




Marlos C. Machado
@marloscmachado.bsky.social
Assistant Professor at the University of Alberta. Amii Fellow, Canada CIFAR AI chair. Machine learning researcher. All things reinforcement learning.
📍 Edmonton, Canada 🇨🇦
🔗 https://webdocs.cs.ualberta.ca/~machado/
🗓️ Joined November, 2024
📍 Edmonton, Canada 🇨🇦
🔗 https://webdocs.cs.ualberta.ca/~machado/
🗓️ Joined November, 2024
"Canada Impact+ Research Chairs program—a new $1 billion investment that will provide Canadian institutions the opportunity to recruit top-tier international researchers with expertise in key areas ..."
www.canada.ca/en/innovatio...
www.canada.ca/en/innovatio...
Government of Canada launches new initiative to recruit world-leading researchers - Canada.ca
Canada will invest $1.7 billion to attract top global talent
www.canada.ca
December 10, 2025 at 12:24 AM
"Canada Impact+ Research Chairs program—a new $1 billion investment that will provide Canadian institutions the opportunity to recruit top-tier international researchers with expertise in key areas ..."
www.canada.ca/en/innovatio...
www.canada.ca/en/innovatio...
Reposted by Marlos C. Machado

Thrilled to start 2026 as faculty in Psych & CS
@ualberta.bsky.social + Amii.ca Fellow! 🥳 Recruiting students to develop theories of cognition in natural & artificial systems 🤖💭🧠. Find me at #NeurIPS2025 workshops (speaking coginterp.github.io/neurips2025 & organising @dataonbrainmind.bsky.social)
@ualberta.bsky.social + Amii.ca Fellow! 🥳 Recruiting students to develop theories of cognition in natural & artificial systems 🤖💭🧠. Find me at #NeurIPS2025 workshops (speaking coginterp.github.io/neurips2025 & organising @dataonbrainmind.bsky.social)
December 6, 2025 at 7:26 PM
Thrilled to start 2026 as faculty in Psych & CS
@ualberta.bsky.social + Amii.ca Fellow! 🥳 Recruiting students to develop theories of cognition in natural & artificial systems 🤖💭🧠. Find me at #NeurIPS2025 workshops (speaking coginterp.github.io/neurips2025 & organising @dataonbrainmind.bsky.social)
@ualberta.bsky.social + Amii.ca Fellow! 🥳 Recruiting students to develop theories of cognition in natural & artificial systems 🤖💭🧠. Find me at #NeurIPS2025 workshops (speaking coginterp.github.io/neurips2025 & organising @dataonbrainmind.bsky.social)
The Computing Science Dept. at the University of Alberta has multiple faculty job openings. Please share this broadly. We have a great environment!
- CS Theory: tinyurl.com/zrh9mk69
- Network/Cyber Security: tinyurl.com/renxazzy
- Robotics/CV/Graphics: tinyurl.com/ypcsfbff
- CS Theory: tinyurl.com/zrh9mk69
- Network/Cyber Security: tinyurl.com/renxazzy
- Robotics/CV/Graphics: tinyurl.com/ypcsfbff




November 27, 2025 at 6:00 PM
The Computing Science Dept. at the University of Alberta has multiple faculty job openings. Please share this broadly. We have a great environment!
- CS Theory: tinyurl.com/zrh9mk69
- Network/Cyber Security: tinyurl.com/renxazzy
- Robotics/CV/Graphics: tinyurl.com/ypcsfbff
- CS Theory: tinyurl.com/zrh9mk69
- Network/Cyber Security: tinyurl.com/renxazzy
- Robotics/CV/Graphics: tinyurl.com/ypcsfbff
The Department of Computing Science at the University of Alberta at the University of Alberta has an opening for another tenure-track faculty in robotics. Please, spread the word.
I can attest to how awesome our department and @amiithinks.bsky.social are!
(Official job posting coming soon.)
I can attest to how awesome our department and @amiithinks.bsky.social are!
(Official job posting coming soon.)
November 20, 2025 at 2:54 PM
The Department of Computing Science at the University of Alberta at the University of Alberta has an opening for another tenure-track faculty in robotics. Please, spread the word.
I can attest to how awesome our department and @amiithinks.bsky.social are!
(Official job posting coming soon.)
I can attest to how awesome our department and @amiithinks.bsky.social are!
(Official job posting coming soon.)
Ratatouille (2007)

October 7, 2025 at 9:58 PM
Ratatouille (2007)
This paper has now been accepted @neuripsconf.bsky.social !
Huge congratulations, Hon Tik (Rick) Tse and Siddarth Chandrasekar.
Huge congratulations, Hon Tik (Rick) Tse and Siddarth Chandrasekar.
📢 I'm happy to share the preprint: _Reward-Aware Proto-Representations in Reinforcement Learning_ ‼️
My PhD student, Hon Tik Tse, led this work, and my MSc student, Siddarth Chandrasekar, assisted us.
arxiv.org/abs/2505.16217
Basically, it's the SR with rewards. See below 👇
My PhD student, Hon Tik Tse, led this work, and my MSc student, Siddarth Chandrasekar, assisted us.
arxiv.org/abs/2505.16217
Basically, it's the SR with rewards. See below 👇
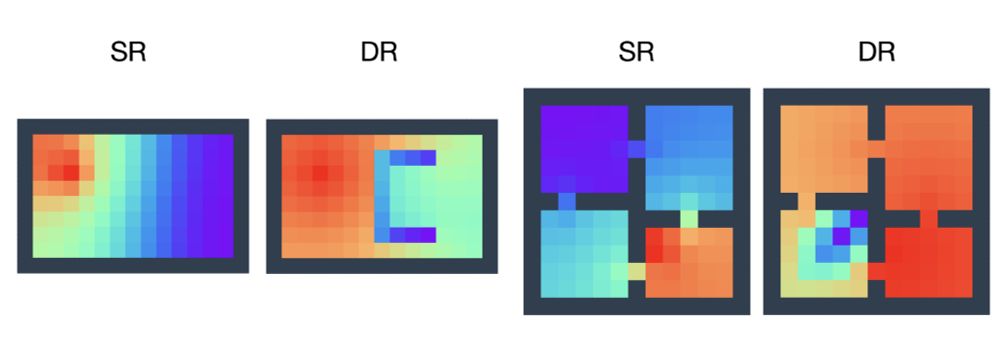
September 18, 2025 at 10:04 PM
This paper has now been accepted @neuripsconf.bsky.social !
Huge congratulations, Hon Tik (Rick) Tse and Siddarth Chandrasekar.
Huge congratulations, Hon Tik (Rick) Tse and Siddarth Chandrasekar.
1/2: But there are none so frightened, or so strange in their fear, as conquerors. They conjure phantoms endlessly, terrified that their victims will someday do back what was done to them—even if, in truth, their victims couldn’t care less about such pettiness and have moved on.”
August 27, 2025 at 2:20 AM
1/2: But there are none so frightened, or so strange in their fear, as conquerors. They conjure phantoms endlessly, terrified that their victims will someday do back what was done to them—even if, in truth, their victims couldn’t care less about such pettiness and have moved on.”
Reposted by Marlos C. Machado

Excited to announce the RLC best paper awards! Like last year, we wanted to highlight the many excellent ways you can do research.
rl-conference.cc/RLC2025Award...
rl-conference.cc/RLC2025Award...
RLC 2025 - Outstanding Paper Awards
rl-conference.cc
August 7, 2025 at 8:30 PM
Excited to announce the RLC best paper awards! Like last year, we wanted to highlight the many excellent ways you can do research.
rl-conference.cc/RLC2025Award...
rl-conference.cc/RLC2025Award...
Here's what our group will be presenting at RLC'25.
* Invited Talks at Workshops:*
Tue 10:00: The Causal RL Workshop sites.google.com/uci.edu/crlw...
Tue 14:30: Inductive Biases in RL (IBRL) Workshop
sites.google.com/view/ibrl-wo...
Tue 15:00: Panel Discussion at IBRL Workshop
* Invited Talks at Workshops:*
Tue 10:00: The Causal RL Workshop sites.google.com/uci.edu/crlw...
Tue 14:30: Inductive Biases in RL (IBRL) Workshop
sites.google.com/view/ibrl-wo...
Tue 15:00: Panel Discussion at IBRL Workshop
August 4, 2025 at 3:49 PM
Here's what our group will be presenting at RLC'25.
* Invited Talks at Workshops:*
Tue 10:00: The Causal RL Workshop sites.google.com/uci.edu/crlw...
Tue 14:30: Inductive Biases in RL (IBRL) Workshop
sites.google.com/view/ibrl-wo...
Tue 15:00: Panel Discussion at IBRL Workshop
* Invited Talks at Workshops:*
Tue 10:00: The Causal RL Workshop sites.google.com/uci.edu/crlw...
Tue 14:30: Inductive Biases in RL (IBRL) Workshop
sites.google.com/view/ibrl-wo...
Tue 15:00: Panel Discussion at IBRL Workshop
RLC starts tomorrow here in Edmonton. I couldn't be more excited! It has a fantastic roll of speakers, great papers, and workshops. And this time, it is in Edmonton 😁
@rl-conference.bsky.social is my favourite conference, and no, it is not because I am one of its organizers this year.
@rl-conference.bsky.social is my favourite conference, and no, it is not because I am one of its organizers this year.

August 4, 2025 at 3:27 PM
RLC starts tomorrow here in Edmonton. I couldn't be more excited! It has a fantastic roll of speakers, great papers, and workshops. And this time, it is in Edmonton 😁
@rl-conference.bsky.social is my favourite conference, and no, it is not because I am one of its organizers this year.
@rl-conference.bsky.social is my favourite conference, and no, it is not because I am one of its organizers this year.
This was a great long-term effort from @martinklissarov.bsky.social, Akhil Bagaria, and @ray-luo.bsky.social, and it led to a great overview of the ideas behind leveraging temporal abstractions in AI.
If anything, I think this is very useful resource for anyone interested in this field!
If anything, I think this is very useful resource for anyone interested in this field!

As AI agents face increasingly long and complex tasks, decomposing them into subtasks becomes increasingly appealing.
But how do we discover such temporal structure?
Hierarchical RL provides a natural formalism-yet many questions remain open.
Here's our overview of the field🧵
But how do we discover such temporal structure?
Hierarchical RL provides a natural formalism-yet many questions remain open.
Here's our overview of the field🧵
June 27, 2025 at 8:57 PM
This was a great long-term effort from @martinklissarov.bsky.social, Akhil Bagaria, and @ray-luo.bsky.social, and it led to a great overview of the ideas behind leveraging temporal abstractions in AI.
If anything, I think this is very useful resource for anyone interested in this field!
If anything, I think this is very useful resource for anyone interested in this field!
Reposted by Marlos C. Machado
To align better with workshop acceptance dates, 𝐑𝐋𝐂 𝐢𝐬 𝐞𝐱𝐭𝐞𝐧𝐝𝐢𝐧𝐠 𝐢𝐭𝐬 𝐞𝐚𝐫𝐥𝐲 𝐫𝐞𝐠𝐢𝐬𝐭𝐫𝐚𝐭𝐢𝐨𝐧 𝐝𝐞𝐚𝐝𝐥𝐢𝐧𝐞 𝐭𝐨 𝐉𝐮𝐧𝐞 𝟐𝟑𝐫𝐝!
May 30, 2025 at 3:02 PM
To align better with workshop acceptance dates, 𝐑𝐋𝐂 𝐢𝐬 𝐞𝐱𝐭𝐞𝐧𝐝𝐢𝐧𝐠 𝐢𝐭𝐬 𝐞𝐚𝐫𝐥𝐲 𝐫𝐞𝐠𝐢𝐬𝐭𝐫𝐚𝐭𝐢𝐨𝐧 𝐝𝐞𝐚𝐝𝐥𝐢𝐧𝐞 𝐭𝐨 𝐉𝐮𝐧𝐞 𝟐𝟑𝐫𝐝!
📢 I'm very excited to release AgarCL, a new evaluation platform for research in continual reinforcement learning‼️
Repo: github.com/machado-rese...
Website: agarcl.github.io
Preprint: arxiv.org/abs/2505.18347
Details below 👇
Repo: github.com/machado-rese...
Website: agarcl.github.io
Preprint: arxiv.org/abs/2505.18347
Details below 👇

May 27, 2025 at 3:48 AM
📢 I'm very excited to release AgarCL, a new evaluation platform for research in continual reinforcement learning‼️
Repo: github.com/machado-rese...
Website: agarcl.github.io
Preprint: arxiv.org/abs/2505.18347
Details below 👇
Repo: github.com/machado-rese...
Website: agarcl.github.io
Preprint: arxiv.org/abs/2505.18347
Details below 👇
📢 I'm happy to share the preprint: _Reward-Aware Proto-Representations in Reinforcement Learning_ ‼️
My PhD student, Hon Tik Tse, led this work, and my MSc student, Siddarth Chandrasekar, assisted us.
arxiv.org/abs/2505.16217
Basically, it's the SR with rewards. See below 👇
My PhD student, Hon Tik Tse, led this work, and my MSc student, Siddarth Chandrasekar, assisted us.
arxiv.org/abs/2505.16217
Basically, it's the SR with rewards. See below 👇
May 24, 2025 at 3:23 PM
📢 I'm happy to share the preprint: _Reward-Aware Proto-Representations in Reinforcement Learning_ ‼️
My PhD student, Hon Tik Tse, led this work, and my MSc student, Siddarth Chandrasekar, assisted us.
arxiv.org/abs/2505.16217
Basically, it's the SR with rewards. See below 👇
My PhD student, Hon Tik Tse, led this work, and my MSc student, Siddarth Chandrasekar, assisted us.
arxiv.org/abs/2505.16217
Basically, it's the SR with rewards. See below 👇
The list of accepted workshops at RLC is now available!
I thoroughly enjoyed the RLC workshops last year, and this year, they seem to be as good as expected! That's very different from what I have been seeing in other conferences, just saying ...
rl-conference.cc/accepted_wor...
I thoroughly enjoyed the RLC workshops last year, and this year, they seem to be as good as expected! That's very different from what I have been seeing in other conferences, just saying ...
rl-conference.cc/accepted_wor...
April 14, 2025 at 9:12 PM
The list of accepted workshops at RLC is now available!
I thoroughly enjoyed the RLC workshops last year, and this year, they seem to be as good as expected! That's very different from what I have been seeing in other conferences, just saying ...
rl-conference.cc/accepted_wor...
I thoroughly enjoyed the RLC workshops last year, and this year, they seem to be as good as expected! That's very different from what I have been seeing in other conferences, just saying ...
rl-conference.cc/accepted_wor...
Last year, RLC reminded me why I used to like going to conferences. I hadn't had that much fun in a long time. We are working hard to do the same thing this year.
Like last year, we have a fantastic speaker lineup, including a Turing Award Winner 😉
rl-conference.cc
Like last year, we have a fantastic speaker lineup, including a Turing Award Winner 😉
rl-conference.cc
March 31, 2025 at 3:18 PM
Last year, RLC reminded me why I used to like going to conferences. I hadn't had that much fun in a long time. We are working hard to do the same thing this year.
Like last year, we have a fantastic speaker lineup, including a Turing Award Winner 😉
rl-conference.cc
Like last year, we have a fantastic speaker lineup, including a Turing Award Winner 😉
rl-conference.cc
Reposted by Marlos C. Machado
Reminder: The appendix comes before the references, is peer-reviewed, and counts towards the page limit. It can help your paper flow better while still being part of the paper. Anything you don’t want to count towards the page limit should go in the supplementary material!
February 28, 2025 at 6:21 PM
Reminder: The appendix comes before the references, is peer-reviewed, and counts towards the page limit. It can help your paper flow better while still being part of the paper. Anything you don’t want to count towards the page limit should go in the supplementary material!
I'm heading to AAAI'25 and I'll be giving two talks there ✈️ ‼️
1. Sunday 11:15 for the New Faculty Highlights program
aaai.org/conference/a...
2. Tuesday 09:00 for the Bridging the Gap Between AI Planning and RL Workshop
prl-theworkshop.github.io/prl2025-aaai/
Let me know if you want to meet!
1. Sunday 11:15 for the New Faculty Highlights program
aaai.org/conference/a...
2. Tuesday 09:00 for the Bridging the Gap Between AI Planning and RL Workshop
prl-theworkshop.github.io/prl2025-aaai/
Let me know if you want to meet!

AAAI-25 New Faculty Highlights Program - AAAI
New Faculty Highlights Room 121B This year, AAAI is continuing its invited speaker program, highlighting AI researchers who have just begun careers as new faculty members or the equivalent in industry...
aaai.org
February 28, 2025 at 5:54 PM
I'm heading to AAAI'25 and I'll be giving two talks there ✈️ ‼️
1. Sunday 11:15 for the New Faculty Highlights program
aaai.org/conference/a...
2. Tuesday 09:00 for the Bridging the Gap Between AI Planning and RL Workshop
prl-theworkshop.github.io/prl2025-aaai/
Let me know if you want to meet!
1. Sunday 11:15 for the New Faculty Highlights program
aaai.org/conference/a...
2. Tuesday 09:00 for the Bridging the Gap Between AI Planning and RL Workshop
prl-theworkshop.github.io/prl2025-aaai/
Let me know if you want to meet!
Reposted by Marlos C. Machado

Some extra motivation for those of you in RLC deadline mode: our line-up of keynote speakers -- as all accepted papers get a talk, they may attend yours!
@rl-conference.bsky.social
@rl-conference.bsky.social

February 24, 2025 at 11:16 AM
Some extra motivation for those of you in RLC deadline mode: our line-up of keynote speakers -- as all accepted papers get a talk, they may attend yours!
@rl-conference.bsky.social
@rl-conference.bsky.social
This 👇
And within reason, abstracts, author order/list and titles can be changed after the abstract deadline.
And within reason, abstracts, author order/list and titles can be changed after the abstract deadline.
RLC abstract submission deadline is AOE today! And remember, it's just the abstracts, not the cover pages or anything else.
February 22, 2025 at 2:10 AM
This 👇
And within reason, abstracts, author order/list and titles can be changed after the abstract deadline.
And within reason, abstracts, author order/list and titles can be changed after the abstract deadline.
I'm teaching a deep RL course where I'm going over the key ideas behind deep RL (double learning, multi-step, prioritization, etc) and specific methods (DQN, PPO, SAC). A lot of this happened before 2018. What are the key deep RL papers of general interest published recently?
February 9, 2025 at 4:22 AM
I'm teaching a deep RL course where I'm going over the key ideas behind deep RL (double learning, multi-step, prioritization, etc) and specific methods (DQN, PPO, SAC). A lot of this happened before 2018. What are the key deep RL papers of general interest published recently?
Reposted by Marlos C. Machado
🚨🚨 RLC deadline has been extended by a week! Abstract deadline is Feb. 21 with a paper deadline of Feb. 28 🚨🚨. Please spread the word!
February 8, 2025 at 6:05 PM
🚨🚨 RLC deadline has been extended by a week! Abstract deadline is Feb. 21 with a paper deadline of Feb. 28 🚨🚨. Please spread the word!
Martin led this great work, check it out. For a dinosaur like me, let me say that, in more classical RL terms, this is a demonstration of how we can effectively combine options and LLMs through programmatic policies.
Can AI agents adapt zero-shot, to complex multi-step language instructions in open-ended environments?
We present MaestroMotif, a method for skill design that produces highly capable and steerable hierarchical agents.
Paper: arxiv.org/abs/2412.08542
Code: github.com/mklissa/maestromotif
We present MaestroMotif, a method for skill design that produces highly capable and steerable hierarchical agents.
Paper: arxiv.org/abs/2412.08542
Code: github.com/mklissa/maestromotif

February 7, 2025 at 3:10 AM
Martin led this great work, check it out. For a dinosaur like me, let me say that, in more classical RL terms, this is a demonstration of how we can effectively combine options and LLMs through programmatic policies.
Reposted by Marlos C. Machado
I forgot to post: if you feel you have been invited to the wrong role, we have a form you can fill to request us to look at it again: docs.google.com/forms/d/e/1F...
We need to fill in all the roles, and the higher the role, the fewer people we need, so if you are not upgraded, don't hate us 😅
We need to fill in all the roles, and the higher the role, the fewer people we need, so if you are not upgraded, don't hate us 😅

RLC/RLJ Reviewer Role Change Request
Thank you for your interest in participating in the RLC/RLJ review process! In some cases people have been invited to more junior reviewing roles than would be appropriate. If this has happened to you...
docs.google.com
February 1, 2025 at 10:48 PM
I forgot to post: if you feel you have been invited to the wrong role, we have a form you can fill to request us to look at it again: docs.google.com/forms/d/e/1F...
We need to fill in all the roles, and the higher the role, the fewer people we need, so if you are not upgraded, don't hate us 😅
We need to fill in all the roles, and the higher the role, the fewer people we need, so if you are not upgraded, don't hate us 😅
You may have heard that the first round of invitations for reviewing at RLC has been sent out. That was a semi-automatic process. We certainly missed many fantastic reviewers, and we also issued invitations for the "wrong" role. Please help us improve all these aspects!
RLC 2025 is looking for reviewers and reviewer nominations, for folks looking to innovate on the RL reviewing process. If you know someone qualified, please nominate them (but read the docs below): forms.gle/3yCeBjn4Yhi7...
And please help us spread the word!
And please help us spread the word!
forms.gle
January 31, 2025 at 6:02 PM
You may have heard that the first round of invitations for reviewing at RLC has been sent out. That was a semi-automatic process. We certainly missed many fantastic reviewers, and we also issued invitations for the "wrong" role. Please help us improve all these aspects!