



Paul Bürkner
@paulbuerkner.com
Full Professor of Computational Statistics at TU Dortmund University
Scientist | Statistician | Bayesian | Author of brms | Member of the Stan and BayesFlow development teams
Website: https://paulbuerkner.com
Opinions are my own
Scientist | Statistician | Bayesian | Author of brms | Member of the Stan and BayesFlow development teams
Website: https://paulbuerkner.com
Opinions are my own
Reposted by Paul Bürkner

I defended my PhD last week ✨
Huge thanks to:
• My supervisors @paulbuerkner.com @stefanradev.bsky.social @avehtari.bsky.social 👥
• The committee @ststaab.bsky.social @mniepert.bsky.social 📝
• The institutions @ellis.eu @unistuttgart.bsky.social @aalto.fi 🏫
• My wonderful collaborators 🧡
#PhDone 🎓
Huge thanks to:
• My supervisors @paulbuerkner.com @stefanradev.bsky.social @avehtari.bsky.social 👥
• The committee @ststaab.bsky.social @mniepert.bsky.social 📝
• The institutions @ellis.eu @unistuttgart.bsky.social @aalto.fi 🏫
• My wonderful collaborators 🧡
#PhDone 🎓

March 27, 2025 at 6:31 PM
I defended my PhD last week ✨
Huge thanks to:
• My supervisors @paulbuerkner.com @stefanradev.bsky.social @avehtari.bsky.social 👥
• The committee @ststaab.bsky.social @mniepert.bsky.social 📝
• The institutions @ellis.eu @unistuttgart.bsky.social @aalto.fi 🏫
• My wonderful collaborators 🧡
#PhDone 🎓
Huge thanks to:
• My supervisors @paulbuerkner.com @stefanradev.bsky.social @avehtari.bsky.social 👥
• The committee @ststaab.bsky.social @mniepert.bsky.social 📝
• The institutions @ellis.eu @unistuttgart.bsky.social @aalto.fi 🏫
• My wonderful collaborators 🧡
#PhDone 🎓
Reposted by Paul Bürkner

What advice do folks have for organising projects that will be deployed to production? How do you organise your directories? What do you do if you're deploying multiple "things" (e.g. an app and an api) from the same project?
February 27, 2025 at 2:15 PM
What advice do folks have for organising projects that will be deployed to production? How do you organise your directories? What do you do if you're deploying multiple "things" (e.g. an app and an api) from the same project?
Reposted by Paul Bürkner
Amortized inference for finite mixture models ✨
The amortized approximator from BayesFlow closely matches the results of expensive-but-trustworthy HMC with Stan.
Check out the preprint and code by @kucharssim.bsky.social and @paulbuerkner.com👇
The amortized approximator from BayesFlow closely matches the results of expensive-but-trustworthy HMC with Stan.
Check out the preprint and code by @kucharssim.bsky.social and @paulbuerkner.com👇
February 11, 2025 at 8:53 AM
Amortized inference for finite mixture models ✨
The amortized approximator from BayesFlow closely matches the results of expensive-but-trustworthy HMC with Stan.
Check out the preprint and code by @kucharssim.bsky.social and @paulbuerkner.com👇
The amortized approximator from BayesFlow closely matches the results of expensive-but-trustworthy HMC with Stan.
Check out the preprint and code by @kucharssim.bsky.social and @paulbuerkner.com👇
Reposted by Paul Bürkner

Finite mixture models are useful when data comes from multiple latent processes.
BayesFlow allows:
• Approximating the joint posterior of model parameters and mixture indicators
• Inferences for independent and dependent mixtures
• Amortization for fast and accurate estimation
📄 Preprint
💻 Code
BayesFlow allows:
• Approximating the joint posterior of model parameters and mixture indicators
• Inferences for independent and dependent mixtures
• Amortization for fast and accurate estimation
📄 Preprint
💻 Code
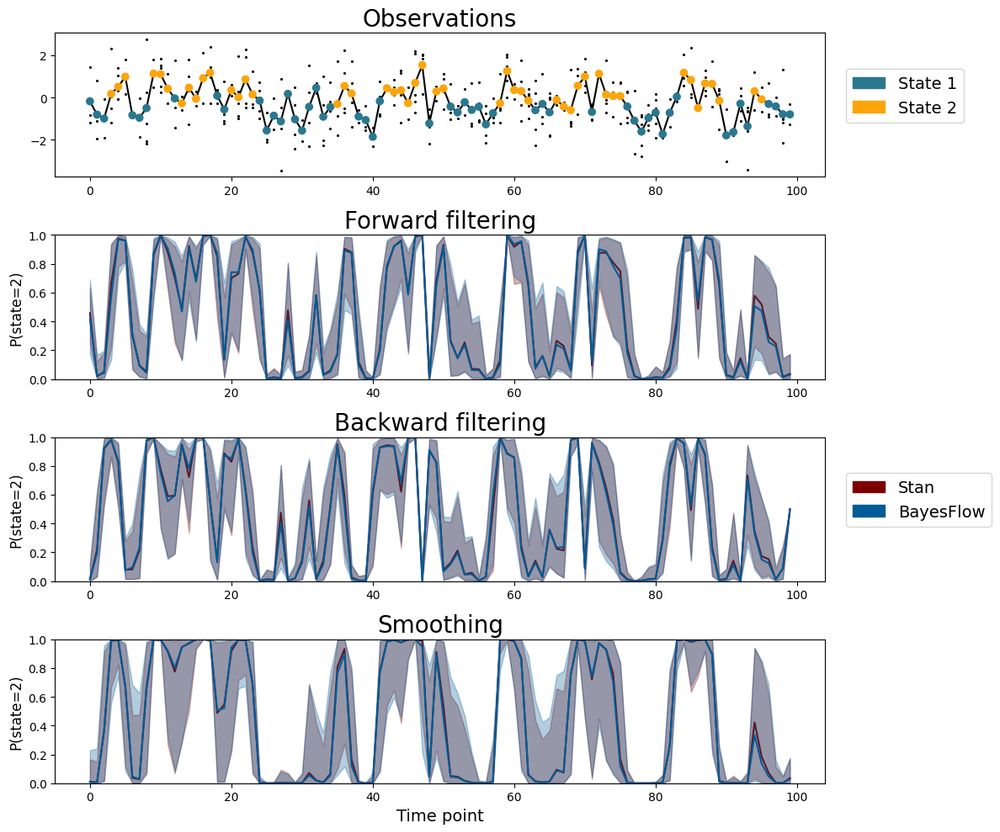
February 11, 2025 at 8:48 AM
Reposted by Paul Bürkner

If you know simulation based calibration checking (SBC), you will enjoy our new paper "Posterior SBC: Simulation-Based Calibration Checking Conditional on Data" with Teemu Säilynoja, @marvinschmitt.com and @paulbuerkner.com
arxiv.org/abs/2502.03279 1/7
arxiv.org/abs/2502.03279 1/7

February 6, 2025 at 10:11 AM
If you know simulation based calibration checking (SBC), you will enjoy our new paper "Posterior SBC: Simulation-Based Calibration Checking Conditional on Data" with Teemu Säilynoja, @marvinschmitt.com and @paulbuerkner.com
arxiv.org/abs/2502.03279 1/7
arxiv.org/abs/2502.03279 1/7
Reposted by Paul Bürkner
A study with 5M+ data points explores the link between cognitive parameters and socioeconomic outcomes: The stability of processing speed was the strongest predictor.
BayesFlow facilitated efficient inference for complex decision-making models, scaling Bayesian workflows to big data.
🔗Paper
BayesFlow facilitated efficient inference for complex decision-making models, scaling Bayesian workflows to big data.
🔗Paper
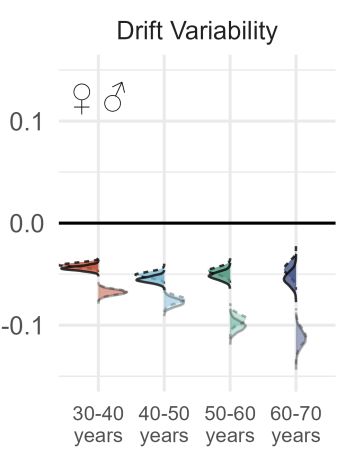
February 3, 2025 at 12:21 PM
A study with 5M+ data points explores the link between cognitive parameters and socioeconomic outcomes: The stability of processing speed was the strongest predictor.
BayesFlow facilitated efficient inference for complex decision-making models, scaling Bayesian workflows to big data.
🔗Paper
BayesFlow facilitated efficient inference for complex decision-making models, scaling Bayesian workflows to big data.
🔗Paper
Reposted by Paul Bürkner
Join us this Thursday for a talk on efficient mixture and multilevel models with neural networks by @paulbuerkner.com at the new @approxbayesseminar.bsky.social!
A reminder of our talk this Thursday (30th Jan), at 11am GMT. Paul Bürkner (TU Dortmund University), will talk about "Amortized Mixture and Multilevel Models". Sign up at listserv.csv.warwick... to receive the link.
January 28, 2025 at 5:06 AM
Join us this Thursday for a talk on efficient mixture and multilevel models with neural networks by @paulbuerkner.com at the new @approxbayesseminar.bsky.social!
Reposted by Paul Bürkner

Paul Bürkner (TU Dortmund University), will give our next talk. This will be about "Amortized Mixture and Multilevel Models", and is scheduled on Thursday the 30th January at 11am. To receive the link to join, sign up at listserv.csv.warwick...
January 14, 2025 at 12:00 PM
Paul Bürkner (TU Dortmund University), will give our next talk. This will be about "Amortized Mixture and Multilevel Models", and is scheduled on Thursday the 30th January at 11am. To receive the link to join, sign up at listserv.csv.warwick...
Reposted by Paul Bürkner
Paul Bürkner (@paulbuerkner.com) will talk about amortized Bayesian multilevel models in the next Approximate Bayes Seminar on January 30 ⭐️
Sign up to the seminar’s mailing list below to get the meeting link 👇
Sign up to the seminar’s mailing list below to get the meeting link 👇
Paul Bürkner (TU Dortmund University), will give our next talk. This will be about "Amortized Mixture and Multilevel Models", and is scheduled on Thursday the 30th January at 11am. To receive the link to join, sign up at listserv.csv.warwick...
January 14, 2025 at 12:43 PM
Paul Bürkner (@paulbuerkner.com) will talk about amortized Bayesian multilevel models in the next Approximate Bayes Seminar on January 30 ⭐️
Sign up to the seminar’s mailing list below to get the meeting link 👇
Sign up to the seminar’s mailing list below to get the meeting link 👇
Reposted by Paul Bürkner

More than 60 German universities and research outfits are announcing that they will end their activities on twitter.
Including my alma mater, the University of Münster.
HT @thereallorenzmeyer.bsky.social nachrichten.idw-online.de/2025/01/10/h...
Including my alma mater, the University of Münster.
HT @thereallorenzmeyer.bsky.social nachrichten.idw-online.de/2025/01/10/h...

Hochschulen und Forschungsinstitutionen verlassen Plattform X - Gemeinsam für Vielfalt, Freiheit und Wissenschaft
nachrichten.idw-online.de
January 10, 2025 at 12:02 PM
More than 60 German universities and research outfits are announcing that they will end their activities on twitter.
Including my alma mater, the University of Münster.
HT @thereallorenzmeyer.bsky.social nachrichten.idw-online.de/2025/01/10/h...
Including my alma mater, the University of Münster.
HT @thereallorenzmeyer.bsky.social nachrichten.idw-online.de/2025/01/10/h...
Reposted by Paul Bürkner

what are your best tips to fit shifted lognormal models (in #brms / Stan)? I'm using:
- checking the long tails (few long RTs make the tail estimation unwieldy)
- low initial values for ndt
- careful prior checks
- pathfinder estimation of initial values
still with increasing data, chains get stuck
- checking the long tails (few long RTs make the tail estimation unwieldy)
- low initial values for ndt
- careful prior checks
- pathfinder estimation of initial values
still with increasing data, chains get stuck
January 10, 2025 at 10:43 AM
what are your best tips to fit shifted lognormal models (in #brms / Stan)? I'm using:
- checking the long tails (few long RTs make the tail estimation unwieldy)
- low initial values for ndt
- careful prior checks
- pathfinder estimation of initial values
still with increasing data, chains get stuck
- checking the long tails (few long RTs make the tail estimation unwieldy)
- low initial values for ndt
- careful prior checks
- pathfinder estimation of initial values
still with increasing data, chains get stuck
Reposted by Paul Bürkner

OK, here is a very rough draft of a tutorial for #Bayesian #SEM using #brms for #rstats. It needs work, polish, has a lot of questions in it, and I need to add a references section. But, I think a lot of folk will find this useful, so.... jebyrnes.github.io/bayesian_sem... (use issues for comments!)
Full Luxury Bayesian Structural Equation Modeling with brms
jebyrnes.github.io
December 21, 2024 at 7:49 PM
OK, here is a very rough draft of a tutorial for #Bayesian #SEM using #brms for #rstats. It needs work, polish, has a lot of questions in it, and I need to add a references section. But, I think a lot of folk will find this useful, so.... jebyrnes.github.io/bayesian_sem... (use issues for comments!)
Reposted by Paul Bürkner

December 17, 2024 at 11:09 PM
Reposted by Paul Bürkner

Writing is thinking.
It’s not a part of the process that can be skipped; it’s the entire point.
It’s not a part of the process that can be skipped; it’s the entire point.

This is what's so baffling about so many suggestions for AI in the humanities classroom: they mistake the product for the point. Writing outlines and essays is important not because you need to make outlines and essays but because that's how you learn to think with/through complex ideas.

I'm sure many have said this before but I'm reading a student-facing document about how students might use AI in the classroom (if allowed) and one of the recs is: use AI to make an outline of your reading! But ISN'T MAKING THE OUTLINE how one actually learns?
December 12, 2024 at 3:08 PM
Writing is thinking.
It’s not a part of the process that can be skipped; it’s the entire point.
It’s not a part of the process that can be skipped; it’s the entire point.
Reposted by Paul Bürkner
1️⃣ An agent-based model simulates a dynamic population of professional speed climbers.
2️⃣ BayesFlow handles amortized parameter estimation in the SBI setting.
📣 Shoutout to @masonyoungblood.bsky.social & @sampassmore.bsky.social
📄 Preprint: osf.io/preprints/ps...
💻 Code: github.com/masonyoungbl...
2️⃣ BayesFlow handles amortized parameter estimation in the SBI setting.
📣 Shoutout to @masonyoungblood.bsky.social & @sampassmore.bsky.social
📄 Preprint: osf.io/preprints/ps...
💻 Code: github.com/masonyoungbl...

December 10, 2024 at 1:34 AM
1️⃣ An agent-based model simulates a dynamic population of professional speed climbers.
2️⃣ BayesFlow handles amortized parameter estimation in the SBI setting.
📣 Shoutout to @masonyoungblood.bsky.social & @sampassmore.bsky.social
📄 Preprint: osf.io/preprints/ps...
💻 Code: github.com/masonyoungbl...
2️⃣ BayesFlow handles amortized parameter estimation in the SBI setting.
📣 Shoutout to @masonyoungblood.bsky.social & @sampassmore.bsky.social
📄 Preprint: osf.io/preprints/ps...
💻 Code: github.com/masonyoungbl...
Reposted by Paul Bürkner
Neural superstatistics are a framework for probabilistic models with time-varying parameters:
⋅ Joint estimation of stationary and time-varying parameters
⋅ Amortized parameter inference and model comparison
⋅ Multi-horizon predictions and leave-future-out CV
📄 Paper 1
📄 Paper 2
💻 BayesFlow Code
⋅ Joint estimation of stationary and time-varying parameters
⋅ Amortized parameter inference and model comparison
⋅ Multi-horizon predictions and leave-future-out CV
📄 Paper 1
📄 Paper 2
💻 BayesFlow Code
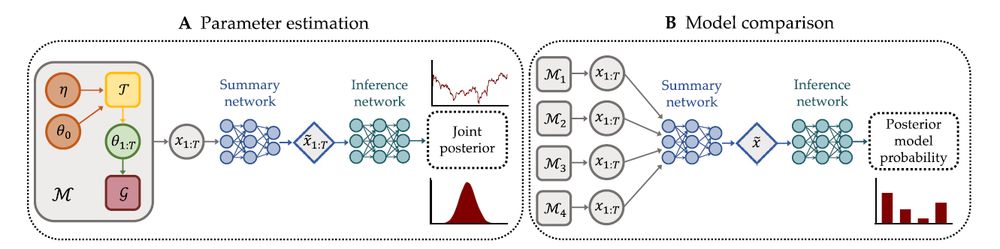
December 6, 2024 at 12:21 PM
Neural superstatistics are a framework for probabilistic models with time-varying parameters:
⋅ Joint estimation of stationary and time-varying parameters
⋅ Amortized parameter inference and model comparison
⋅ Multi-horizon predictions and leave-future-out CV
📄 Paper 1
📄 Paper 2
💻 BayesFlow Code
⋅ Joint estimation of stationary and time-varying parameters
⋅ Amortized parameter inference and model comparison
⋅ Multi-horizon predictions and leave-future-out CV
📄 Paper 1
📄 Paper 2
💻 BayesFlow Code
Reposted by Paul Bürkner

“We don’t value software, data, and methods in the same way we value papers, even though those resources empower millions of scientists” 💯
www.statnews.com/sponsor/2024...
www.statnews.com/sponsor/2024...

New report highlights the scientific impact of open source software
Two of the scientists who won this year’s Nobel Prize for cracking the code of proteins’ intricate structures relied, in part, on a series of computing
www.statnews.com
December 4, 2024 at 12:08 AM
“We don’t value software, data, and methods in the same way we value papers, even though those resources empower millions of scientists” 💯
www.statnews.com/sponsor/2024...
www.statnews.com/sponsor/2024...
Reposted by Paul Bürkner

The public beta version of Positron was released almost 6 months ago, and the team certainly hasn’t been idle! So what happened over the last half year? Is it worth switching? 👀
I definitely like where it's heading!
Personal highlights: data explorer, command palette, help on hover + extensions 👇🏻📚
I definitely like where it's heading!
Personal highlights: data explorer, command palette, help on hover + extensions 👇🏻📚
December 3, 2024 at 12:38 PM
The public beta version of Positron was released almost 6 months ago, and the team certainly hasn’t been idle! So what happened over the last half year? Is it worth switching? 👀
I definitely like where it's heading!
Personal highlights: data explorer, command palette, help on hover + extensions 👇🏻📚
I definitely like where it's heading!
Personal highlights: data explorer, command palette, help on hover + extensions 👇🏻📚
Reposted by Paul Bürkner

I'm going to have time to do 1-2 contributions for the summer 25 release. Here's my list to choose from, what is most interesting to you?
- adding lower/upper bounds to ordered vectors (removing positive ordered since it's achieved by lb=0)
- adding lower/upper bounds to ordered vectors (removing positive ordered since it's achieved by lb=0)
A new release of Stan is coming discourse.mc-stan.org/t/cmdstan-st....
Highlights:
New constraints for stochastic matrices and zero-sum vectors
Easier user-defined constraints
Improved diagnostics
New distribution, beta_negative_binomial
Highlights:
New constraints for stochastic matrices and zero-sum vectors
Easier user-defined constraints
Improved diagnostics
New distribution, beta_negative_binomial

CmdStan & Stan 2.36 release candidate
I am happy to announce that the latest release candidates of CmdStan and Stan are now available on Github! This release cycle brings new constrained types, improved diagnostics, and a new distributio...
discourse.mc-stan.org
December 2, 2024 at 11:46 AM
I'm going to have time to do 1-2 contributions for the summer 25 release. Here's my list to choose from, what is most interesting to you?
- adding lower/upper bounds to ordered vectors (removing positive ordered since it's achieved by lb=0)
- adding lower/upper bounds to ordered vectors (removing positive ordered since it's achieved by lb=0)
Prior specification is one of the hardest tasks in Bayesian modeling.
In our new paper, we (Florence Bockting, @stefanradev.bsky.social and me) develop a method for expert prior elicitation using generative neural networks and simulation-based learning.
arxiv.org/abs/2411.15826
In our new paper, we (Florence Bockting, @stefanradev.bsky.social and me) develop a method for expert prior elicitation using generative neural networks and simulation-based learning.
arxiv.org/abs/2411.15826

Expert-elicitation method for non-parametric joint priors using normalizing flows
We propose an expert-elicitation method for learning non-parametric joint prior distributions using normalizing flows. Normalizing flows are a class of generative models that enable exact, single-step...
arxiv.org
November 26, 2024 at 7:11 AM
Prior specification is one of the hardest tasks in Bayesian modeling.
In our new paper, we (Florence Bockting, @stefanradev.bsky.social and me) develop a method for expert prior elicitation using generative neural networks and simulation-based learning.
arxiv.org/abs/2411.15826
In our new paper, we (Florence Bockting, @stefanradev.bsky.social and me) develop a method for expert prior elicitation using generative neural networks and simulation-based learning.
arxiv.org/abs/2411.15826
Reposted by Paul Bürkner
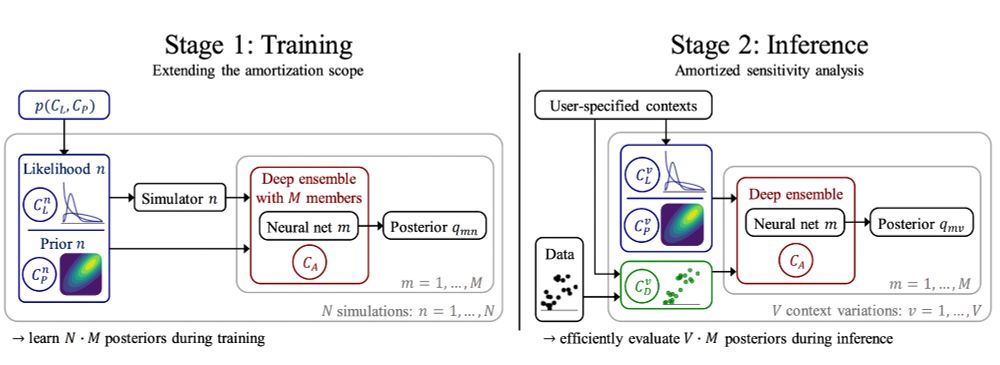
Any single analysis hides an iceberg of uncertainty.
Sensitivity-aware amortized inference explores the iceberg:
⋅ Test alternative priors, likelihoods, and data perturbations
⋅ Deep ensembles flag misspecification issues
⋅ No model refits required during inference
🔗 openreview.net/forum?id=Kxt...
Sensitivity-aware amortized inference explores the iceberg:
⋅ Test alternative priors, likelihoods, and data perturbations
⋅ Deep ensembles flag misspecification issues
⋅ No model refits required during inference
🔗 openreview.net/forum?id=Kxt...
November 25, 2024 at 10:52 AM
Any single analysis hides an iceberg of uncertainty.
Sensitivity-aware amortized inference explores the iceberg:
⋅ Test alternative priors, likelihoods, and data perturbations
⋅ Deep ensembles flag misspecification issues
⋅ No model refits required during inference
🔗 openreview.net/forum?id=Kxt...
Sensitivity-aware amortized inference explores the iceberg:
⋅ Test alternative priors, likelihoods, and data perturbations
⋅ Deep ensembles flag misspecification issues
⋅ No model refits required during inference
🔗 openreview.net/forum?id=Kxt...
Reposted by Paul Bürkner

I feel like not enough people know about Quarto for creating documents.
How it works: Write in markdown and use Quarto to convert it to html, pdf, epub, ...
I produce my books with Quarto (web + ebook + print version). But you can also use it for websites, reports, dashboards, ...
quarto.org
How it works: Write in markdown and use Quarto to convert it to html, pdf, epub, ...
I produce my books with Quarto (web + ebook + print version). But you can also use it for websites, reports, dashboards, ...
quarto.org

Quarto
An open source technical publishing system for creating beautiful articles, websites, blogs, books, slides, and more. Supports Python, R, Julia, and JavaScript.
quarto.org
November 24, 2024 at 10:24 AM
I feel like not enough people know about Quarto for creating documents.
How it works: Write in markdown and use Quarto to convert it to html, pdf, epub, ...
I produce my books with Quarto (web + ebook + print version). But you can also use it for websites, reports, dashboards, ...
quarto.org
How it works: Write in markdown and use Quarto to convert it to html, pdf, epub, ...
I produce my books with Quarto (web + ebook + print version). But you can also use it for websites, reports, dashboards, ...
quarto.org
Reposted by Paul Bürkner
Optimist: The cup is half full
Pessimist: The cup is half empty
Frequentist: *takes a deep breath* The probability that the cup is half full given the observed volume of water (or more extreme volumes) is larger than 5% so I cannot reject the null hypothesis that the cup is half full.
Pessimist: The cup is half empty
Frequentist: *takes a deep breath* The probability that the cup is half full given the observed volume of water (or more extreme volumes) is larger than 5% so I cannot reject the null hypothesis that the cup is half full.

Optimist: The cup is half full
Pessimist: The cup is half empty
Bayesian:
Pessimist: The cup is half empty
Bayesian:
November 24, 2024 at 8:55 AM
Optimist: The cup is half full
Pessimist: The cup is half empty
Frequentist: *takes a deep breath* The probability that the cup is half full given the observed volume of water (or more extreme volumes) is larger than 5% so I cannot reject the null hypothesis that the cup is half full.
Pessimist: The cup is half empty
Frequentist: *takes a deep breath* The probability that the cup is half full given the observed volume of water (or more extreme volumes) is larger than 5% so I cannot reject the null hypothesis that the cup is half full.
Reposted by Paul Bürkner

Optimist: the cup is half full
Pessimist: the cup is half empty
Comparative cognition researcher: I wonder if this animal will drop some stones into this cup
Pessimist: the cup is half empty
Comparative cognition researcher: I wonder if this animal will drop some stones into this cup

Optimist: the cup is half full
Pessimist: the cup is half empty
Developmentalist: even when I demonstrate that the taller cup holds the same amount of water as the wider cup, this kid thinks the tall one has more
Pessimist: the cup is half empty
Developmentalist: even when I demonstrate that the taller cup holds the same amount of water as the wider cup, this kid thinks the tall one has more

Optimist: the cup is half full
Pessimist: the cup is half empty
Linguist: quantities are described with regard to a reference state; thus we can efficiently convey whether the cup was more recently full or empty
Pessimist: the cup is half empty
Linguist: quantities are described with regard to a reference state; thus we can efficiently convey whether the cup was more recently full or empty
November 24, 2024 at 7:21 AM
Optimist: the cup is half full
Pessimist: the cup is half empty
Comparative cognition researcher: I wonder if this animal will drop some stones into this cup
Pessimist: the cup is half empty
Comparative cognition researcher: I wonder if this animal will drop some stones into this cup