



Musashi Hinck
@musashihi.bsky.social
Former: AI Research Scientist at Intel Labs, Postdoc at Princeton, DPhil at Oxford
Reposted by Musashi Hinck

There’s plenty of evidence for political bias in LLMs, but very few evals reflect realistic LLM use cases — which is where bias actually matters.
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
Are LLMs biased when they write about political issues?
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇

October 29, 2025 at 4:12 PM
There’s plenty of evidence for political bias in LLMs, but very few evals reflect realistic LLM use cases — which is where bias actually matters.
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
Reposted by Musashi Hinck

New job ad: Assistant Professor of Quantitative Social Science, Dartmouth College apply.interfolio.com/172357
Please share with your networks. I am the search chair and happy to answer questions!
Please share with your networks. I am the search chair and happy to answer questions!

August 21, 2025 at 6:50 PM
New job ad: Assistant Professor of Quantitative Social Science, Dartmouth College apply.interfolio.com/172357
Please share with your networks. I am the search chair and happy to answer questions!
Please share with your networks. I am the search chair and happy to answer questions!
Reposted by Musashi Hinck

Exciting work coming from @pranavgoel.bsky.social looking at the effect of ChatGPT and similar tools on web browsing habits.
When people use these tools do they tend to stay on the platform instead of being referred elsewhere? Could this lead to the end of the open web? #pacss2025 #polnet2025
When people use these tools do they tend to stay on the platform instead of being referred elsewhere? Could this lead to the end of the open web? #pacss2025 #polnet2025




August 13, 2025 at 3:46 PM
Exciting work coming from @pranavgoel.bsky.social looking at the effect of ChatGPT and similar tools on web browsing habits.
When people use these tools do they tend to stay on the platform instead of being referred elsewhere? Could this lead to the end of the open web? #pacss2025 #polnet2025
When people use these tools do they tend to stay on the platform instead of being referred elsewhere? Could this lead to the end of the open web? #pacss2025 #polnet2025
Reposted by Musashi Hinck

📢New POSITION PAPER: Use Sparse Autoencoders to Discover Unknown Concepts, Not to Act on Known Concepts
Despite recent results, SAEs aren't dead! They can still be useful to mech interp, and also much more broadly: across FAccT, computational social science, and ML4H. 🧵
Despite recent results, SAEs aren't dead! They can still be useful to mech interp, and also much more broadly: across FAccT, computational social science, and ML4H. 🧵

August 5, 2025 at 4:33 PM
📢New POSITION PAPER: Use Sparse Autoencoders to Discover Unknown Concepts, Not to Act on Known Concepts
Despite recent results, SAEs aren't dead! They can still be useful to mech interp, and also much more broadly: across FAccT, computational social science, and ML4H. 🧵
Despite recent results, SAEs aren't dead! They can still be useful to mech interp, and also much more broadly: across FAccT, computational social science, and ML4H. 🧵
Reposted by Musashi Hinck

Grateful to win Best Paper at ACL for our work on Fairness through Difference Awareness with my amazing collaborators!! Check out the paper for why we think fairness has both gone too far, and at the same time, not far enough aclanthology.org/2025.acl-lon...
July 30, 2025 at 3:34 PM
Grateful to win Best Paper at ACL for our work on Fairness through Difference Awareness with my amazing collaborators!! Check out the paper for why we think fairness has both gone too far, and at the same time, not far enough aclanthology.org/2025.acl-lon...
Reposted by Musashi Hinck

New working paper: “Survey Estimates of Wartime Mortality,” with Gary King, available at gking.harvard.edu/sibs. We provide the first formal proofs of the statistical properties of existing mortality estimators, along with empirical illustrations, to develop intuitions that guide best practices.

July 30, 2025 at 1:34 AM
New working paper: “Survey Estimates of Wartime Mortality,” with Gary King, available at gking.harvard.edu/sibs. We provide the first formal proofs of the statistical properties of existing mortality estimators, along with empirical illustrations, to develop intuitions that guide best practices.
Love this! Especially the explicit operationalization of what “bias” they are measuring via specifying the relevant counterfactual.
Definitely an approach that more papers talking about effects can incorporate to better clarify what the phenomenon they are studying.
Definitely an approach that more papers talking about effects can incorporate to better clarify what the phenomenon they are studying.

A string may get 17 times less probability if tokenised as two symbols (e.g., ⟨he, llo⟩) than as one (e.g., ⟨hello⟩)—by an LM trained from scratch in each situation! Our new ACL paper proposes an observational method to estimate this causal effect! Longer thread soon!
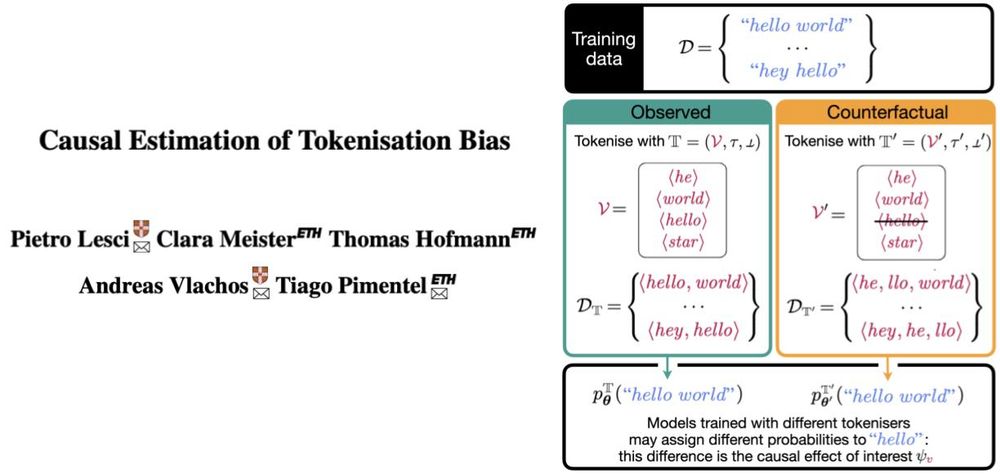
June 4, 2025 at 3:55 PM
Love this! Especially the explicit operationalization of what “bias” they are measuring via specifying the relevant counterfactual.
Definitely an approach that more papers talking about effects can incorporate to better clarify what the phenomenon they are studying.
Definitely an approach that more papers talking about effects can incorporate to better clarify what the phenomenon they are studying.
Reposted by Musashi Hinck

New paper with Rebecca Johnson (@rebeccaj.bsky.social) on parental perceptions of using algorithms to allocate scarce resources in schools, now out in Sociological Science (@sociologicalsci.bsky.social):

May 20, 2025 at 8:34 PM
New paper with Rebecca Johnson (@rebeccaj.bsky.social) on parental perceptions of using algorithms to allocate scarce resources in schools, now out in Sociological Science (@sociologicalsci.bsky.social):
Reposted by Musashi Hinck

Thrilled to share that this is out in @pnas.org today! 🎉
We show that linguistic generalization in language models can be due to underlying analogical mechanisms.
Shoutout to my amazing co-authors @weissweiler.bsky.social, @davidrmortensen.bsky.social, Hinrich Schütze, and Janet Pierrehumbert!
We show that linguistic generalization in language models can be due to underlying analogical mechanisms.
Shoutout to my amazing co-authors @weissweiler.bsky.social, @davidrmortensen.bsky.social, Hinrich Schütze, and Janet Pierrehumbert!
📢 New paper 📢
What generalization mechanisms shape the language skills of LLMs?
Prior work has claimed that LLMs learn language via rules.
We revisit the question and find that superficially rule-like behavior of LLMs can be traced to underlying analogical processes.
🧵
What generalization mechanisms shape the language skills of LLMs?
Prior work has claimed that LLMs learn language via rules.
We revisit the question and find that superficially rule-like behavior of LLMs can be traced to underlying analogical processes.
🧵

May 9, 2025 at 6:29 PM
Thrilled to share that this is out in @pnas.org today! 🎉
We show that linguistic generalization in language models can be due to underlying analogical mechanisms.
Shoutout to my amazing co-authors @weissweiler.bsky.social, @davidrmortensen.bsky.social, Hinrich Schütze, and Janet Pierrehumbert!
We show that linguistic generalization in language models can be due to underlying analogical mechanisms.
Shoutout to my amazing co-authors @weissweiler.bsky.social, @davidrmortensen.bsky.social, Hinrich Schütze, and Janet Pierrehumbert!
Reposted by Musashi Hinck

𝐇𝐨𝐰 𝐜𝐚𝐧 𝐰𝐞 𝐩𝐞𝐫𝐟𝐞𝐜𝐭𝐥𝐲 𝐞𝐫𝐚𝐬𝐞 𝐜𝐨𝐧𝐜𝐞𝐩𝐭𝐬 𝐟𝐫𝐨𝐦 𝐋𝐋𝐌𝐬?
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵
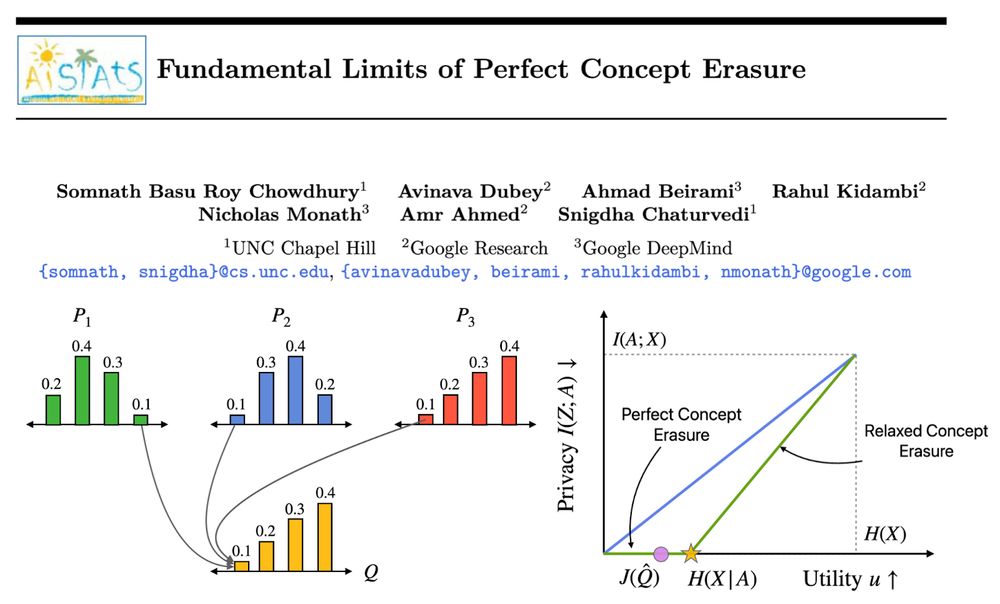
April 2, 2025 at 4:03 PM
𝐇𝐨𝐰 𝐜𝐚𝐧 𝐰𝐞 𝐩𝐞𝐫𝐟𝐞𝐜𝐭𝐥𝐲 𝐞𝐫𝐚𝐬𝐞 𝐜𝐨𝐧𝐜𝐞𝐩𝐭𝐬 𝐟𝐫𝐨𝐦 𝐋𝐋𝐌𝐬?
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵
Reposted by Musashi Hinck

How does the public conceptualize AI? Rather than self-reported measures, we use metaphors to understand the nuance and complexity of people’s mental models. In our #FAccT2025 paper, we analyzed 12,000 metaphors collected over 12 months to track shifts in public perceptions.

May 2, 2025 at 1:19 AM
How does the public conceptualize AI? Rather than self-reported measures, we use metaphors to understand the nuance and complexity of people’s mental models. In our #FAccT2025 paper, we analyzed 12,000 metaphors collected over 12 months to track shifts in public perceptions.
Reposted by Musashi Hinck

💡 Ever wondered how social media and digital technology shapes our democracy?
Join our team @CSMaP_NYU as a Research Engingeer and help us build the tools that power cutting-edge research on the digital public sphere.
🚀 Apply now!
apply.interfolio.com/165833
Join our team @CSMaP_NYU as a Research Engingeer and help us build the tools that power cutting-edge research on the digital public sphere.
🚀 Apply now!
apply.interfolio.com/165833
May 1, 2025 at 3:32 PM
💡 Ever wondered how social media and digital technology shapes our democracy?
Join our team @CSMaP_NYU as a Research Engingeer and help us build the tools that power cutting-edge research on the digital public sphere.
🚀 Apply now!
apply.interfolio.com/165833
Join our team @CSMaP_NYU as a Research Engingeer and help us build the tools that power cutting-edge research on the digital public sphere.
🚀 Apply now!
apply.interfolio.com/165833
Reposted by Musashi Hinck

It is critical for scientific integrity that we trust our measure of progress.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.

April 30, 2025 at 2:55 PM
It is critical for scientific integrity that we trust our measure of progress.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
Reposted by Musashi Hinck

The mods of r/ChangeMyView shared the sub was the subject of a study to test the persuasiveness of LLMs & that they didn't consent. There’s a lot that went wrong, so here’s a 🧵 unpacking it, along with some ideas for how to do research with online communities ethically. tinyurl.com/59tpt988
From the changemyview community on Reddit
Explore this post and more from the changemyview community
tinyurl.com
April 26, 2025 at 10:02 PM
The mods of r/ChangeMyView shared the sub was the subject of a study to test the persuasiveness of LLMs & that they didn't consent. There’s a lot that went wrong, so here’s a 🧵 unpacking it, along with some ideas for how to do research with online communities ethically. tinyurl.com/59tpt988
Reposted by Musashi Hinck

Excited to be presenting "LLMs in Qualitative Research: Uses, Tensions, and Intentions" with @mariannealq.bsky.social at #CHI2025 today!
🆕 paper: dl.acm.org/doi/10.1145/...
🆕 paper: dl.acm.org/doi/10.1145/...

Large Language Models in Qualitative Research: Uses, Tensions, and Intentions | Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems
dl.acm.org
April 27, 2025 at 10:26 PM
Excited to be presenting "LLMs in Qualitative Research: Uses, Tensions, and Intentions" with @mariannealq.bsky.social at #CHI2025 today!
🆕 paper: dl.acm.org/doi/10.1145/...
🆕 paper: dl.acm.org/doi/10.1145/...
Reposted by Musashi Hinck

Lots of progress in mech interp (MI) lately! But how can we measure when new mech interp methods yield real improvements over prior work?
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!

April 23, 2025 at 6:15 PM
Lots of progress in mech interp (MI) lately! But how can we measure when new mech interp methods yield real improvements over prior work?
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!
Reposted by Musashi Hinck

Check out our new paper on benchmarking and mitigating overthinking in reasoning models!
From a simple observational measure of overthinking, we introduce Thought Terminator, a black-box, training-free decoding technique where RMs set their own deadlines and follow them
arxiv.org/abs/2504.13367
From a simple observational measure of overthinking, we introduce Thought Terminator, a black-box, training-free decoding technique where RMs set their own deadlines and follow them
arxiv.org/abs/2504.13367

April 21, 2025 at 11:15 PM
Check out our new paper on benchmarking and mitigating overthinking in reasoning models!
From a simple observational measure of overthinking, we introduce Thought Terminator, a black-box, training-free decoding technique where RMs set their own deadlines and follow them
arxiv.org/abs/2504.13367
From a simple observational measure of overthinking, we introduce Thought Terminator, a black-box, training-free decoding technique where RMs set their own deadlines and follow them
arxiv.org/abs/2504.13367
Reposted by Musashi Hinck

ModernBERT or DeBERTaV3?
What's driving performance: architecture or data?
To find out we pretrained ModernBERT on the same dataset as CamemBERTaV2 (a DeBERTaV3 model) to isolate architecture effects.
Here are our findings:
What's driving performance: architecture or data?
To find out we pretrained ModernBERT on the same dataset as CamemBERTaV2 (a DeBERTaV3 model) to isolate architecture effects.
Here are our findings:
April 14, 2025 at 3:41 PM
ModernBERT or DeBERTaV3?
What's driving performance: architecture or data?
To find out we pretrained ModernBERT on the same dataset as CamemBERTaV2 (a DeBERTaV3 model) to isolate architecture effects.
Here are our findings:
What's driving performance: architecture or data?
To find out we pretrained ModernBERT on the same dataset as CamemBERTaV2 (a DeBERTaV3 model) to isolate architecture effects.
Here are our findings:
Language Fidelity--having an LLM reply in the same language as the user's query--has made its way into the #Llama4 system prompt!
Some interesting work from co-authors and myself on this problem (short thread):
- arxiv.org/abs/2403.03814
- aclanthology.org/2024.finding...
Some interesting work from co-authors and myself on this problem (short thread):
- arxiv.org/abs/2403.03814
- aclanthology.org/2024.finding...

April 21, 2025 at 4:20 PM
Language Fidelity--having an LLM reply in the same language as the user's query--has made its way into the #Llama4 system prompt!
Some interesting work from co-authors and myself on this problem (short thread):
- arxiv.org/abs/2403.03814
- aclanthology.org/2024.finding...
Some interesting work from co-authors and myself on this problem (short thread):
- arxiv.org/abs/2403.03814
- aclanthology.org/2024.finding...
Reposted by Musashi Hinck

Check out the paper at:
📜Paper: arxiv.org/abs/2504.07072
💿Data: hf.co/datasets/Coh...
🌐Website: cohere.com/research/kal...
Huge thanks to everyone involved! This was a big collaboration 👏
📜Paper: arxiv.org/abs/2504.07072
💿Data: hf.co/datasets/Coh...
🌐Website: cohere.com/research/kal...
Huge thanks to everyone involved! This was a big collaboration 👏

Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation
The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmark...
arxiv.org
April 10, 2025 at 10:31 AM
Check out the paper at:
📜Paper: arxiv.org/abs/2504.07072
💿Data: hf.co/datasets/Coh...
🌐Website: cohere.com/research/kal...
Huge thanks to everyone involved! This was a big collaboration 👏
📜Paper: arxiv.org/abs/2504.07072
💿Data: hf.co/datasets/Coh...
🌐Website: cohere.com/research/kal...
Huge thanks to everyone involved! This was a big collaboration 👏
Reposted by Musashi Hinck

[New preprint!] Do Chinese AI Models Speak Chinese Languages? Not really. Chinese LLMs like DeepSeek are better at French than Cantonese. Joint work with
Unso Jo and @dmimno.bsky.social . Link to paper: arxiv.org/pdf/2504.00289
🧵
Unso Jo and @dmimno.bsky.social . Link to paper: arxiv.org/pdf/2504.00289
🧵
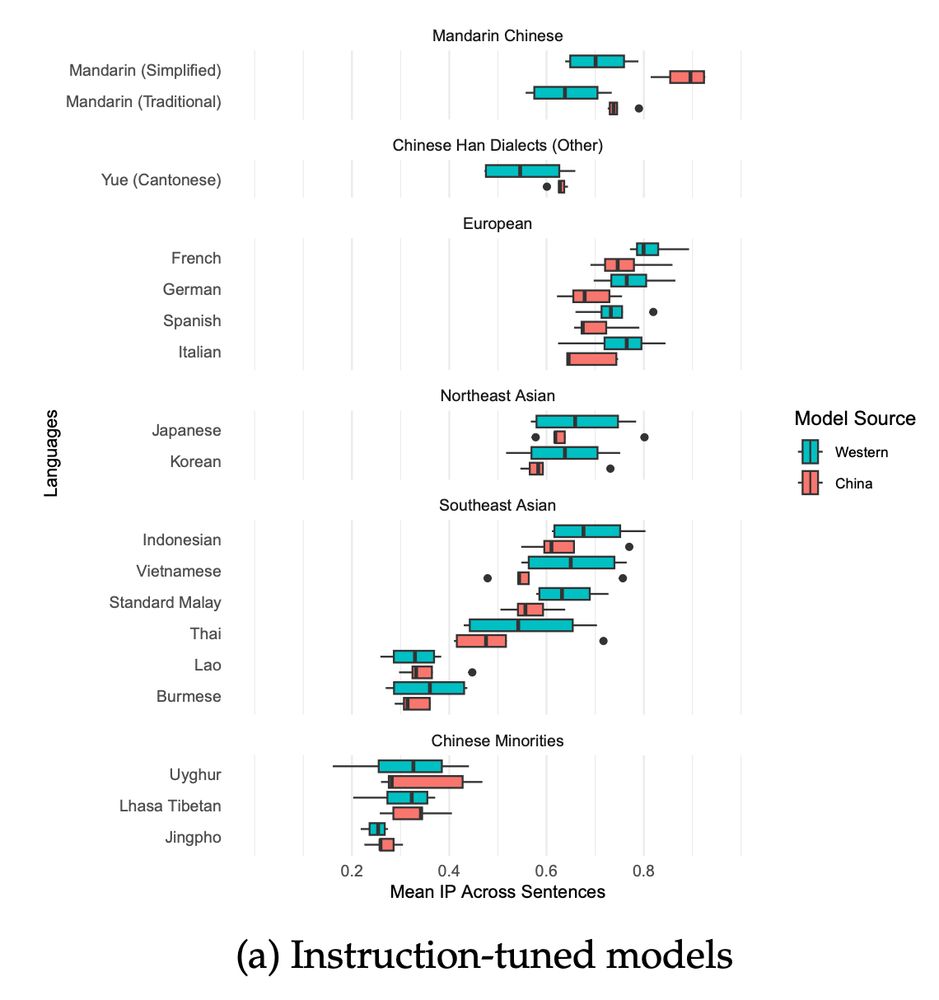
April 9, 2025 at 8:28 PM
[New preprint!] Do Chinese AI Models Speak Chinese Languages? Not really. Chinese LLMs like DeepSeek are better at French than Cantonese. Joint work with
Unso Jo and @dmimno.bsky.social . Link to paper: arxiv.org/pdf/2504.00289
🧵
Unso Jo and @dmimno.bsky.social . Link to paper: arxiv.org/pdf/2504.00289
🧵
Reposted by Musashi Hinck

Is the needle-in-a-haystack test still meaningful given the giant green heatmaps in modern LLM papers?
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇

March 5, 2025 at 5:06 PM
Is the needle-in-a-haystack test still meaningful given the giant green heatmaps in modern LLM papers?
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇
Reposted by Musashi Hinck

Have work on the actionable impact of interpretability findings? Consider submitting to our Actionable Interpretability workshop at ICML! See below for more info.
Website: actionable-interpretability.github.io
Deadline: May 9
Website: actionable-interpretability.github.io
Deadline: May 9

🎉 Our Actionable Interpretability workshop has been accepted to #ICML2025! 🎉
> Follow @actinterp.bsky.social
> Website actionable-interpretability.github.io
@talhaklay.bsky.social @anja.re @mariusmosbach.bsky.social @sarah-nlp.bsky.social @iftenney.bsky.social
Paper submission deadline: May 9th!
> Follow @actinterp.bsky.social
> Website actionable-interpretability.github.io
@talhaklay.bsky.social @anja.re @mariusmosbach.bsky.social @sarah-nlp.bsky.social @iftenney.bsky.social
Paper submission deadline: May 9th!

April 3, 2025 at 5:58 PM
Have work on the actionable impact of interpretability findings? Consider submitting to our Actionable Interpretability workshop at ICML! See below for more info.
Website: actionable-interpretability.github.io
Deadline: May 9
Website: actionable-interpretability.github.io
Deadline: May 9
Reposted by Musashi Hinck

🚨New publication @The_JOP on human biases in data annotation (w. Nora Webb Williams, @kevinaslett.bsky.social, John Wilkerson). Extremely important given the increasing societal reliance on AI tools often trained on human coders www.journals.uchicago.edu/doi/10.1086/...

March 28, 2025 at 1:46 PM
🚨New publication @The_JOP on human biases in data annotation (w. Nora Webb Williams, @kevinaslett.bsky.social, John Wilkerson). Extremely important given the increasing societal reliance on AI tools often trained on human coders www.journals.uchicago.edu/doi/10.1086/...
Reposted by Musashi Hinck

📣 New paper! The field of AI research is increasingly realising that benchmarks are very limited in what they can tell us about AI system performance and safety. We argue and lay out a roadmap toward a *science of AI evaluation*: arxiv.org/abs/2503.05336 🧵
LinkedIn
This link will take you to a page that’s not on LinkedIn
lnkd.in
March 20, 2025 at 1:28 PM
📣 New paper! The field of AI research is increasingly realising that benchmarks are very limited in what they can tell us about AI system performance and safety. We argue and lay out a roadmap toward a *science of AI evaluation*: arxiv.org/abs/2503.05336 🧵