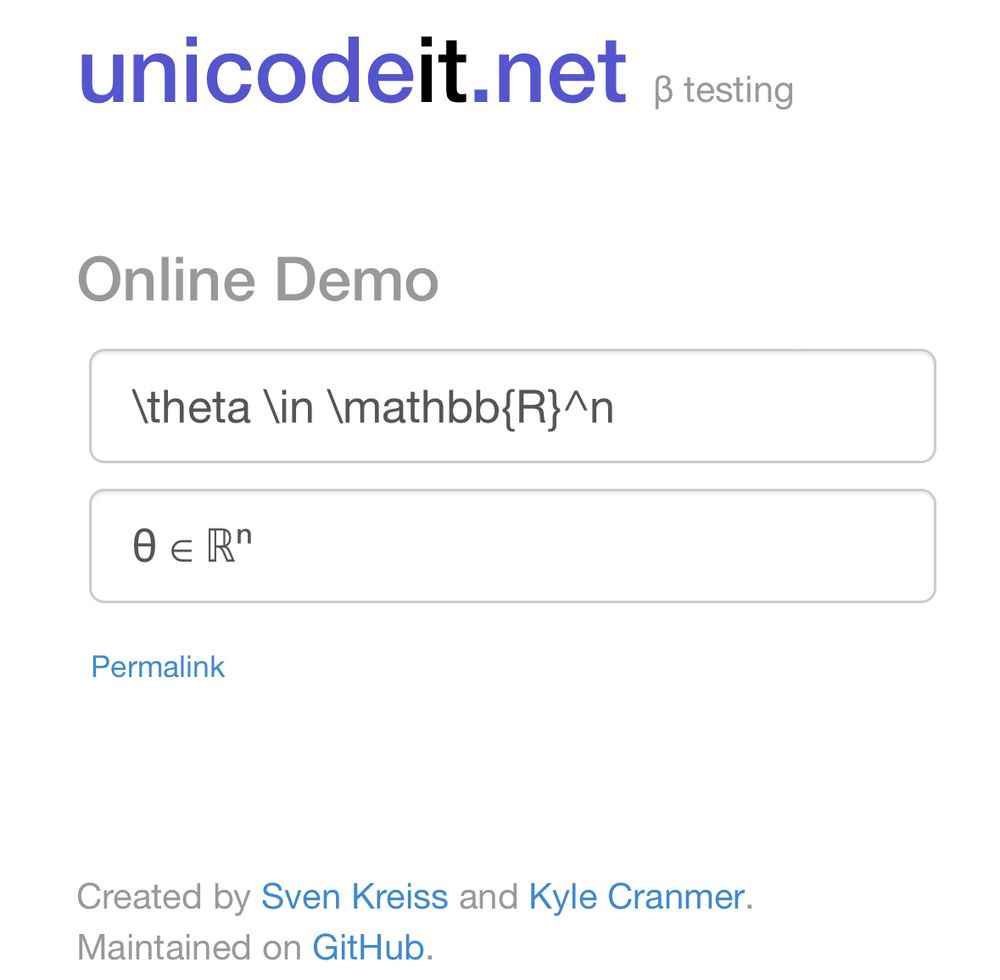
Write math on 🦋 with UnicodeIt!
For example: θ ∈ ℝⁿ or pp̅ → μ⁺μ⁻
Use website or install system-wide in Linux, macOS, or windows
www.unicodeit.net
(Created several years ago with @svenkreiss.bsky.social)
For example: θ ∈ ℝⁿ or pp̅ → μ⁺μ⁻
Use website or install system-wide in Linux, macOS, or windows
www.unicodeit.net
(Created several years ago with @svenkreiss.bsky.social)
November 23, 2024 at 9:34 PM
Write math on 🦋 with UnicodeIt!
For example: θ ∈ ℝⁿ or pp̅ → μ⁺μ⁻
Use website or install system-wide in Linux, macOS, or windows
www.unicodeit.net
(Created several years ago with @svenkreiss.bsky.social)
For example: θ ∈ ℝⁿ or pp̅ → μ⁺μ⁻
Use website or install system-wide in Linux, macOS, or windows
www.unicodeit.net
(Created several years ago with @svenkreiss.bsky.social)
Reposted by Quanquan Gu

I’m increasingly unsure there are specific rules/laws for pretraining schedule except that peak LR instability means that you need a warmup and a cooldown. And in the post-Chinchilla era you probably want to slow cook the model (so go easy on lr, smooth the schedule).
November 23, 2024 at 3:28 PM
I’m increasingly unsure there are specific rules/laws for pretraining schedule except that peak LR instability means that you need a warmup and a cooldown. And in the post-Chinchilla era you probably want to slow cook the model (so go easy on lr, smooth the schedule).