




Jane Wu
@janehwu.bsky.social
Postdoc @ UC Berkeley. 3D Vision/Graphics/Robotics. Prev: CS PhD @ Stanford.
janehwu.github.io
janehwu.github.io
Reposted by Jane Wu

One thing about humanoid robots i think is under appreciated, is that you dont have to make some super crazy training set for some specialized arm on wheels. It can learn from humans performing actions, so this is incredibly useful

Humanoid is the worst form to use for so many activities. But yes people want humanoid servants.
August 1, 2025 at 3:12 PM
One thing about humanoid robots i think is under appreciated, is that you dont have to make some super crazy training set for some specialized arm on wheels. It can learn from humans performing actions, so this is incredibly useful
Reposted by Jane Wu

Video recordings from our workshop on Embodied Intelligence and tutorial on Robotics 101 @cvprconference.bsky.social are now up, just in time to catch up with things over the summer.
Enjoy! #CVPR2025
Enjoy! #CVPR2025

📹Our #CVPR2025 workshop and tutorial recordings are now online! Big thanks to our incredible speakers! Watch all the sessions here
🔗 Workshop: youtube.com/playlist?lis...
🔗 Tutorial: youtube.com/playlist?lis...
🔗 Workshop: youtube.com/playlist?lis...
🔗 Tutorial: youtube.com/playlist?lis...
July 16, 2025 at 1:24 PM
Video recordings from our workshop on Embodied Intelligence and tutorial on Robotics 101 @cvprconference.bsky.social are now up, just in time to catch up with things over the summer.
Enjoy! #CVPR2025
Enjoy! #CVPR2025

Reposted by Jane Wu

The Symposium on Geometry Processing is an amazing venue for geometry research: meshes, point clouds, neural fields, 3D ML, etc. Reviews are quick and high-quality.
The deadline is in ~10 days. Consider submitting your work, I'm planning to submit!
sgp2025.my.canva.site/submit-page-...
The deadline is in ~10 days. Consider submitting your work, I'm planning to submit!
sgp2025.my.canva.site/submit-page-...
SGP 2025 - Submit page
sgp2025.my.canva.site
April 1, 2025 at 6:42 PM
The Symposium on Geometry Processing is an amazing venue for geometry research: meshes, point clouds, neural fields, 3D ML, etc. Reviews are quick and high-quality.
The deadline is in ~10 days. Consider submitting your work, I'm planning to submit!
sgp2025.my.canva.site/submit-page-...
The deadline is in ~10 days. Consider submitting your work, I'm planning to submit!
sgp2025.my.canva.site/submit-page-...
Reposted by Jane Wu

📢 We present CWGrasp, a framework for generating 3D Whole-body Grasps with Directional Controllability 🎉
Specifically:
👉 given a grasping object (shown in red color) placed on a receptacle (brown color)
👉 we aim to generate a body (gray color) that grasps the object.
🧵 1/10
Specifically:
👉 given a grasping object (shown in red color) placed on a receptacle (brown color)
👉 we aim to generate a body (gray color) that grasps the object.
🧵 1/10

March 14, 2025 at 6:35 PM
📢 We present CWGrasp, a framework for generating 3D Whole-body Grasps with Directional Controllability 🎉
Specifically:
👉 given a grasping object (shown in red color) placed on a receptacle (brown color)
👉 we aim to generate a body (gray color) that grasps the object.
🧵 1/10
Specifically:
👉 given a grasping object (shown in red color) placed on a receptacle (brown color)
👉 we aim to generate a body (gray color) that grasps the object.
🧵 1/10
Reposted by Jane Wu

📢📢📢 Submit to our workshop on Physics-inspired 3D Vision and Imaging at #CVPR2025!
Speakers 🗣️ include Ioannis Gkioulekas, Laura Waller, Berthy Feng, @shwbaek.bsky.social and Gordon Wetzstein!
🌐 pi3dvi.github.io
You can also just come hangout with us at the workshop @cvprconference.bsky.social!
Speakers 🗣️ include Ioannis Gkioulekas, Laura Waller, Berthy Feng, @shwbaek.bsky.social and Gordon Wetzstein!
🌐 pi3dvi.github.io
You can also just come hangout with us at the workshop @cvprconference.bsky.social!

March 13, 2025 at 6:47 PM
📢📢📢 Submit to our workshop on Physics-inspired 3D Vision and Imaging at #CVPR2025!
Speakers 🗣️ include Ioannis Gkioulekas, Laura Waller, Berthy Feng, @shwbaek.bsky.social and Gordon Wetzstein!
🌐 pi3dvi.github.io
You can also just come hangout with us at the workshop @cvprconference.bsky.social!
Speakers 🗣️ include Ioannis Gkioulekas, Laura Waller, Berthy Feng, @shwbaek.bsky.social and Gordon Wetzstein!
🌐 pi3dvi.github.io
You can also just come hangout with us at the workshop @cvprconference.bsky.social!
Reposted by Jane Wu

I will not lie: having the supp mat DL on the same day as the main paper DL (as ICLR and NeurIPS always did, of course) does not have the best impact on the stress component of the paper submission crunch.
March 7, 2025 at 9:34 PM
I will not lie: having the supp mat DL on the same day as the main paper DL (as ICLR and NeurIPS always did, of course) does not have the best impact on the stress component of the paper submission crunch.
Reposted by Jane Wu

A huge congrats to Flow for winning the Oscar for Best Animated Feature! It was made by a tiny crew entirely using Blender and rendered entirely using Eevee. IMO everyone in the wider animation industry has lessons to learn from Flow.
www.reuters.com/lifestyle/fl...
www.reuters.com/lifestyle/fl...

‘Flow’ wins best animated feature film Oscar
LOS ANGELES, March 2 (Reuters) - The independent film “Flow” won the best animated feature film Oscar on Sunday, securing the first Academy Award for Latvia and its Latvian director Gints Zilbalodis.
www.reuters.com
March 3, 2025 at 4:46 AM
A huge congrats to Flow for winning the Oscar for Best Animated Feature! It was made by a tiny crew entirely using Blender and rendered entirely using Eevee. IMO everyone in the wider animation industry has lessons to learn from Flow.
www.reuters.com/lifestyle/fl...
www.reuters.com/lifestyle/fl...
I'll be presenting "Sparse-View 3D Reconstruction of Clothed Humans via Normal Maps" tomorrow morning at #WACV2025 Oral Session 1.1. Excited to share the final project of my PhD! A brief story 🧵

February 28, 2025 at 8:40 PM
I'll be presenting "Sparse-View 3D Reconstruction of Clothed Humans via Normal Maps" tomorrow morning at #WACV2025 Oral Session 1.1. Excited to share the final project of my PhD! A brief story 🧵
Reposted by Jane Wu

What happens when vision🤝 robotics meet? 🚨 Happy to share our new work on Pretraining Robotic Foundational Models!🔥
ARM4R is an Autoregressive Robotic Model that leverages low-level 4D Representations learned from human video data to yield a better robotic model.
BerkeleyAI 😊
ARM4R is an Autoregressive Robotic Model that leverages low-level 4D Representations learned from human video data to yield a better robotic model.
BerkeleyAI 😊
February 24, 2025 at 3:49 AM
What happens when vision🤝 robotics meet? 🚨 Happy to share our new work on Pretraining Robotic Foundational Models!🔥
ARM4R is an Autoregressive Robotic Model that leverages low-level 4D Representations learned from human video data to yield a better robotic model.
BerkeleyAI 😊
ARM4R is an Autoregressive Robotic Model that leverages low-level 4D Representations learned from human video data to yield a better robotic model.
BerkeleyAI 😊
Reposted by Jane Wu

Full quality video here: www.youtube.com/watch?v=uVcB...
February 21, 2025 at 8:06 PM
Full quality video here: www.youtube.com/watch?v=uVcB...
Reposted by Jane Wu

GPUDrive got accepted to ICLR 2025!
With that, we release GPUDrive v0.4.0! 🚨 You can now install the repo and run your first fast PPO experiment in under 10 minutes.
I’m honestly so excited about the new opportunities and research the sim makes possible. 🚀 1/2
With that, we release GPUDrive v0.4.0! 🚨 You can now install the repo and run your first fast PPO experiment in under 10 minutes.
I’m honestly so excited about the new opportunities and research the sim makes possible. 🚀 1/2
February 20, 2025 at 6:53 PM
GPUDrive got accepted to ICLR 2025!
With that, we release GPUDrive v0.4.0! 🚨 You can now install the repo and run your first fast PPO experiment in under 10 minutes.
I’m honestly so excited about the new opportunities and research the sim makes possible. 🚀 1/2
With that, we release GPUDrive v0.4.0! 🚨 You can now install the repo and run your first fast PPO experiment in under 10 minutes.
I’m honestly so excited about the new opportunities and research the sim makes possible. 🚀 1/2
Reposted by Jane Wu

Just found a new winner for the most hype-baiting, unscientific plot I have seen. (From the recent Figure AI release)

February 20, 2025 at 10:01 PM
Just found a new winner for the most hype-baiting, unscientific plot I have seen. (From the recent Figure AI release)
Reposted by Jane Wu

Really excited to put together this #CVPR2025 workshop on "4D Vision: Modeling the Dynamic World" -- one of the most fascinating areas in computer vision today!
We've invited incredible researchers who are leading fantastic work at various related fields.
4dvisionworkshop.github.io
We've invited incredible researchers who are leading fantastic work at various related fields.
4dvisionworkshop.github.io

February 12, 2025 at 10:34 AM
Really excited to put together this #CVPR2025 workshop on "4D Vision: Modeling the Dynamic World" -- one of the most fascinating areas in computer vision today!
We've invited incredible researchers who are leading fantastic work at various related fields.
4dvisionworkshop.github.io
We've invited incredible researchers who are leading fantastic work at various related fields.
4dvisionworkshop.github.io
Reposted by Jane Wu

Paper submission is now open for the 8th Multimodal Learning and Applications Workshop at #CVPR2025!
Call For Papers: mula-workshop.github.io
#computervision #cvpr #multimodal #ai
Call For Papers: mula-workshop.github.io
#computervision #cvpr #multimodal #ai
MULA 2025
Eighth Multimodal Learning and Applications Workshop
mula-workshop.github.io
February 11, 2025 at 10:06 PM
Paper submission is now open for the 8th Multimodal Learning and Applications Workshop at #CVPR2025!
Call For Papers: mula-workshop.github.io
#computervision #cvpr #multimodal #ai
Call For Papers: mula-workshop.github.io
#computervision #cvpr #multimodal #ai
Reposted by Jane Wu

🏅 Call for Nominations EgoVis 2023/2024 Distinguished Paper Awards
Did you publish a paper contributing to Ego Vision in 2023 or 2024?
Innovative &advancing Ego Vision?
Worthy of a prize?
DL 1 April 2025
Decisions
@cvprconference.bsky.social
#CVPR2025
egovis.github.io/awards/2023_...
Did you publish a paper contributing to Ego Vision in 2023 or 2024?
Innovative &advancing Ego Vision?
Worthy of a prize?
DL 1 April 2025
Decisions
@cvprconference.bsky.social
#CVPR2025
egovis.github.io/awards/2023_...
EgoVis 2023/2024 Distinguished Paper Awards
EgoVis
egovis.github.io
February 11, 2025 at 11:29 AM
🏅 Call for Nominations EgoVis 2023/2024 Distinguished Paper Awards
Did you publish a paper contributing to Ego Vision in 2023 or 2024?
Innovative &advancing Ego Vision?
Worthy of a prize?
DL 1 April 2025
Decisions
@cvprconference.bsky.social
#CVPR2025
egovis.github.io/awards/2023_...
Did you publish a paper contributing to Ego Vision in 2023 or 2024?
Innovative &advancing Ego Vision?
Worthy of a prize?
DL 1 April 2025
Decisions
@cvprconference.bsky.social
#CVPR2025
egovis.github.io/awards/2023_...
Reposted by Jane Wu

(1/n)
📢📢 𝐍𝐞𝐑𝐒𝐞𝐦𝐛𝐥𝐞 𝐯𝟐 𝐃𝐚𝐭𝐚𝐬𝐞𝐭 𝐑𝐞𝐥𝐞𝐚𝐬𝐞 📢📢
Head captures of 7.1MP from 16 cameras at 73fps:
* More recordings (425 people)
* Better color calibration
* Convenient download scripts
github.com/tobias-kirsc...
📢📢 𝐍𝐞𝐑𝐒𝐞𝐦𝐛𝐥𝐞 𝐯𝟐 𝐃𝐚𝐭𝐚𝐬𝐞𝐭 𝐑𝐞𝐥𝐞𝐚𝐬𝐞 📢📢
Head captures of 7.1MP from 16 cameras at 73fps:
* More recordings (425 people)
* Better color calibration
* Convenient download scripts
github.com/tobias-kirsc...
February 11, 2025 at 3:06 PM
(1/n)
📢📢 𝐍𝐞𝐑𝐒𝐞𝐦𝐛𝐥𝐞 𝐯𝟐 𝐃𝐚𝐭𝐚𝐬𝐞𝐭 𝐑𝐞𝐥𝐞𝐚𝐬𝐞 📢📢
Head captures of 7.1MP from 16 cameras at 73fps:
* More recordings (425 people)
* Better color calibration
* Convenient download scripts
github.com/tobias-kirsc...
📢📢 𝐍𝐞𝐑𝐒𝐞𝐦𝐛𝐥𝐞 𝐯𝟐 𝐃𝐚𝐭𝐚𝐬𝐞𝐭 𝐑𝐞𝐥𝐞𝐚𝐬𝐞 📢📢
Head captures of 7.1MP from 16 cameras at 73fps:
* More recordings (425 people)
* Better color calibration
* Convenient download scripts
github.com/tobias-kirsc...
Reposted by Jane Wu

Announcing Diffusion Forcing Transformer (DFoT), our new video diffusion algorithm that generates ultra-long videos of 800+ frames. DFoT enables History Guidance, a simple add-on to any existing video diffusion models for a quality boost. Website: boyuan.space/history-guidance (1/7)
February 11, 2025 at 8:37 PM
Announcing Diffusion Forcing Transformer (DFoT), our new video diffusion algorithm that generates ultra-long videos of 800+ frames. DFoT enables History Guidance, a simple add-on to any existing video diffusion models for a quality boost. Website: boyuan.space/history-guidance (1/7)
Reposted by Jane Wu

We can usually only get partial observations of scenes, but getting complete object information could be helpful for many tasks in robotics and graphics. Our new ICLR 2025 paper extends point-based single object completion models to completing multiple objects in a scene, (1/3)🧵
February 11, 2025 at 6:59 AM
We can usually only get partial observations of scenes, but getting complete object information could be helpful for many tasks in robotics and graphics. Our new ICLR 2025 paper extends point-based single object completion models to completing multiple objects in a scene, (1/3)🧵
Reposted by Jane Wu
🛑📢
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
hd-epic.github.io
arxiv.org/abs/2502.04144
New collected videos
263 annotations/min: recipe, nutrition, actions, sounds, 3D object movement &fixture associations, masks.
26K VQA benchmark to challenge current VLMs
1/N
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
hd-epic.github.io
arxiv.org/abs/2502.04144
New collected videos
263 annotations/min: recipe, nutrition, actions, sounds, 3D object movement &fixture associations, masks.
26K VQA benchmark to challenge current VLMs
1/N
February 7, 2025 at 11:45 AM
🛑📢
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
hd-epic.github.io
arxiv.org/abs/2502.04144
New collected videos
263 annotations/min: recipe, nutrition, actions, sounds, 3D object movement &fixture associations, masks.
26K VQA benchmark to challenge current VLMs
1/N
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
hd-epic.github.io
arxiv.org/abs/2502.04144
New collected videos
263 annotations/min: recipe, nutrition, actions, sounds, 3D object movement &fixture associations, masks.
26K VQA benchmark to challenge current VLMs
1/N
Reposted by Jane Wu

Seeing some of the early results from DexterityGen were definitely a wow moment for me!
It doesn't take a lot to realize all the new opportunities a strong teleop system like this enables! 🚀
X thread: x.com/zhaohengyin/...
Link: zhaohengyin.github.io/dexteritygen/
It doesn't take a lot to realize all the new opportunities a strong teleop system like this enables! 🚀
X thread: x.com/zhaohengyin/...
Link: zhaohengyin.github.io/dexteritygen/
DexGen
zhaohengyin.github.io
February 8, 2025 at 3:02 AM
Seeing some of the early results from DexterityGen were definitely a wow moment for me!
It doesn't take a lot to realize all the new opportunities a strong teleop system like this enables! 🚀
X thread: x.com/zhaohengyin/...
Link: zhaohengyin.github.io/dexteritygen/
It doesn't take a lot to realize all the new opportunities a strong teleop system like this enables! 🚀
X thread: x.com/zhaohengyin/...
Link: zhaohengyin.github.io/dexteritygen/
Reposted by Jane Wu

Our new work has made a big leap moving away from depth based end-to-end to raw rgb pixels based end-to-end. We have two versions: mono and stereo, all trained entirely in simulation (IsaacLab).
February 10, 2025 at 4:59 AM
Our new work has made a big leap moving away from depth based end-to-end to raw rgb pixels based end-to-end. We have two versions: mono and stereo, all trained entirely in simulation (IsaacLab).
Reposted by Jane Wu

🌌🛰️🔭Wanna know which features are universal vs unique in your models and how to find them? Excited to share our preprint: "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment"!
arxiv.org/abs/2502.03714
(1/9)
arxiv.org/abs/2502.03714
(1/9)
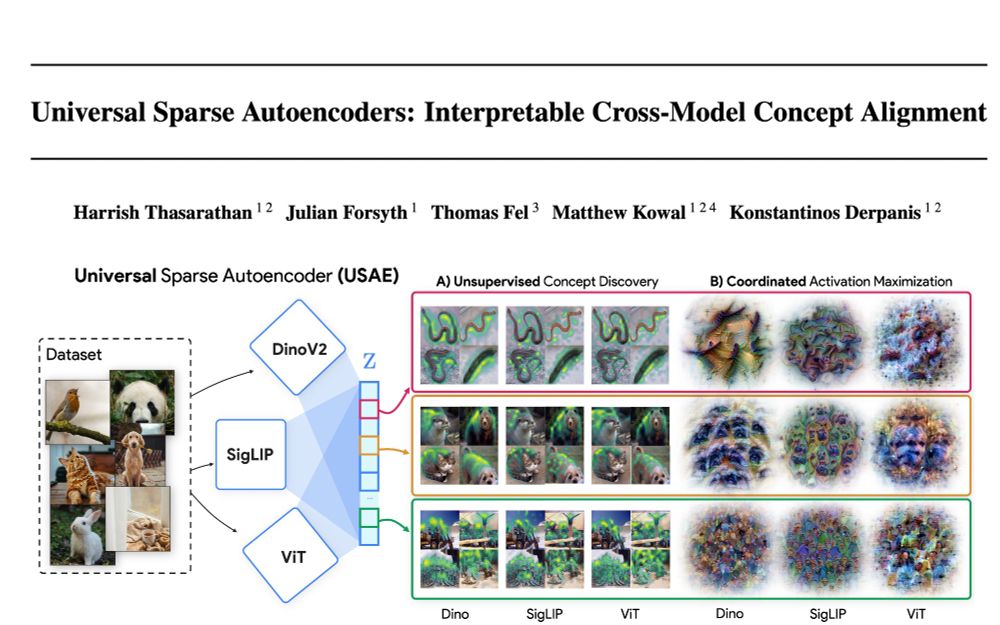
February 7, 2025 at 3:15 PM
🌌🛰️🔭Wanna know which features are universal vs unique in your models and how to find them? Excited to share our preprint: "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment"!
arxiv.org/abs/2502.03714
(1/9)
arxiv.org/abs/2502.03714
(1/9)
Reposted by Jane Wu

📢 ScanNet++ v2 Benchmark Release! 🏆
Test your state-of-the-art models on:
🔹 Novel View Synthesis 📸➡️🖼️
🔹 3D Semantic & Instance Segmentation 🤖🔍🕶️
Shoutout to @awhiteguitar.bsky.social & Yueh-Cheng Liu for their incredible work👏
🚀Check it out: kaldir.vc.in.tum.de/scannetpp/
Test your state-of-the-art models on:
🔹 Novel View Synthesis 📸➡️🖼️
🔹 3D Semantic & Instance Segmentation 🤖🔍🕶️
Shoutout to @awhiteguitar.bsky.social & Yueh-Cheng Liu for their incredible work👏
🚀Check it out: kaldir.vc.in.tum.de/scannetpp/
January 31, 2025 at 4:29 PM
📢 ScanNet++ v2 Benchmark Release! 🏆
Test your state-of-the-art models on:
🔹 Novel View Synthesis 📸➡️🖼️
🔹 3D Semantic & Instance Segmentation 🤖🔍🕶️
Shoutout to @awhiteguitar.bsky.social & Yueh-Cheng Liu for their incredible work👏
🚀Check it out: kaldir.vc.in.tum.de/scannetpp/
Test your state-of-the-art models on:
🔹 Novel View Synthesis 📸➡️🖼️
🔹 3D Semantic & Instance Segmentation 🤖🔍🕶️
Shoutout to @awhiteguitar.bsky.social & Yueh-Cheng Liu for their incredible work👏
🚀Check it out: kaldir.vc.in.tum.de/scannetpp/