



Ilyass Moummad
@ilyassmoummad.bsky.social
Postdoctoral Researcher @ Inria Montpellier (IROKO, Pl@ntNet)
SSL for plant images
Interested in Computer Vision, Natural Language Processing, Machine Listening, and Biodiversity Monitoring
Website: ilyassmoummad.github.io
SSL for plant images
Interested in Computer Vision, Natural Language Processing, Machine Listening, and Biodiversity Monitoring
Website: ilyassmoummad.github.io
Pinned
[1/10] Introducing CroVCA ✨
A simple, unified framework for supervised and unsupervised hashing that converts foundation model embeddings into compact binary codes.
✅ Preserves semantic structure
✅ Trains in just a few iterations
A simple, unified framework for supervised and unsupervised hashing that converts foundation model embeddings into compact binary codes.
✅ Preserves semantic structure
✅ Trains in just a few iterations
[1/10] Introducing CroVCA ✨
A simple, unified framework for supervised and unsupervised hashing that converts foundation model embeddings into compact binary codes.
✅ Preserves semantic structure
✅ Trains in just a few iterations
A simple, unified framework for supervised and unsupervised hashing that converts foundation model embeddings into compact binary codes.
✅ Preserves semantic structure
✅ Trains in just a few iterations
November 3, 2025 at 2:29 PM
[1/10] Introducing CroVCA ✨
A simple, unified framework for supervised and unsupervised hashing that converts foundation model embeddings into compact binary codes.
✅ Preserves semantic structure
✅ Trains in just a few iterations
A simple, unified framework for supervised and unsupervised hashing that converts foundation model embeddings into compact binary codes.
✅ Preserves semantic structure
✅ Trains in just a few iterations
Reposted by Ilyass Moummad

BioDCASE workshop - registration closes next week Oct 10th https://biodcase.github.io/workshop2025/ - Hope to see you there! #bioacoustics
BioDCASE Workshop - BioDCASE
Join us for the BioDCASE Workshop held in Barcelona, Spain on the 29th of October! The workshop will be held at the Campus del Poblenou of Universitat Pompeu Fabra. The BioDCASE workshop will be hosted the day before the DCASE workshop on the 30-31st of October at the same venue …
biodcase.github.io
October 3, 2025 at 10:17 AM
BioDCASE workshop - registration closes next week Oct 10th https://biodcase.github.io/workshop2025/ - Hope to see you there! #bioacoustics
A website to visually browse and explore the ImageNet-1k dataset (there are other supported datasets: IN-12M, WikiMedia, ETH Images, Pixabay, Fashion) navigu.net#imagenet
(Maybe this is already known, but I was happy to discover it this morning)
(Maybe this is already known, but I was happy to discover it this morning)

NAVIGU: a powerful image collection explorer.
NAVIGU lets you dive into the ocean of images. Drag the image sphere or double-click on an image you like to browse large collections.
navigu.net
August 27, 2025 at 7:39 AM
A website to visually browse and explore the ImageNet-1k dataset (there are other supported datasets: IN-12M, WikiMedia, ETH Images, Pixabay, Fashion) navigu.net#imagenet
(Maybe this is already known, but I was happy to discover it this morning)
(Maybe this is already known, but I was happy to discover it this morning)
Learning Deep Representations of Data Distributions
Sam Buchanan · Druv Pai · Peng Wang · Yi Ma
ma-lab-berkeley.github.io/deep-represe...
The best Deep Learning book is out, I've been waiting for its release for more than a year. Let's learn how to build intelligent systems via compression.
Sam Buchanan · Druv Pai · Peng Wang · Yi Ma
ma-lab-berkeley.github.io/deep-represe...
The best Deep Learning book is out, I've been waiting for its release for more than a year. Let's learn how to build intelligent systems via compression.
Learning Deep Representations of Data Distributions
Landing page for the book Learning Deep Representations of Data Distributions.
ma-lab-berkeley.github.io
August 23, 2025 at 6:27 AM
Learning Deep Representations of Data Distributions
Sam Buchanan · Druv Pai · Peng Wang · Yi Ma
ma-lab-berkeley.github.io/deep-represe...
The best Deep Learning book is out, I've been waiting for its release for more than a year. Let's learn how to build intelligent systems via compression.
Sam Buchanan · Druv Pai · Peng Wang · Yi Ma
ma-lab-berkeley.github.io/deep-represe...
The best Deep Learning book is out, I've been waiting for its release for more than a year. Let's learn how to build intelligent systems via compression.
Reposted by Ilyass Moummad

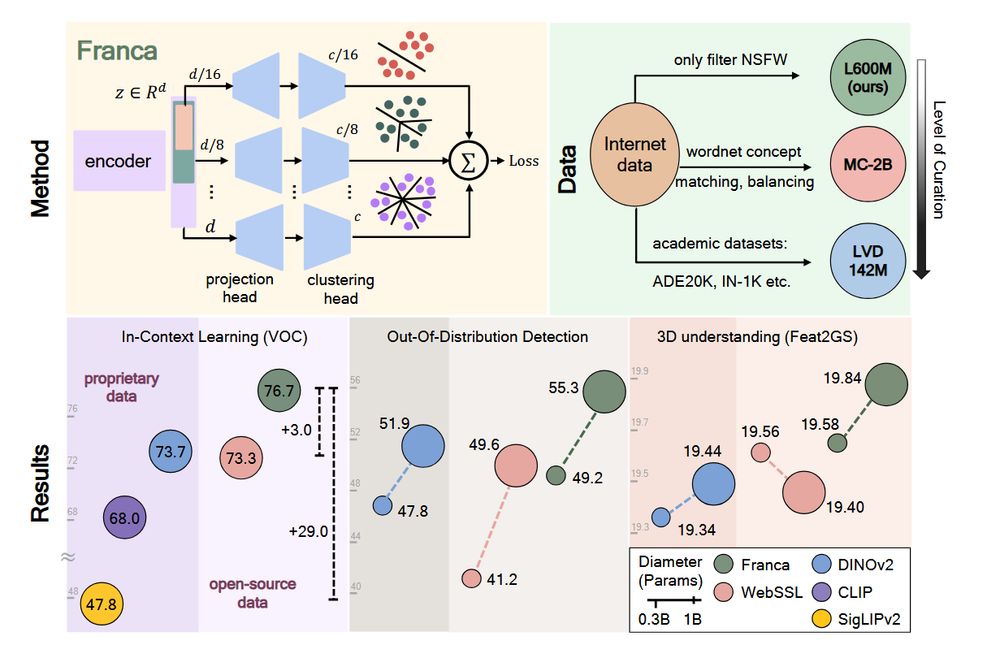
1/ Can open-data models beat DINOv2? Today we release Franca, a fully open-sourced vision foundation model. Franca with ViT-G backbone matches (and often beats) proprietary models like SigLIPv2, CLIP, DINOv2 on various benchmarks setting a new standard for open-source research.
July 21, 2025 at 2:47 PM
1/ Can open-data models beat DINOv2? Today we release Franca, a fully open-sourced vision foundation model. Franca with ViT-G backbone matches (and often beats) proprietary models like SigLIPv2, CLIP, DINOv2 on various benchmarks setting a new standard for open-source research.
Reposted by Ilyass Moummad

🏹 Job alert: Research Scientist at Prior Labs
📍Freiburg or Berlin 🇩🇪
📅 Apply by Dec 31 - preferably earlier
🔗 More info: https://bit.ly/4kqn5rY
📍Freiburg or Berlin 🇩🇪
📅 Apply by Dec 31 - preferably earlier
🔗 More info: https://bit.ly/4kqn5rY
Research Scientist
Build tabular foundation models and shape how the world works with its most valuable data. Opportunity to work on fundamental breakthroughs such as multimodal, causality and specialized architectures.
bit.ly
July 4, 2025 at 6:45 AM
🏹 Job alert: Research Scientist at Prior Labs
📍Freiburg or Berlin 🇩🇪
📅 Apply by Dec 31 - preferably earlier
🔗 More info: https://bit.ly/4kqn5rY
📍Freiburg or Berlin 🇩🇪
📅 Apply by Dec 31 - preferably earlier
🔗 More info: https://bit.ly/4kqn5rY
Reposted by Ilyass Moummad

Our computer vision textbook is now available for free online here:
visionbook.mit.edu
We are working on adding some interactive components like search and (beta) integration with LLMs.
Hope this is useful and feel free to submit Github issues to help us improve the text!
visionbook.mit.edu
We are working on adding some interactive components like search and (beta) integration with LLMs.
Hope this is useful and feel free to submit Github issues to help us improve the text!

Foundations of Computer Vision
The print version was published by
visionbook.mit.edu
June 15, 2025 at 3:45 PM
Our computer vision textbook is now available for free online here:
visionbook.mit.edu
We are working on adding some interactive components like search and (beta) integration with LLMs.
Hope this is useful and feel free to submit Github issues to help us improve the text!
visionbook.mit.edu
We are working on adding some interactive components like search and (beta) integration with LLMs.
Hope this is useful and feel free to submit Github issues to help us improve the text!
Reposted by Ilyass Moummad

⚠️❗Open PhD and Postdoc positions in Prague with Lukas Neumann! ❗⚠️
We rank #5 in computer vision in Europe and Lukas is a great supervisor, so this is a great opportunity!
If you are interested, contact him, he will also be at CVPR with his group :)
We rank #5 in computer vision in Europe and Lukas is a great supervisor, so this is a great opportunity!
If you are interested, contact him, he will also be at CVPR with his group :)

June 9, 2025 at 12:17 PM
⚠️❗Open PhD and Postdoc positions in Prague with Lukas Neumann! ❗⚠️
We rank #5 in computer vision in Europe and Lukas is a great supervisor, so this is a great opportunity!
If you are interested, contact him, he will also be at CVPR with his group :)
We rank #5 in computer vision in Europe and Lukas is a great supervisor, so this is a great opportunity!
If you are interested, contact him, he will also be at CVPR with his group :)
Reposted by Ilyass Moummad
We will be presenting the 🍄 FungiTastic 🍄, a multimodal, highly challenging dataset and benchmark covering many ML problems at @fgvcworkshop.bsky.social CVPR-W on Wednesday!
⏱️ 16:15
📍104 E, Level 1
📸 www.kaggle.com/datasets/pic...
📃 arxiv.org/abs/2408.13632
@cvprconference.bsky.social
⏱️ 16:15
📍104 E, Level 1
📸 www.kaggle.com/datasets/pic...
📃 arxiv.org/abs/2408.13632
@cvprconference.bsky.social

June 6, 2025 at 4:44 PM
We will be presenting the 🍄 FungiTastic 🍄, a multimodal, highly challenging dataset and benchmark covering many ML problems at @fgvcworkshop.bsky.social CVPR-W on Wednesday!
⏱️ 16:15
📍104 E, Level 1
📸 www.kaggle.com/datasets/pic...
📃 arxiv.org/abs/2408.13632
@cvprconference.bsky.social
⏱️ 16:15
📍104 E, Level 1
📸 www.kaggle.com/datasets/pic...
📃 arxiv.org/abs/2408.13632
@cvprconference.bsky.social
Reposted by Ilyass Moummad

Want stronger Vision Transformers? Use octic-equivariant layers (arxiv.org/abs/2505.15441).
TLDR; We extend @bokmangeorg.bsky.social's reflection-equivariant ViTs to the (octic) group of 90-degree rotations and reflections and... it just works... (DINOv2+DeiT)
Code: github.com/davnords/octic-vits
TLDR; We extend @bokmangeorg.bsky.social's reflection-equivariant ViTs to the (octic) group of 90-degree rotations and reflections and... it just works... (DINOv2+DeiT)
Code: github.com/davnords/octic-vits

May 23, 2025 at 7:38 AM
Want stronger Vision Transformers? Use octic-equivariant layers (arxiv.org/abs/2505.15441).
TLDR; We extend @bokmangeorg.bsky.social's reflection-equivariant ViTs to the (octic) group of 90-degree rotations and reflections and... it just works... (DINOv2+DeiT)
Code: github.com/davnords/octic-vits
TLDR; We extend @bokmangeorg.bsky.social's reflection-equivariant ViTs to the (octic) group of 90-degree rotations and reflections and... it just works... (DINOv2+DeiT)
Code: github.com/davnords/octic-vits
Reposted by Ilyass Moummad

Interesting paper on getting representations from unconditional diffusion models: arxiv.org/abs/2506.01912
(Was excepting more theoretical insights, but nice nonetheless)
(Was excepting more theoretical insights, but nice nonetheless)

Elucidating the representation of images within an unconditional diffusion model denoiser
Generative diffusion models learn probability densities over diverse image datasets by estimating the score with a neural network trained to remove noise. Despite their remarkable success in generatin...
arxiv.org
June 3, 2025 at 6:37 AM
Interesting paper on getting representations from unconditional diffusion models: arxiv.org/abs/2506.01912
(Was excepting more theoretical insights, but nice nonetheless)
(Was excepting more theoretical insights, but nice nonetheless)
Reposted by Ilyass Moummad

Want to use SOTA Self Supervised Learning (SSL) methods on noisy data? We provide a novel training curriculum that significantly improves test performance on clean and noisy samples! The approach is fully SSL and works on any method (DINOv2, MoCo, ...)
arxiv.org/abs/2505.12191
arxiv.org/abs/2505.12191

Ditch the Denoiser: Emergence of Noise Robustness in Self-Supervised Learning from Data Curriculum
Self-Supervised Learning (SSL) has become a powerful solution to extract rich representations from unlabeled data. Yet, SSL research is mostly focused on clean, curated and high-quality datasets. As a...
arxiv.org
May 20, 2025 at 2:38 PM
Want to use SOTA Self Supervised Learning (SSL) methods on noisy data? We provide a novel training curriculum that significantly improves test performance on clean and noisy samples! The approach is fully SSL and works on any method (DINOv2, MoCo, ...)
arxiv.org/abs/2505.12191
arxiv.org/abs/2505.12191
Reposted by Ilyass Moummad

Convolution theorem: Fourier transform of the convolution of two functions (under suitable assumptions) is the product of the Fourier transforms of these two functions. buff.ly/aOamDMF

May 7, 2025 at 5:01 AM
Convolution theorem: Fourier transform of the convolution of two functions (under suitable assumptions) is the product of the Fourier transforms of these two functions. buff.ly/aOamDMF
Reposted by Ilyass Moummad

J'ai le plaisir d'annoncer la soutenance de mon habilitation à diriger des recherches de l'Université Gustave Eiffel, intitulée
« Apprentissage de représentations à partir d'observations »
le mardi 20 mai 2025 à 14h00. 😀
ℹ️ Informations pratiques : nicolas.audebert.at/files/HDR
« Apprentissage de représentations à partir d'observations »
le mardi 20 mai 2025 à 14h00. 😀
ℹ️ Informations pratiques : nicolas.audebert.at/files/HDR

Soutenance HDR - Nicolas Audebert
Mardi 20 mai - 14h00, Amphi Laussédat, Cnam Paris
Apprentissage de représentations à partir d'observations
nicolas.audebert.at
May 2, 2025 at 3:21 PM
J'ai le plaisir d'annoncer la soutenance de mon habilitation à diriger des recherches de l'Université Gustave Eiffel, intitulée
« Apprentissage de représentations à partir d'observations »
le mardi 20 mai 2025 à 14h00. 😀
ℹ️ Informations pratiques : nicolas.audebert.at/files/HDR
« Apprentissage de représentations à partir d'observations »
le mardi 20 mai 2025 à 14h00. 😀
ℹ️ Informations pratiques : nicolas.audebert.at/files/HDR
Reposted by Ilyass Moummad

Perception Encoder: The best visual embeddings
are not at the output of the network
Daniel Bolya et 17 al.
tl;dr: really in title + they propose a new model.
arxiv.org/abs/2504.13181
are not at the output of the network
Daniel Bolya et 17 al.
tl;dr: really in title + they propose a new model.
arxiv.org/abs/2504.13181




April 28, 2025 at 9:18 AM
Perception Encoder: The best visual embeddings
are not at the output of the network
Daniel Bolya et 17 al.
tl;dr: really in title + they propose a new model.
arxiv.org/abs/2504.13181
are not at the output of the network
Daniel Bolya et 17 al.
tl;dr: really in title + they propose a new model.
arxiv.org/abs/2504.13181
Reposted by Ilyass Moummad
2 jobs in our group at Tilburg University: "Postdoctoral researcher in AI: Learning from Sparse Examples" #nlp postdoc https://tiu.nu/22749 AND #computervision postdoc https://tiu.nu/22748 #postdoc #academicjobs #netherlands #TilburgU
Job opening: Postdoctoral researcher in Artificial Intelligence: Learning from Sparse Examples Natural Language (22749)
career5.successfactors.eu
April 24, 2025 at 2:23 PM
2 jobs in our group at Tilburg University: "Postdoctoral researcher in AI: Learning from Sparse Examples" #nlp postdoc https://tiu.nu/22749 AND #computervision postdoc https://tiu.nu/22748 #postdoc #academicjobs #netherlands #TilburgU
Reposted by Ilyass Moummad

🚀🚀 Reconstruct-Anything-Model: A single model to rule all imaging tasks!
We challenge current beliefs and show that a single U-Net can obtain impressive performance across a wide variety of tasks, **without** relying on expensive iterative schemes such as unrolling, PnP, diffusion
We challenge current beliefs and show that a single U-Net can obtain impressive performance across a wide variety of tasks, **without** relying on expensive iterative schemes such as unrolling, PnP, diffusion
April 16, 2025 at 8:23 AM
🚀🚀 Reconstruct-Anything-Model: A single model to rule all imaging tasks!
We challenge current beliefs and show that a single U-Net can obtain impressive performance across a wide variety of tasks, **without** relying on expensive iterative schemes such as unrolling, PnP, diffusion
We challenge current beliefs and show that a single U-Net can obtain impressive performance across a wide variety of tasks, **without** relying on expensive iterative schemes such as unrolling, PnP, diffusion
Reposted by Ilyass Moummad
🚢🚢 deepinv v0.3.0 is here, with many new features! 🚢 🚢
Our passionate team of contributors keeps shipping more exciting tools!
Deepinverse (deepinv.github.io) is a library for solving imaging inverse problems with deep learning.
Our passionate team of contributors keeps shipping more exciting tools!
Deepinverse (deepinv.github.io) is a library for solving imaging inverse problems with deep learning.
Redirecting to https://deepinv.github.io/deepinv/
deepinv.github.io
April 14, 2025 at 6:33 AM
🚢🚢 deepinv v0.3.0 is here, with many new features! 🚢 🚢
Our passionate team of contributors keeps shipping more exciting tools!
Deepinverse (deepinv.github.io) is a library for solving imaging inverse problems with deep learning.
Our passionate team of contributors keeps shipping more exciting tools!
Deepinverse (deepinv.github.io) is a library for solving imaging inverse problems with deep learning.
Reposted by Ilyass Moummad

Applications are 📣OPEN📣 for #PAISS2025 THE AI summer school in #Grenoble 1-5 Sept! Speakers so far @yann-lecun.bsky.social @dimadamen.bsky.social @arthurgretton.bsky.social @gabrielpeyre.bsky.social @science4all.org A. Cristia J. Revaud M. Caron J. Carpentier M. Vladimirova ➡️ paiss.inria.fr

April 11, 2025 at 1:44 PM
Applications are 📣OPEN📣 for #PAISS2025 THE AI summer school in #Grenoble 1-5 Sept! Speakers so far @yann-lecun.bsky.social @dimadamen.bsky.social @arthurgretton.bsky.social @gabrielpeyre.bsky.social @science4all.org A. Cristia J. Revaud M. Caron J. Carpentier M. Vladimirova ➡️ paiss.inria.fr
Reposted by Ilyass Moummad

Just launched: the BioDCASE challenge! Monitor whales, birds and other animals, through their sounds? We're publishing new datasets, and new evaluations, to help you do so! Please join this new challenge, and please spread the word: biodcase.github.io #bioacoustics #machinelistening #ai4good

April 2, 2025 at 4:30 PM
Just launched: the BioDCASE challenge! Monitor whales, birds and other animals, through their sounds? We're publishing new datasets, and new evaluations, to help you do so! Please join this new challenge, and please spread the word: biodcase.github.io #bioacoustics #machinelistening #ai4good
Reposted by Ilyass Moummad

Just to share a bit of academic content… have you heard of VoRA? arxiv.org/abs/2503.20680 🙃

Vision as LoRA
We introduce Vision as LoRA (VoRA), a novel paradigm for transforming an LLM into an MLLM. Unlike prevalent MLLM architectures that rely on external vision modules for vision encoding, VoRA internaliz...
arxiv.org
March 27, 2025 at 6:25 PM
Just to share a bit of academic content… have you heard of VoRA? arxiv.org/abs/2503.20680 🙃
Reposted by Ilyass Moummad
Come and work with us! Be a Postdoctoral Fellow in AI for Ultrasonic Bioacoustic Monitoring! All the details: https://www.naturalis.nl/en/about-us/job-opportunities/postdoctoral-fellow-in-ai-for-ultrasonic-bioacoustic-monitoring #academicjobs #postdoc #pdra #netherlands #biodiversity #ai […]
Original post on mastodon.social
mastodon.social
March 21, 2025 at 11:46 AM
Come and work with us! Be a Postdoctoral Fellow in AI for Ultrasonic Bioacoustic Monitoring! All the details: https://www.naturalis.nl/en/about-us/job-opportunities/postdoctoral-fellow-in-ai-for-ultrasonic-bioacoustic-monitoring #academicjobs #postdoc #pdra #netherlands #biodiversity #ai […]
Reposted by Ilyass Moummad
In case it's not clear! You can register even if you don't have a paper. The event is designed for you 🤗
🔥🔥🔥 CV Folks, I have some news! We're organizing a 1-day meeting in center Paris on June 6th before CVPR called CVPR@Paris (similar as NeurIPS@Paris) 🥐🍾🥖🍷
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!


March 21, 2025 at 9:04 AM
In case it's not clear! You can register even if you don't have a paper. The event is designed for you 🤗
Reposted by Ilyass Moummad

Tomorrow in our TUM AI - Lecture Series we'll have none other than Saining Xie (@saining.bsky.social), NYU
He'll talk about "𝐓𝐡𝐞 𝐦𝐮𝐥𝐭𝐢𝐦𝐨𝐝𝐚𝐥 𝐟𝐮𝐭𝐮𝐫𝐞: Why visual representation still matters".
Live stream: www.youtube.com/live/hnu-mRL...
5pm GMT+1 / 9am PST (Mon Mar 17th)
He'll talk about "𝐓𝐡𝐞 𝐦𝐮𝐥𝐭𝐢𝐦𝐨𝐝𝐚𝐥 𝐟𝐮𝐭𝐮𝐫𝐞: Why visual representation still matters".
Live stream: www.youtube.com/live/hnu-mRL...
5pm GMT+1 / 9am PST (Mon Mar 17th)

TUM AI Lecture Series - The multimodal future: Why visual representation still matters (Saining Xie)
YouTube video by Matthias Niessner
www.youtube.com
March 16, 2025 at 12:50 PM
Tomorrow in our TUM AI - Lecture Series we'll have none other than Saining Xie (@saining.bsky.social), NYU
He'll talk about "𝐓𝐡𝐞 𝐦𝐮𝐥𝐭𝐢𝐦𝐨𝐝𝐚𝐥 𝐟𝐮𝐭𝐮𝐫𝐞: Why visual representation still matters".
Live stream: www.youtube.com/live/hnu-mRL...
5pm GMT+1 / 9am PST (Mon Mar 17th)
He'll talk about "𝐓𝐡𝐞 𝐦𝐮𝐥𝐭𝐢𝐦𝐨𝐝𝐚𝐥 𝐟𝐮𝐭𝐮𝐫𝐞: Why visual representation still matters".
Live stream: www.youtube.com/live/hnu-mRL...
5pm GMT+1 / 9am PST (Mon Mar 17th)
Reposted by Ilyass Moummad

We present Thera🔥: The new SOTA arbitrary-scale super-resolution method with built-in anti-aliasing. Our approach introduces Neural Heat Fields, which guarantee exact Gaussian filtering at any scale, enabling continuous image reconstruction without extra computational cost.
March 14, 2025 at 2:18 PM
We present Thera🔥: The new SOTA arbitrary-scale super-resolution method with built-in anti-aliasing. Our approach introduces Neural Heat Fields, which guarantee exact Gaussian filtering at any scale, enabling continuous image reconstruction without extra computational cost.