


Reposted by Daniel Chechelnitsky

We're surveying researchers about name changes in academic publishing.
If you've changed your name and dealt with updating publications, we want to hear your experience. Any reason counts: transition, marriage, cultural reasons, etc.
forms.cloud.microsoft/e/E0XXBmZdEP
If you've changed your name and dealt with updating publications, we want to hear your experience. Any reason counts: transition, marriage, cultural reasons, etc.
forms.cloud.microsoft/e/E0XXBmZdEP

October 21, 2025 at 12:45 PM
We're surveying researchers about name changes in academic publishing.
If you've changed your name and dealt with updating publications, we want to hear your experience. Any reason counts: transition, marriage, cultural reasons, etc.
forms.cloud.microsoft/e/E0XXBmZdEP
If you've changed your name and dealt with updating publications, we want to hear your experience. Any reason counts: transition, marriage, cultural reasons, etc.
forms.cloud.microsoft/e/E0XXBmZdEP
Reposted by Daniel Chechelnitsky

tomorrow 6/20, i'm presenting this paper at #alt_FAccT, a NYC local meeting for @FAccTConference
✨🎤 paper session #3 🎤✨
🗽1:30pm June 20, Fri @ MSR NYC🗽
⬇️ our #FAccT2025 paper is abt “what if ur ChatGPT spoke queer slang and AAVE?”
📚🔗 bit.ly/not-like-us
✨🎤 paper session #3 🎤✨
🗽1:30pm June 20, Fri @ MSR NYC🗽
⬇️ our #FAccT2025 paper is abt “what if ur ChatGPT spoke queer slang and AAVE?”
📚🔗 bit.ly/not-like-us

June 20, 2025 at 12:13 AM
tomorrow 6/20, i'm presenting this paper at #alt_FAccT, a NYC local meeting for @FAccTConference
✨🎤 paper session #3 🎤✨
🗽1:30pm June 20, Fri @ MSR NYC🗽
⬇️ our #FAccT2025 paper is abt “what if ur ChatGPT spoke queer slang and AAVE?”
📚🔗 bit.ly/not-like-us
✨🎤 paper session #3 🎤✨
🗽1:30pm June 20, Fri @ MSR NYC🗽
⬇️ our #FAccT2025 paper is abt “what if ur ChatGPT spoke queer slang and AAVE?”
📚🔗 bit.ly/not-like-us
What if AI played the role of your sassy gay bestie 🏳️🌈 or AAVE-speaking friend 👋🏾?
You: “Can you plan a trip?”
🤖 AI: “Yasss queen! let’s werk this babe✨💅”
LLMs can talk like us, but it shapes how we trust, rely on & relate to them 🧵
📣 our #FAccT2025 paper: bit.ly/3HJ6rWI
[1/9]
You: “Can you plan a trip?”
🤖 AI: “Yasss queen! let’s werk this babe✨💅”
LLMs can talk like us, but it shapes how we trust, rely on & relate to them 🧵
📣 our #FAccT2025 paper: bit.ly/3HJ6rWI
[1/9]

June 17, 2025 at 7:39 PM
What if AI played the role of your sassy gay bestie 🏳️🌈 or AAVE-speaking friend 👋🏾?
You: “Can you plan a trip?”
🤖 AI: “Yasss queen! let’s werk this babe✨💅”
LLMs can talk like us, but it shapes how we trust, rely on & relate to them 🧵
📣 our #FAccT2025 paper: bit.ly/3HJ6rWI
[1/9]
You: “Can you plan a trip?”
🤖 AI: “Yasss queen! let’s werk this babe✨💅”
LLMs can talk like us, but it shapes how we trust, rely on & relate to them 🧵
📣 our #FAccT2025 paper: bit.ly/3HJ6rWI
[1/9]
Reposted by Daniel Chechelnitsky

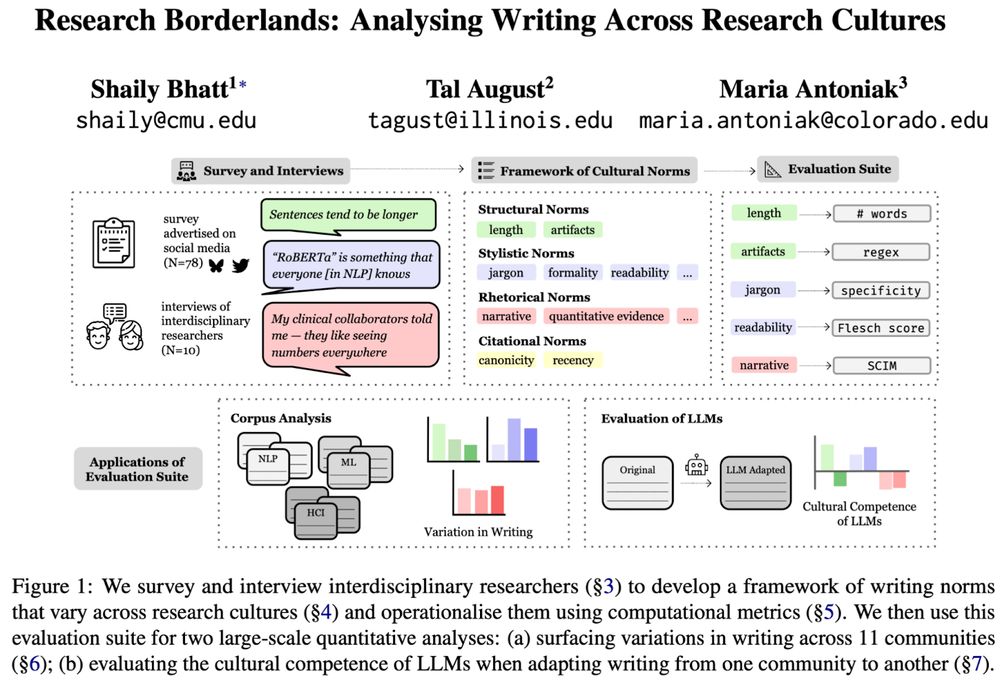
🖋️ Curious how writing differs across (research) cultures?
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
June 9, 2025 at 11:30 PM
🖋️ Curious how writing differs across (research) cultures?
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
Reposted by Daniel Chechelnitsky

🏳️🌈🎨💻📢 Happy to share our workshop study on queer artists’ experiences critically engaging with GenAI
Looking forward to presenting this work at #FAccT2025 and you can read a pre-print here:
arxiv.org/abs/2503.09805
Looking forward to presenting this work at #FAccT2025 and you can read a pre-print here:
arxiv.org/abs/2503.09805

May 14, 2025 at 6:38 PM
🏳️🌈🎨💻📢 Happy to share our workshop study on queer artists’ experiences critically engaging with GenAI
Looking forward to presenting this work at #FAccT2025 and you can read a pre-print here:
arxiv.org/abs/2503.09805
Looking forward to presenting this work at #FAccT2025 and you can read a pre-print here:
arxiv.org/abs/2503.09805
Reposted by Daniel Chechelnitsky

RLHF is built upon some quite oversimplistic assumptions, i.e., that preferences between pairs of text are purely about quality. But this is an inherently subjective task (not unlike toxicity annotation) -- so we wanted to know, do biases similar to toxicity annotation emerge in reward models?
Reward models for LMs are meant to align outputs with human preferences—but do they accidentally encode dialect biases? 🤔
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)

March 6, 2025 at 8:54 PM
RLHF is built upon some quite oversimplistic assumptions, i.e., that preferences between pairs of text are purely about quality. But this is an inherently subjective task (not unlike toxicity annotation) -- so we wanted to know, do biases similar to toxicity annotation emerge in reward models?
Reposted by Daniel Chechelnitsky

Reward models for LMs are meant to align outputs with human preferences—but do they accidentally encode dialect biases? 🤔
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)
March 6, 2025 at 7:49 PM
Reward models for LMs are meant to align outputs with human preferences—but do they accidentally encode dialect biases? 🤔
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)
Reposted by Daniel Chechelnitsky

Looking for all your LTI friends on Bluesky? The LTI Starter Pack is here to help!
go.bsky.app/NhTwCVb
go.bsky.app/NhTwCVb
November 20, 2024 at 4:15 PM
Looking for all your LTI friends on Bluesky? The LTI Starter Pack is here to help!
go.bsky.app/NhTwCVb
go.bsky.app/NhTwCVb