




Tom Schaul
@schaul.bsky.social
RL researcher at DeepMind
https://schaul.site44.com/ 🇱🇺
https://schaul.site44.com/ 🇱🇺
Reposted by Tom Schaul

Hi RL Enthusiasts!
RLC is coming to Montreal, Quebec, in the summer: Aug 16–19, 2026!
Call for Papers is up now:
Abstract: Mar 1 (AOE)
Submission: Mar 5 (AOE)
Excited to see what you’ve been up to - Submit your best work!
rl-conference.cc/callforpaper...
Please share widely!
RLC is coming to Montreal, Quebec, in the summer: Aug 16–19, 2026!
Call for Papers is up now:
Abstract: Mar 1 (AOE)
Submission: Mar 5 (AOE)
Excited to see what you’ve been up to - Submit your best work!
rl-conference.cc/callforpaper...
Please share widely!
RLJ | RLC Call for Papers
rl-conference.cc
December 23, 2025 at 10:16 PM
Hi RL Enthusiasts!
RLC is coming to Montreal, Quebec, in the summer: Aug 16–19, 2026!
Call for Papers is up now:
Abstract: Mar 1 (AOE)
Submission: Mar 5 (AOE)
Excited to see what you’ve been up to - Submit your best work!
rl-conference.cc/callforpaper...
Please share widely!
RLC is coming to Montreal, Quebec, in the summer: Aug 16–19, 2026!
Call for Papers is up now:
Abstract: Mar 1 (AOE)
Submission: Mar 5 (AOE)
Excited to see what you’ve been up to - Submit your best work!
rl-conference.cc/callforpaper...
Please share widely!
Could we meta-learn which data to train on? Yes!
Does this make LLM training more efficient? Yes!
Would you like to know exactly how? arxiv.org/pdf/2505.17895
(come see us at NeurIPS too!)
Does this make LLM training more efficient? Yes!
Would you like to know exactly how? arxiv.org/pdf/2505.17895
(come see us at NeurIPS too!)
November 6, 2025 at 5:24 PM
Could we meta-learn which data to train on? Yes!
Does this make LLM training more efficient? Yes!
Would you like to know exactly how? arxiv.org/pdf/2505.17895
(come see us at NeurIPS too!)
Does this make LLM training more efficient? Yes!
Would you like to know exactly how? arxiv.org/pdf/2505.17895
(come see us at NeurIPS too!)
Where do some of Reinforcement Learning's great thinkers stand today?
Find out! Keynotes of the RL Conference are online:
www.youtube.com/playlist?lis...
Wanting vs liking, Agent factories, Theoretical limit of LLMs, Pluralist value, RL teachers, Knowledge flywheels
(guess who talked about which!)
Find out! Keynotes of the RL Conference are online:
www.youtube.com/playlist?lis...
Wanting vs liking, Agent factories, Theoretical limit of LLMs, Pluralist value, RL teachers, Knowledge flywheels
(guess who talked about which!)

August 27, 2025 at 12:46 PM
Where do some of Reinforcement Learning's great thinkers stand today?
Find out! Keynotes of the RL Conference are online:
www.youtube.com/playlist?lis...
Wanting vs liking, Agent factories, Theoretical limit of LLMs, Pluralist value, RL teachers, Knowledge flywheels
(guess who talked about which!)
Find out! Keynotes of the RL Conference are online:
www.youtube.com/playlist?lis...
Wanting vs liking, Agent factories, Theoretical limit of LLMs, Pluralist value, RL teachers, Knowledge flywheels
(guess who talked about which!)
Reposted by Tom Schaul

On my way to #ICML2025 to present our algorithm that strongly scales with inference compute, in both performance and sample diversity! 🚀
Reach out if you’d like to chat more!
Reach out if you’d like to chat more!

July 13, 2025 at 12:26 PM
On my way to #ICML2025 to present our algorithm that strongly scales with inference compute, in both performance and sample diversity! 🚀
Reach out if you’d like to chat more!
Reach out if you’d like to chat more!
Deadline to apply is this Wednesday!
Ever thought of joining DeepMind's RL team? We're recruiting for a research engineering role in London:
job-boards.greenhouse.io/deepmind/job...
Please spread the word!
job-boards.greenhouse.io/deepmind/job...
Please spread the word!
Research Engineer, Reinforcement Learning
London, UK
job-boards.greenhouse.io
June 2, 2025 at 9:40 AM
Deadline to apply is this Wednesday!
Ever thought of joining DeepMind's RL team? We're recruiting for a research engineering role in London:
job-boards.greenhouse.io/deepmind/job...
Please spread the word!
job-boards.greenhouse.io/deepmind/job...
Please spread the word!
Research Engineer, Reinforcement Learning
London, UK
job-boards.greenhouse.io
May 22, 2025 at 3:11 PM
Ever thought of joining DeepMind's RL team? We're recruiting for a research engineering role in London:
job-boards.greenhouse.io/deepmind/job...
Please spread the word!
job-boards.greenhouse.io/deepmind/job...
Please spread the word!
When faced with a challenge (like debugging) it helps to think back to examples of how you've overcome challenges in the past. Same for LLMs!
The method we introduce in this paper is efficient because examples are chosen for their complementarity, leading to much steeper inference-time scaling! 🧪
The method we introduce in this paper is efficient because examples are chosen for their complementarity, leading to much steeper inference-time scaling! 🧪
Excited to share our recent work, AuPair, an inference-time technique that builds on the premise of in-context learning to improve LLM coding performance!
arxiv.org/abs/2502.18487
🧵
arxiv.org/abs/2502.18487
🧵

AuPair: Golden Example Pairs for Code Repair
Scaling up inference-time compute has proven to be a valuable strategy in improving the performance of Large Language Models (LLMs) without fine-tuning. An important task that can benefit from additio...
arxiv.org
March 20, 2025 at 10:23 AM
When faced with a challenge (like debugging) it helps to think back to examples of how you've overcome challenges in the past. Same for LLMs!
The method we introduce in this paper is efficient because examples are chosen for their complementarity, leading to much steeper inference-time scaling! 🧪
The method we introduce in this paper is efficient because examples are chosen for their complementarity, leading to much steeper inference-time scaling! 🧪
Some extra motivation for those of you in RLC deadline mode: our line-up of keynote speakers -- as all accepted papers get a talk, they may attend yours!
@rl-conference.bsky.social
@rl-conference.bsky.social

February 24, 2025 at 11:16 AM
Some extra motivation for those of you in RLC deadline mode: our line-up of keynote speakers -- as all accepted papers get a talk, they may attend yours!
@rl-conference.bsky.social
@rl-conference.bsky.social
200 great visualisations: 200 facets and nuances of 1 planetary story.

My annual decarbonization presentation is here.
200 slides, covering everything from water levels in Lake Gatún to sulfur dioxide emissions to ESG fund flows to Chinese auto exports to artificial intelligence. www.nathanielbullard.com/presentations
200 slides, covering everything from water levels in Lake Gatún to sulfur dioxide emissions to ESG fund flows to Chinese auto exports to artificial intelligence. www.nathanielbullard.com/presentations
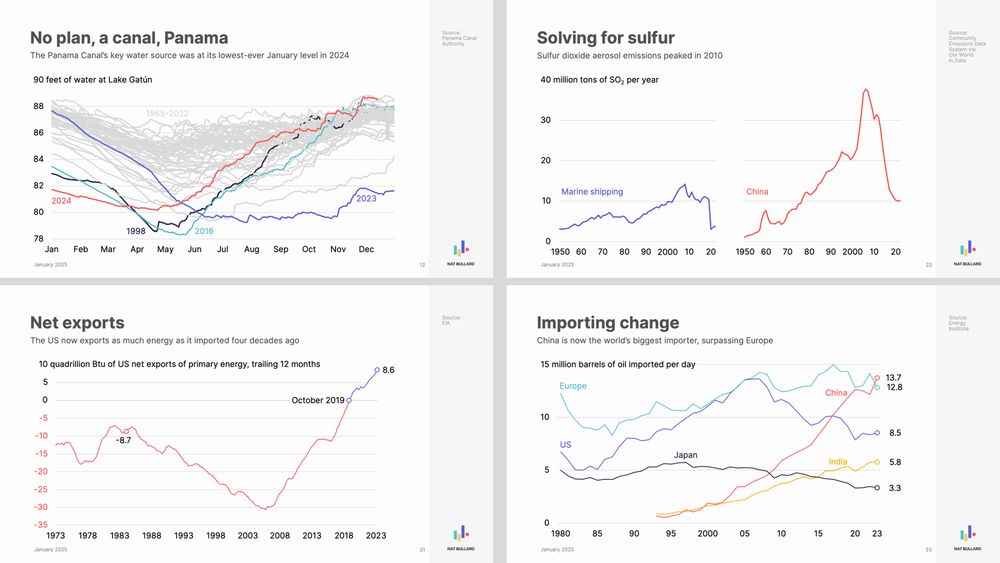
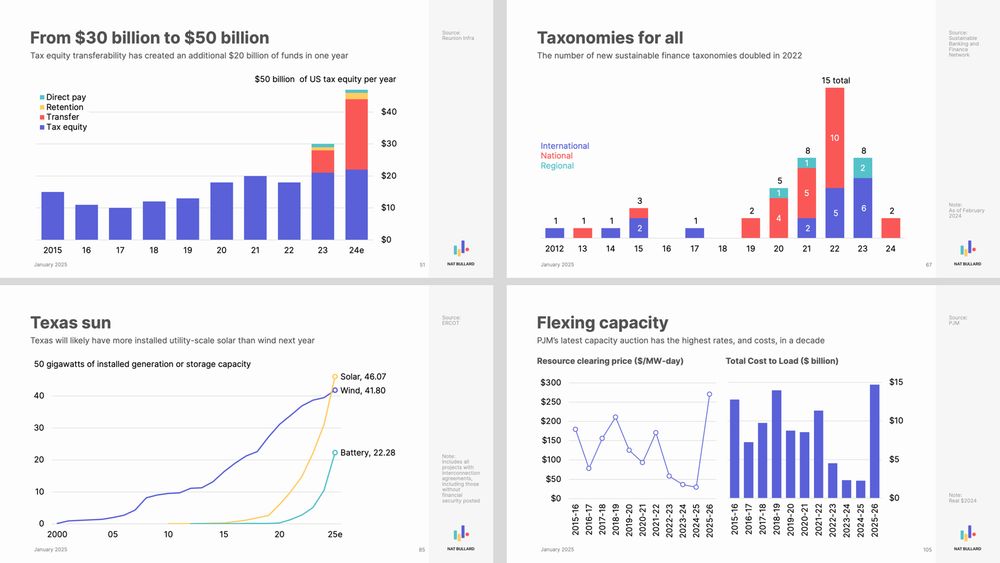
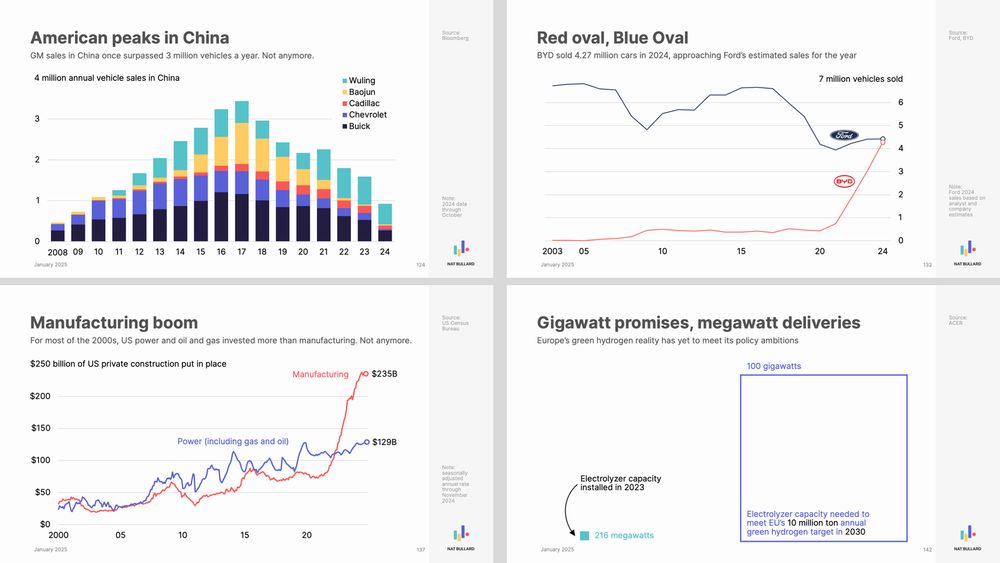
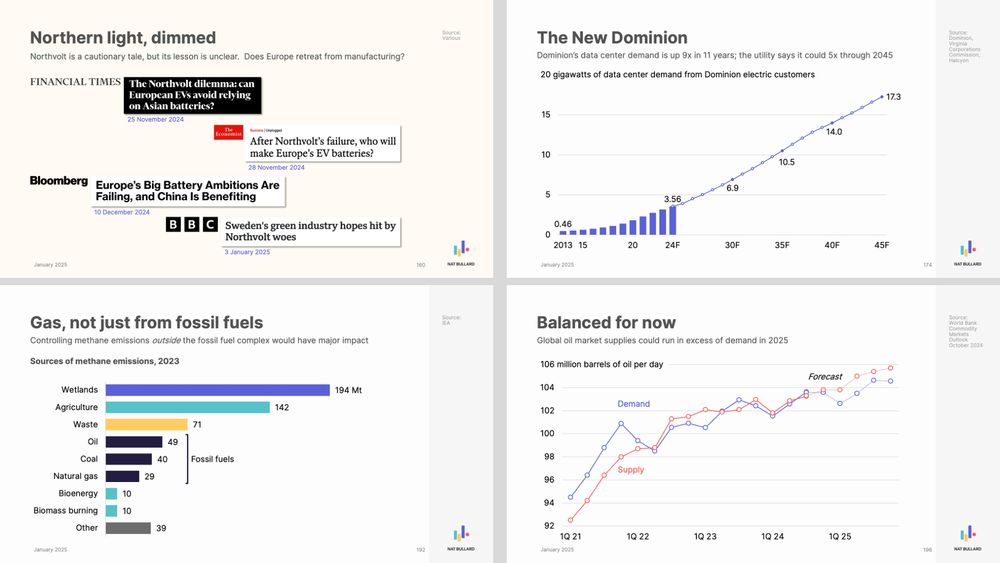
January 31, 2025 at 1:41 PM
200 great visualisations: 200 facets and nuances of 1 planetary story.
Reposted by Tom Schaul

Reposting David Silver's talk about how RL is the way to intelligence. No particular reason
www.youtube.com/watch?v=pkpJ...
www.youtube.com/watch?v=pkpJ...

David Silver - Towards Superhuman Intelligence - RLC 2024
YouTube video by Reinforcement Learning Conference
www.youtube.com
January 27, 2025 at 11:32 PM
Reposting David Silver's talk about how RL is the way to intelligence. No particular reason
www.youtube.com/watch?v=pkpJ...
www.youtube.com/watch?v=pkpJ...
Reposted by Tom Schaul
Excited to announce the first RLC 2025 keynote speaker, a researcher who needs little introduction, whose textbook we've all read, and who keeps pushing the frontier on RL with human-level sample efficiency

January 8, 2025 at 3:03 PM
Excited to announce the first RLC 2025 keynote speaker, a researcher who needs little introduction, whose textbook we've all read, and who keeps pushing the frontier on RL with human-level sample efficiency
Could language games (and playing many of them) be the renewable energy that Ilya was hinting at yesterday? They do address two core challenges of self-improvement -- let's discuss!
My talk is today at 11:40am, West Meeting Room 220-222, #NeurIPS2024
language-gamification.github.io/schedule/
My talk is today at 11:40am, West Meeting Room 220-222, #NeurIPS2024
language-gamification.github.io/schedule/
Are there limits to what you can learn in a closed system? Do we need human feedback in training? Is scale all we need? Should we play language games? What even is "recursive self-improvement"?
Thoughts about this and more here:
arxiv.org/abs/2411.16905
Thoughts about this and more here:
arxiv.org/abs/2411.16905

Boundless Socratic Learning with Language Games
An agent trained within a closed system can master any desired capability, as long as the following three conditions hold: (a) it receives sufficiently informative and aligned feedback, (b) its covera...
arxiv.org
December 14, 2024 at 4:30 PM
Could language games (and playing many of them) be the renewable energy that Ilya was hinting at yesterday? They do address two core challenges of self-improvement -- let's discuss!
My talk is today at 11:40am, West Meeting Room 220-222, #NeurIPS2024
language-gamification.github.io/schedule/
My talk is today at 11:40am, West Meeting Room 220-222, #NeurIPS2024
language-gamification.github.io/schedule/
Don't get to talk enough about RL during #neurips2024? Then join us for more, tomorrow night at The Pearl!
If you're at NeurIPS, RLC is hosting an RL event from 8 till late at The Pearl on Dec. 11th. Join us, meet all the RL researchers, and spread the word!
December 10, 2024 at 10:42 PM
Don't get to talk enough about RL during #neurips2024? Then join us for more, tomorrow night at The Pearl!
This year's (first-ever) RL conference was a breath of fresh air! And now that it's established, the next edition is likely to be even better: Consider sending your best and most original RL work there, and then join us in Edmonton next summer!
The call for papers for RLC is now up! Abstract deadline of 2/14, submission deadline of 2/21!
Please help us spread the word.
rl-conference.cc/callforpaper...
Please help us spread the word.
rl-conference.cc/callforpaper...
RLJ | RLC Call for Papers
rl-conference.cc
December 2, 2024 at 7:37 PM
This year's (first-ever) RL conference was a breath of fresh air! And now that it's established, the next edition is likely to be even better: Consider sending your best and most original RL work there, and then join us in Edmonton next summer!
Are there limits to what you can learn in a closed system? Do we need human feedback in training? Is scale all we need? Should we play language games? What even is "recursive self-improvement"?
Thoughts about this and more here:
arxiv.org/abs/2411.16905
Thoughts about this and more here:
arxiv.org/abs/2411.16905
Boundless Socratic Learning with Language Games
An agent trained within a closed system can master any desired capability, as long as the following three conditions hold: (a) it receives sufficiently informative and aligned feedback, (b) its covera...
arxiv.org
November 28, 2024 at 4:01 PM
Are there limits to what you can learn in a closed system? Do we need human feedback in training? Is scale all we need? Should we play language games? What even is "recursive self-improvement"?
Thoughts about this and more here:
arxiv.org/abs/2411.16905
Thoughts about this and more here:
arxiv.org/abs/2411.16905
Reposted by Tom Schaul

RLC will be held at the Univ. of Alberta, Edmonton, in 2025. I'm happy to say that we now have the conference's website out: rl-conference.cc/index.html
Looking forward to seeing you all there!
@rl-conference.bsky.social
#reinforcementlearning
Looking forward to seeing you all there!
@rl-conference.bsky.social
#reinforcementlearning
November 22, 2024 at 10:46 PM
RLC will be held at the Univ. of Alberta, Edmonton, in 2025. I'm happy to say that we now have the conference's website out: rl-conference.cc/index.html
Looking forward to seeing you all there!
@rl-conference.bsky.social
#reinforcementlearning
Looking forward to seeing you all there!
@rl-conference.bsky.social
#reinforcementlearning
Twitter-optional NeurIPS? Sounds like an appealing prospect!

🚨 Petition to get NeurIPS to join Bluesky 🚨
I just wrote the NeurIPS board requesting them to consider joining Bluesky.
It took about 2 minutes. I invite you to do the same. neurips.cc/Help/Contact
If they changed the name of the conference for the greater good, there's a chance!
Please repost!
I just wrote the NeurIPS board requesting them to consider joining Bluesky.
It took about 2 minutes. I invite you to do the same. neurips.cc/Help/Contact
If they changed the name of the conference for the greater good, there's a chance!
Please repost!
Contact
neurips.cc
November 15, 2024 at 11:19 PM
Twitter-optional NeurIPS? Sounds like an appealing prospect!