



Hanlin Zhang
@hlzhang109.bsky.social
CS PhD student @Harvard
https://hanlin-zhang.com
https://hanlin-zhang.com
Introducing EvoLM, a model suite with 100+ decoder-only LMs (1B/4B) trained from scratch, across four training stages —
🟦 Pre-training
🟩 Continued Pre-Training (CPT)
🟨 Supervised Fine-Tuning (SFT)
🟥 Reinforcement Learning (RL)
🟦 Pre-training
🟩 Continued Pre-Training (CPT)
🟨 Supervised Fine-Tuning (SFT)
🟥 Reinforcement Learning (RL)

EvoLM: In Search of Lost Language Model Training Dynamics
Modern language model (LM) training has been divided into multiple stages, making it difficult for downstream developers to evaluate the impact of design choices made at each stage. We present EvoLM, ...
arxiv.org
July 2, 2025 at 8:05 PM
Introducing EvoLM, a model suite with 100+ decoder-only LMs (1B/4B) trained from scratch, across four training stages —
🟦 Pre-training
🟩 Continued Pre-Training (CPT)
🟨 Supervised Fine-Tuning (SFT)
🟥 Reinforcement Learning (RL)
🟦 Pre-training
🟩 Continued Pre-Training (CPT)
🟨 Supervised Fine-Tuning (SFT)
🟥 Reinforcement Learning (RL)
New work [JSKZ25] w/ Jikai, Vasilis,
@shamkakade.bsky.social .
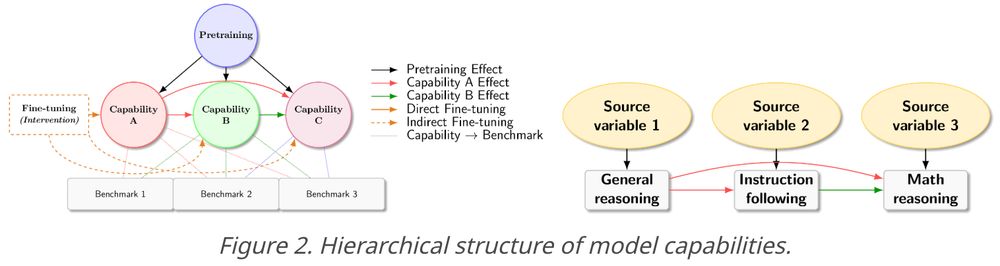
We introduce new formulations and tools for evaluating LM capabilities, which help explain observations of post-training behaviors of Qwen-series models.
More details:
- hanlin-zhang.com/causal-capab...
- x.com/_hanlin_zhan...
@shamkakade.bsky.social .
We introduce new formulations and tools for evaluating LM capabilities, which help explain observations of post-training behaviors of Qwen-series models.
More details:
- hanlin-zhang.com/causal-capab...
- x.com/_hanlin_zhan...
June 18, 2025 at 6:02 PM
New work [JSKZ25] w/ Jikai, Vasilis,
@shamkakade.bsky.social .
We introduce new formulations and tools for evaluating LM capabilities, which help explain observations of post-training behaviors of Qwen-series models.
More details:
- hanlin-zhang.com/causal-capab...
- x.com/_hanlin_zhan...
@shamkakade.bsky.social .
We introduce new formulations and tools for evaluating LM capabilities, which help explain observations of post-training behaviors of Qwen-series models.
More details:
- hanlin-zhang.com/causal-capab...
- x.com/_hanlin_zhan...
Reposted by Hanlin Zhang

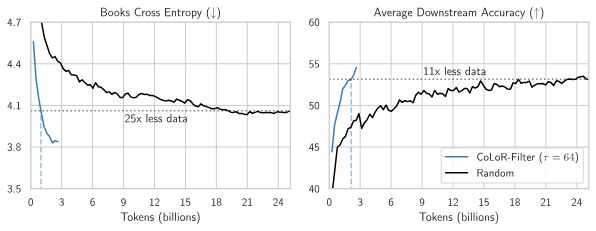
I want to reshare @brandfonbrener.bsky.social's @NeurIPSConf 2024 paper on CoLoR-Filter: A simple yet powerful method for selecting high-quality data for language model pre-training!
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
April 5, 2025 at 12:04 PM
I want to reshare @brandfonbrener.bsky.social's @NeurIPSConf 2024 paper on CoLoR-Filter: A simple yet powerful method for selecting high-quality data for language model pre-training!
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
Reposted by Hanlin Zhang

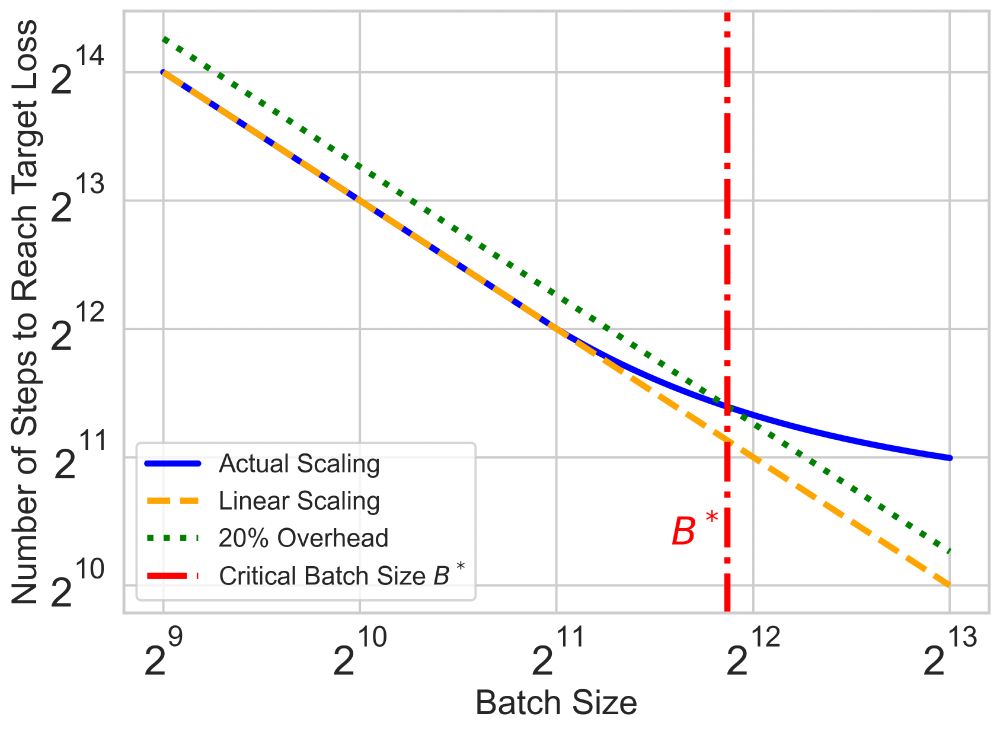
(1/n) 💡How can we speed up the serial runtime of long pre-training runs? Enter Critical Batch Size (CBS): the tipping point where the gains of data parallelism balance with diminishing efficiency. Doubling batch size halves the optimization steps—until we hit CBS, beyond which returns diminish.
November 22, 2024 at 8:19 PM
(1/n) 💡How can we speed up the serial runtime of long pre-training runs? Enter Critical Batch Size (CBS): the tipping point where the gains of data parallelism balance with diminishing efficiency. Doubling batch size halves the optimization steps—until we hit CBS, beyond which returns diminish.
Reposted by Hanlin Zhang

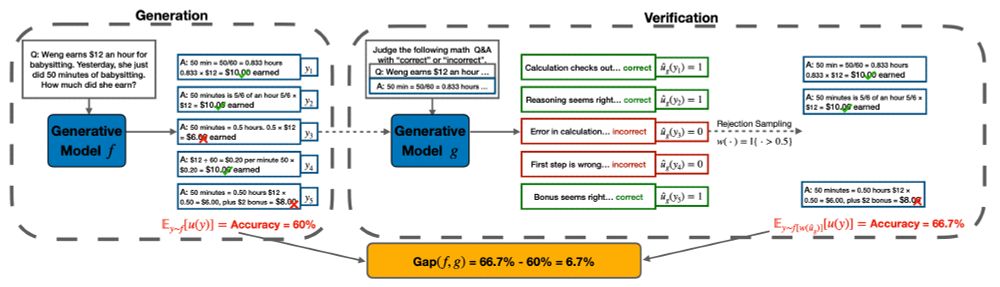
LLM self-improvement has critical implications in synthetic data, post-training and test-time inference. To understand LLMs' true capability of self-improvement, we perform large-scale experiments with multiple families of LLMs, tasks and mechanisms. Here is what we found: (1/9)
December 6, 2024 at 6:02 PM
LLM self-improvement has critical implications in synthetic data, post-training and test-time inference. To understand LLMs' true capability of self-improvement, we perform large-scale experiments with multiple families of LLMs, tasks and mechanisms. Here is what we found: (1/9)