



Mirco Mutti
@mircomutti.bsky.social
Reinforcement learning, but without rewards.
Postdoc at the Technion. PhD from Politecnico di Milano.
https://muttimirco.github.io
Postdoc at the Technion. PhD from Politecnico di Milano.
https://muttimirco.github.io
Reposted by Mirco Mutti

As Transactions on Machine Learning Research (TMLR) grows in number of submissions, we are looking for more reviewers and action editors. Please sign up!
Only one paper to review at a time and <= 6 per year, reviewers report greater satisfaction than reviewing for conferences!
Only one paper to review at a time and <= 6 per year, reviewers report greater satisfaction than reviewing for conferences!

October 14, 2025 at 1:32 PM
As Transactions on Machine Learning Research (TMLR) grows in number of submissions, we are looking for more reviewers and action editors. Please sign up!
Only one paper to review at a time and <= 6 per year, reviewers report greater satisfaction than reviewing for conferences!
Only one paper to review at a time and <= 6 per year, reviewers report greater satisfaction than reviewing for conferences!
Reposted by Mirco Mutti

📣Registration for EWRL is now open📣
Register now 👇 and join us in Tübingen for 3 days (17th-19th September) full of inspiring talks, posters and many social activities to push the boundaries of the RL community!
Register now 👇 and join us in Tübingen for 3 days (17th-19th September) full of inspiring talks, posters and many social activities to push the boundaries of the RL community!
PheedLoop
PheedLoop: Hybrid, In-Person & Virtual Event Software
site.pheedloop.com
August 13, 2025 at 5:02 PM
📣Registration for EWRL is now open📣
Register now 👇 and join us in Tübingen for 3 days (17th-19th September) full of inspiring talks, posters and many social activities to push the boundaries of the RL community!
Register now 👇 and join us in Tübingen for 3 days (17th-19th September) full of inspiring talks, posters and many social activities to push the boundaries of the RL community!
Walking around posters at @icmlconf.bsky.social, I was happy to see some buzz around convex RL—a topic I’ve worked on and strongly believe in.
Thought I’d share a few ICML papers on this direction. Let’s dive in👇
But first… what is convex RL?
🧵
1/n
Thought I’d share a few ICML papers on this direction. Let’s dive in👇
But first… what is convex RL?
🧵
1/n
July 24, 2025 at 1:09 PM
Walking around posters at @icmlconf.bsky.social, I was happy to see some buzz around convex RL—a topic I’ve worked on and strongly believe in.
Thought I’d share a few ICML papers on this direction. Let’s dive in👇
But first… what is convex RL?
🧵
1/n
Thought I’d share a few ICML papers on this direction. Let’s dive in👇
But first… what is convex RL?
🧵
1/n
Would you trust a bandit algorithm to make decisions on your health or investments? Common exploration mechanisms are efficient but scary.
In our latest work at @icmlconf.bsky.social, we reimagine bandit algorithms to get *efficient* and *interpretable* exploration.
A 🧵 below
1/n
In our latest work at @icmlconf.bsky.social, we reimagine bandit algorithms to get *efficient* and *interpretable* exploration.
A 🧵 below
1/n
July 15, 2025 at 3:50 PM
Would you trust a bandit algorithm to make decisions on your health or investments? Common exploration mechanisms are efficient but scary.
In our latest work at @icmlconf.bsky.social, we reimagine bandit algorithms to get *efficient* and *interpretable* exploration.
A 🧵 below
1/n
In our latest work at @icmlconf.bsky.social, we reimagine bandit algorithms to get *efficient* and *interpretable* exploration.
A 🧵 below
1/n
Here we have an original take on how to make the best of parallel data collection for RL. Don't miss the poster at ICML, we're curious to hear what y'all think!
Kudos to the awesome students Vincenzo and @ricczamboni.bsky.social for their work under the wise supervision of Marcello.
Kudos to the awesome students Vincenzo and @ricczamboni.bsky.social for their work under the wise supervision of Marcello.

🌟🌟Good news for the explorers🗺️!
Next week we will present our paper “Enhancing Diversity in Parallel Agents: A Maximum Exploration Story” with V. De Paola, @mircomutti.bsky.social and M. Restelli at @icmlconf.bsky.social!
(1/N)
Next week we will present our paper “Enhancing Diversity in Parallel Agents: A Maximum Exploration Story” with V. De Paola, @mircomutti.bsky.social and M. Restelli at @icmlconf.bsky.social!
(1/N)
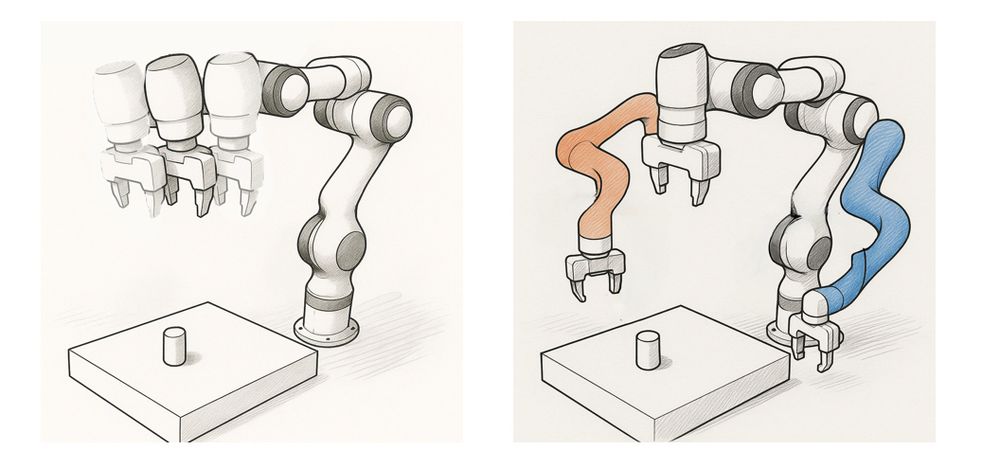
July 9, 2025 at 1:53 PM
Here we have an original take on how to make the best of parallel data collection for RL. Don't miss the poster at ICML, we're curious to hear what y'all think!
Kudos to the awesome students Vincenzo and @ricczamboni.bsky.social for their work under the wise supervision of Marcello.
Kudos to the awesome students Vincenzo and @ricczamboni.bsky.social for their work under the wise supervision of Marcello.
Reposted by Mirco Mutti

What do we talk about when we talk about the Bellman Optimality Equation?
If we think carefully, we are (implicitly) making three claims.
#FoundationsOfReinforcementLearning #sneakpeek
If we think carefully, we are (implicitly) making three claims.
#FoundationsOfReinforcementLearning #sneakpeek

July 8, 2025 at 11:07 PM
What do we talk about when we talk about the Bellman Optimality Equation?
If we think carefully, we are (implicitly) making three claims.
#FoundationsOfReinforcementLearning #sneakpeek
If we think carefully, we are (implicitly) making three claims.
#FoundationsOfReinforcementLearning #sneakpeek
Reposted by Mirco Mutti

System is so broken:
- researchers write papers no one reads
- reviewers don't have time to review, shamed to coauthors, use LLMs instead of reading
- authors try to fool said LLMs with prompt injection
- evaling researchers based on # of papers (no time to read)
Dystopic.
- researchers write papers no one reads
- reviewers don't have time to review, shamed to coauthors, use LLMs instead of reading
- authors try to fool said LLMs with prompt injection
- evaling researchers based on # of papers (no time to read)
Dystopic.
July 7, 2025 at 4:15 PM
System is so broken:
- researchers write papers no one reads
- reviewers don't have time to review, shamed to coauthors, use LLMs instead of reading
- authors try to fool said LLMs with prompt injection
- evaling researchers based on # of papers (no time to read)
Dystopic.
- researchers write papers no one reads
- reviewers don't have time to review, shamed to coauthors, use LLMs instead of reading
- authors try to fool said LLMs with prompt injection
- evaling researchers based on # of papers (no time to read)
Dystopic.
Reposted by Mirco Mutti
Mark your calendars, EWRL is coming to Tübingen! 📅
When? September 17-19, 2025.
More news to come soon, stay tuned!
When? September 17-19, 2025.
More news to come soon, stay tuned!

April 8, 2025 at 8:33 AM
Mark your calendars, EWRL is coming to Tübingen! 📅
When? September 17-19, 2025.
More news to come soon, stay tuned!
When? September 17-19, 2025.
More news to come soon, stay tuned!
Reposted by Mirco Mutti

Just enjoyed @mircomutti.bsky.social's seminar talk about interpretable meta-learning of contextual bandit types.
The recording is available in case you missed it: youtu.be/pNos7AHGMXw
The recording is available in case you missed it: youtu.be/pNos7AHGMXw
April 8, 2025 at 3:26 PM
Just enjoyed @mircomutti.bsky.social's seminar talk about interpretable meta-learning of contextual bandit types.
The recording is available in case you missed it: youtu.be/pNos7AHGMXw
The recording is available in case you missed it: youtu.be/pNos7AHGMXw
Happening today! Join us if you want to hear about our take on interpretable exploration for multi-armed bandits.
If interested but cannot join, here's the arxiv arxiv.org/abs/2504.04505
Joint work with Jeongyeol, Shie, and @aviv-tamar.bsky.social
If interested but cannot join, here's the arxiv arxiv.org/abs/2504.04505
Joint work with Jeongyeol, Shie, and @aviv-tamar.bsky.social
⏰⏰Theory of Interpretable AI Seminar ⏰⏰
In two weeks, April 8, Mirco Mutti will talk about "A Classification View on Meta Learning Bandits"
In two weeks, April 8, Mirco Mutti will talk about "A Classification View on Meta Learning Bandits"

April 8, 2025 at 7:43 AM
Happening today! Join us if you want to hear about our take on interpretable exploration for multi-armed bandits.
If interested but cannot join, here's the arxiv arxiv.org/abs/2504.04505
Joint work with Jeongyeol, Shie, and @aviv-tamar.bsky.social
If interested but cannot join, here's the arxiv arxiv.org/abs/2504.04505
Joint work with Jeongyeol, Shie, and @aviv-tamar.bsky.social
Reposted by Mirco Mutti
⏰⏰Theory of Interpretable AI Seminar ⏰⏰
In two weeks, April 8, Mirco Mutti will talk about "A Classification View on Meta Learning Bandits"
In two weeks, April 8, Mirco Mutti will talk about "A Classification View on Meta Learning Bandits"
March 27, 2025 at 11:05 AM
⏰⏰Theory of Interpretable AI Seminar ⏰⏰
In two weeks, April 8, Mirco Mutti will talk about "A Classification View on Meta Learning Bandits"
In two weeks, April 8, Mirco Mutti will talk about "A Classification View on Meta Learning Bandits"
The right review form is:
- Summary
- Comment
- Evaluation
Curious of alternative arguments, as it looks like conferences are going in a different direction
- Summary
- Comment
- Evaluation
Curious of alternative arguments, as it looks like conferences are going in a different direction
March 17, 2025 at 3:46 PM
The right review form is:
- Summary
- Comment
- Evaluation
Curious of alternative arguments, as it looks like conferences are going in a different direction
- Summary
- Comment
- Evaluation
Curious of alternative arguments, as it looks like conferences are going in a different direction
Awesome! Have a look at this thread to see some nice multi-object manipulation results

Check out our new #ICLR2025 paper: EC-Diffuser leverages a novel Transformer-based diffusion denoiser to learn goal-conditioned multi-object manipulation policy from pixels!👇
Paper: www.arxiv.org/abs/2412.18907
Project page: sites.google.com/view/ec-diff...
Code: github.com/carl-qi/EC-D...
Paper: www.arxiv.org/abs/2412.18907
Project page: sites.google.com/view/ec-diff...
Code: github.com/carl-qi/EC-D...
February 20, 2025 at 8:20 AM
Awesome! Have a look at this thread to see some nice multi-object manipulation results
Reposted by Mirco Mutti

[4/5] “A Theoretical Framework for Partially-Observed Reward States in RLHF” develops and analyzes a model for RLHF where we posit the human feedback to be generated by a stateful labeler. @mircomutti.bsky.social
January 30, 2025 at 12:25 AM
[4/5] “A Theoretical Framework for Partially-Observed Reward States in RLHF” develops and analyzes a model for RLHF where we posit the human feedback to be generated by a stateful labeler. @mircomutti.bsky.social
If interested on our take on addressing inverse RL in large state spaces, go to meet @filippo_lazzati and @alberto_metelli in the poster session 5 #NeurIPS2024 today (paper -> arxiv.org/abs/2406.03812)

December 13, 2024 at 2:33 PM
If interested on our take on addressing inverse RL in large state spaces, go to meet @filippo_lazzati and @alberto_metelli in the poster session 5 #NeurIPS2024 today (paper -> arxiv.org/abs/2406.03812)
Reposted by Mirco Mutti

I will soon be opening a call for a postdoctoral position in online learning and algorithmic game theory, starting in 2025, funded by my ERC at Bocconi University.
If you're interested, feel free to reach out. If you're not personally interested but know someone who might be, please let them know!
If you're interested, feel free to reach out. If you're not personally interested but know someone who might be, please let them know!
November 28, 2024 at 6:14 PM
I will soon be opening a call for a postdoctoral position in online learning and algorithmic game theory, starting in 2025, funded by my ERC at Bocconi University.
If you're interested, feel free to reach out. If you're not personally interested but know someone who might be, please let them know!
If you're interested, feel free to reach out. If you're not personally interested but know someone who might be, please let them know!
Highly recommended!

Want to learn / teach RL?
Check out new book draft:
Reinforcement Learning - Foundations sites.google.com/view/rlfound...
W/ Shie Mannor & Yishay Mansour
This is a rigorous first course in RL, based on our teaching at TAU CS and Technion ECE.
Check out new book draft:
Reinforcement Learning - Foundations sites.google.com/view/rlfound...
W/ Shie Mannor & Yishay Mansour
This is a rigorous first course in RL, based on our teaching at TAU CS and Technion ECE.



November 25, 2024 at 2:36 PM
Highly recommended!
Reposted by Mirco Mutti

This is nice brain candy for the affective computing crowd
These two give (mostly orthogonal) perspectives on modelling evolving "internal states" of the human evaluator while interacting with the system arxiv.org/pdf/2402.03282 arxiv.org/pdf/2405.17713 (shameless advertisement alert)
November 23, 2024 at 2:09 AM
This is nice brain candy for the affective computing crowd
Reposted by Mirco Mutti

If you're an RL researcher or RL adjacent, pipe up to make sure I've added you here!
go.bsky.app/3WPHcHg
go.bsky.app/3WPHcHg
November 9, 2024 at 4:42 PM
If you're an RL researcher or RL adjacent, pipe up to make sure I've added you here!
go.bsky.app/3WPHcHg
go.bsky.app/3WPHcHg
Hello there! I'm new here and interested in AI -especially reinforcement learning- and keeping up with the latest in research. I'll occasionally share updates on my work and would love to hear about yours too.
November 20, 2024 at 4:05 PM
Hello there! I'm new here and interested in AI -especially reinforcement learning- and keeping up with the latest in research. I'll occasionally share updates on my work and would love to hear about yours too.