




Marlos C. Machado
@marloscmachado.bsky.social
Assistant Professor at the University of Alberta. Amii Fellow, Canada CIFAR AI chair. Machine learning researcher. All things reinforcement learning.
📍 Edmonton, Canada 🇨🇦
🔗 https://webdocs.cs.ualberta.ca/~machado/
🗓️ Joined November, 2024
📍 Edmonton, Canada 🇨🇦
🔗 https://webdocs.cs.ualberta.ca/~machado/
🗓️ Joined November, 2024
The Computing Science Dept. at the University of Alberta has multiple faculty job openings. Please share this broadly. We have a great environment!
- CS Theory: tinyurl.com/zrh9mk69
- Network/Cyber Security: tinyurl.com/renxazzy
- Robotics/CV/Graphics: tinyurl.com/ypcsfbff
- CS Theory: tinyurl.com/zrh9mk69
- Network/Cyber Security: tinyurl.com/renxazzy
- Robotics/CV/Graphics: tinyurl.com/ypcsfbff




November 27, 2025 at 6:00 PM
The Computing Science Dept. at the University of Alberta has multiple faculty job openings. Please share this broadly. We have a great environment!
- CS Theory: tinyurl.com/zrh9mk69
- Network/Cyber Security: tinyurl.com/renxazzy
- Robotics/CV/Graphics: tinyurl.com/ypcsfbff
- CS Theory: tinyurl.com/zrh9mk69
- Network/Cyber Security: tinyurl.com/renxazzy
- Robotics/CV/Graphics: tinyurl.com/ypcsfbff
Ratatouille (2007)

October 7, 2025 at 9:58 PM
Ratatouille (2007)
RLC starts tomorrow here in Edmonton. I couldn't be more excited! It has a fantastic roll of speakers, great papers, and workshops. And this time, it is in Edmonton 😁
@rl-conference.bsky.social is my favourite conference, and no, it is not because I am one of its organizers this year.
@rl-conference.bsky.social is my favourite conference, and no, it is not because I am one of its organizers this year.

August 4, 2025 at 3:27 PM
RLC starts tomorrow here in Edmonton. I couldn't be more excited! It has a fantastic roll of speakers, great papers, and workshops. And this time, it is in Edmonton 😁
@rl-conference.bsky.social is my favourite conference, and no, it is not because I am one of its organizers this year.
@rl-conference.bsky.social is my favourite conference, and no, it is not because I am one of its organizers this year.
9/9: I genuinely think AgarCL might unlock new research avenues in CRL, including loss of plasticity, exploration, representation learning, and more. I do hope you consider using it.
Repo: github.com/machado-rese...
Website: agarcl.github.io
Preprint: arxiv.org/abs/2505.18347
Repo: github.com/machado-rese...
Website: agarcl.github.io
Preprint: arxiv.org/abs/2505.18347

May 27, 2025 at 3:48 AM
9/9: I genuinely think AgarCL might unlock new research avenues in CRL, including loss of plasticity, exploration, representation learning, and more. I do hope you consider using it.
Repo: github.com/machado-rese...
Website: agarcl.github.io
Preprint: arxiv.org/abs/2505.18347
Repo: github.com/machado-rese...
Website: agarcl.github.io
Preprint: arxiv.org/abs/2505.18347
8/9: Well, if you are still interested, you should probably consider reading the paper, but it is interesting to see that most of the agents we considered were able to reach human-level performance only in the most benign settings. And we did use a lot of computing here!


May 27, 2025 at 3:48 AM
8/9: Well, if you are still interested, you should probably consider reading the paper, but it is interesting to see that most of the agents we considered were able to reach human-level performance only in the most benign settings. And we did use a lot of computing here!
7/9: Through mini-games, we tried to quantify and isolate some of the challenges AgarCL poses, including partial observability, non-stationarity, exploration, hyperparameter tuning, and the non-episodic nature of the environment (so easy to forget!). Where do our agents "break"?

May 27, 2025 at 3:48 AM
7/9: Through mini-games, we tried to quantify and isolate some of the challenges AgarCL poses, including partial observability, non-stationarity, exploration, hyperparameter tuning, and the non-episodic nature of the environment (so easy to forget!). Where do our agents "break"?
6/9: Importantly, this is a challenge problem that forces us to deal with many problems we often avoid, such as hyperparameter sweeps and exploration in CRL.
It is perhaps no surprise that the classic algorithms we considered couldn't really make much progress in the full game.
It is perhaps no surprise that the classic algorithms we considered couldn't really make much progress in the full game.

May 27, 2025 at 3:48 AM
6/9: Importantly, this is a challenge problem that forces us to deal with many problems we often avoid, such as hyperparameter sweeps and exploration in CRL.
It is perhaps no surprise that the classic algorithms we considered couldn't really make much progress in the full game.
It is perhaps no surprise that the classic algorithms we considered couldn't really make much progress in the full game.
5/9: Over time, even the agent's observation will change, as the camera needs to zoom out to accommodate more agents; not to mention that there are other agents in the environment. I'm very excited about AgarCL because I think it allows us to ask questions we couldn't before.

May 27, 2025 at 3:48 AM
5/9: Over time, even the agent's observation will change, as the camera needs to zoom out to accommodate more agents; not to mention that there are other agents in the environment. I'm very excited about AgarCL because I think it allows us to ask questions we couldn't before.
4/9: AgarCL is an adaptation of agar.io, a game with simple mechanics that lead to complex interactions. It's non-episodic, and a key aspect is that the agent dynamics change as it accumulates mass: It becomes slower, gains new affordances, sheds more mass, etc.

May 27, 2025 at 3:48 AM
4/9: AgarCL is an adaptation of agar.io, a game with simple mechanics that lead to complex interactions. It's non-episodic, and a key aspect is that the agent dynamics change as it accumulates mass: It becomes slower, gains new affordances, sheds more mass, etc.
3/9: AgarCL is our attempt at an environment with the complexity of a "big world" but in a smooth way, where the "laws of physics" don't change. It has complex dynamics, is partially observable, with non-stationarity, pixel-based observations, and a hybrid action space.

May 27, 2025 at 3:48 AM
3/9: AgarCL is our attempt at an environment with the complexity of a "big world" but in a smooth way, where the "laws of physics" don't change. It has complex dynamics, is partially observable, with non-stationarity, pixel-based observations, and a hybrid action space.
2/9: CRL is often motivated by the idea that the world is bigger than the agent, requiring tracking. We usually simulate this with non-stationarity by cycling through classic episodic problems. I've written papers like this, but it feels too artificial.
arxiv.org/abs/2303.07507
arxiv.org/abs/2303.07507

May 27, 2025 at 3:48 AM
2/9: CRL is often motivated by the idea that the world is bigger than the agent, requiring tracking. We usually simulate this with non-stationarity by cycling through classic episodic problems. I've written papers like this, but it feels too artificial.
arxiv.org/abs/2303.07507
arxiv.org/abs/2303.07507
📢 I'm very excited to release AgarCL, a new evaluation platform for research in continual reinforcement learning‼️
Repo: github.com/machado-rese...
Website: agarcl.github.io
Preprint: arxiv.org/abs/2505.18347
Details below 👇
Repo: github.com/machado-rese...
Website: agarcl.github.io
Preprint: arxiv.org/abs/2505.18347
Details below 👇

May 27, 2025 at 3:48 AM
📢 I'm very excited to release AgarCL, a new evaluation platform for research in continual reinforcement learning‼️
Repo: github.com/machado-rese...
Website: agarcl.github.io
Preprint: arxiv.org/abs/2505.18347
Details below 👇
Repo: github.com/machado-rese...
Website: agarcl.github.io
Preprint: arxiv.org/abs/2505.18347
Details below 👇
6/7: We also show that, when compared to the SR, the DR gives rise to qualitatively different behavior in all sorts of tasks, such as reward shaping, exploration, & option discovery. Similar to what we did w/ STOMP, sometimes there's value in being aware of the reward function 😁

May 24, 2025 at 3:23 PM
6/7: We also show that, when compared to the SR, the DR gives rise to qualitatively different behavior in all sorts of tasks, such as reward shaping, exploration, & option discovery. Similar to what we did w/ STOMP, sometimes there's value in being aware of the reward function 😁
5/7: What we do is to lay some of the theoretical foundation underlying the DR, including establishing some general TD learning and dynamic programming updates, connecting the DR to the SR, and extending the DR to the FA setting, similar to how SFs do it for the SR.



May 24, 2025 at 3:23 PM
5/7: What we do is to lay some of the theoretical foundation underlying the DR, including establishing some general TD learning and dynamic programming updates, connecting the DR to the SR, and extending the DR to the FA setting, similar to how SFs do it for the SR.
2/7: The successor representation has become popular in RL for tasks like transfer learning, reward shaping, option discovery, and exploration.
It captures the underlying dynamics of the environment, but it ignores the reward. What if it didn't ignore the reward function?
It captures the underlying dynamics of the environment, but it ignores the reward. What if it didn't ignore the reward function?

May 24, 2025 at 3:23 PM
2/7: The successor representation has become popular in RL for tasks like transfer learning, reward shaping, option discovery, and exploration.
It captures the underlying dynamics of the environment, but it ignores the reward. What if it didn't ignore the reward function?
It captures the underlying dynamics of the environment, but it ignores the reward. What if it didn't ignore the reward function?
📢 I'm happy to share the preprint: _Reward-Aware Proto-Representations in Reinforcement Learning_ ‼️
My PhD student, Hon Tik Tse, led this work, and my MSc student, Siddarth Chandrasekar, assisted us.
arxiv.org/abs/2505.16217
Basically, it's the SR with rewards. See below 👇
My PhD student, Hon Tik Tse, led this work, and my MSc student, Siddarth Chandrasekar, assisted us.
arxiv.org/abs/2505.16217
Basically, it's the SR with rewards. See below 👇
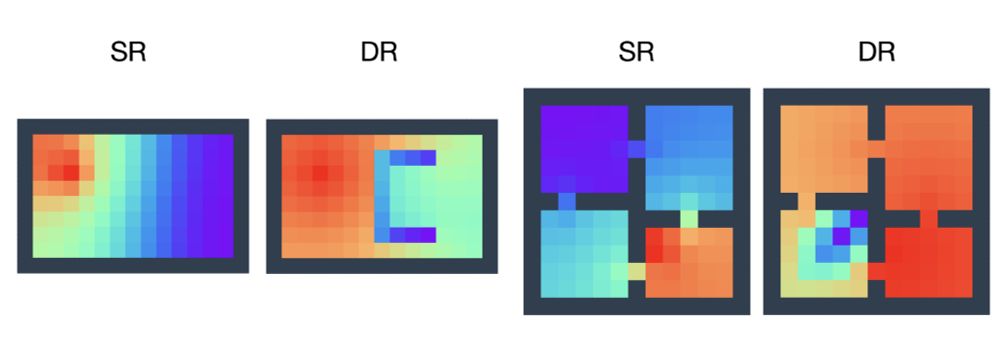
May 24, 2025 at 3:23 PM
📢 I'm happy to share the preprint: _Reward-Aware Proto-Representations in Reinforcement Learning_ ‼️
My PhD student, Hon Tik Tse, led this work, and my MSc student, Siddarth Chandrasekar, assisted us.
arxiv.org/abs/2505.16217
Basically, it's the SR with rewards. See below 👇
My PhD student, Hon Tik Tse, led this work, and my MSc student, Siddarth Chandrasekar, assisted us.
arxiv.org/abs/2505.16217
Basically, it's the SR with rewards. See below 👇
Check out #GoodreadsYearinBooks @goodreads to discover the 30 books I read in 2024! www.goodreads.com/user/year_in...

December 20, 2024 at 1:56 AM
Check out #GoodreadsYearinBooks @goodreads to discover the 30 books I read in 2024! www.goodreads.com/user/year_in...
The Dept. of Computing Science at the University of Alberta is hiring! The new hires in AI will be nominated for a Canada CIFAR AI Chair. We have 3 TT positions:
AI/ML/DL Theory: apps.ualberta.ca/careers/post...
AI + SWE: apps.ualberta.ca/careers/post...
Systems: apps.ualberta.ca/careers/post...
AI/ML/DL Theory: apps.ualberta.ca/careers/post...
AI + SWE: apps.ualberta.ca/careers/post...
Systems: apps.ualberta.ca/careers/post...




November 27, 2024 at 3:07 PM
The Dept. of Computing Science at the University of Alberta is hiring! The new hires in AI will be nominated for a Canada CIFAR AI Chair. We have 3 TT positions:
AI/ML/DL Theory: apps.ualberta.ca/careers/post...
AI + SWE: apps.ualberta.ca/careers/post...
Systems: apps.ualberta.ca/careers/post...
AI/ML/DL Theory: apps.ualberta.ca/careers/post...
AI + SWE: apps.ualberta.ca/careers/post...
Systems: apps.ualberta.ca/careers/post...