



Brad Knox
@bradknox.bsky.social
Research Associate Professor in CS at UT Austin. I research how humans can specify aligned reward functions.
We're a couple of months into this exciting initiative, AHOI, and we've had two great speakers so far: Joe Carlsmith and Ryan Lowe. Check out our website for future speakers, videos of past talks, and our email list.
liberalarts.utexas.edu/news/ai-huma...
liberalarts.utexas.edu/news/ai-huma...

AI+Human Objectives Initiative at UT Austin Receives Grant from Coefficient Giving
AUSTIN, Texas — The AI+Human Objectives Initiative (AHOI) at The University of Texas at Austin has received an award from the grantmaking organization Coefficient Giving. The grant will fund AHOI’s wo...
liberalarts.utexas.edu
November 18, 2025 at 10:12 PM
We're a couple of months into this exciting initiative, AHOI, and we've had two great speakers so far: Joe Carlsmith and Ryan Lowe. Check out our website for future speakers, videos of past talks, and our email list.
liberalarts.utexas.edu/news/ai-huma...
liberalarts.utexas.edu/news/ai-huma...
Our paper, Towards Improving Reward Design in RL: A Reward Alignment Metric for RL Practitioners, won the Outstanding Paper Award on Emerging Topics in Reinforcement Learning this year at RLC! Congrats to 1st author @cmuslima.bsky.social!
Paper: sites.google.com/ualberta.ca/...
Paper: sites.google.com/ualberta.ca/...

August 8, 2025 at 12:21 AM
Our paper, Towards Improving Reward Design in RL: A Reward Alignment Metric for RL Practitioners, won the Outstanding Paper Award on Emerging Topics in Reinforcement Learning this year at RLC! Congrats to 1st author @cmuslima.bsky.social!
Paper: sites.google.com/ualberta.ca/...
Paper: sites.google.com/ualberta.ca/...
Reposted by Brad Knox

Propose some socials for RLC! Research topics, affinity groups, niche interests, whatever comes to mind!
rl-conference.cc/call_for_soc...
rl-conference.cc/call_for_soc...
RLC Call for Workshops
rl-conference.cc
June 25, 2025 at 1:26 PM
Propose some socials for RLC! Research topics, affinity groups, niche interests, whatever comes to mind!
rl-conference.cc/call_for_soc...
rl-conference.cc/call_for_soc...
To do non-LLM RLHF research with real, non-author HUMAN data, last I checked there were few datasets available. Synthetic data is usually quite unrealistic, compromising your results (see bradknox.net/human-prefer...).
Our dataset (and code) with real humans: dataverse.tdl.org/dataset.xhtm...
Our dataset (and code) with real humans: dataverse.tdl.org/dataset.xhtm...
Models of human preference for learning reward functions – Brad Knox, PhD
bradknox.net
April 30, 2025 at 4:47 PM
To do non-LLM RLHF research with real, non-author HUMAN data, last I checked there were few datasets available. Synthetic data is usually quite unrealistic, compromising your results (see bradknox.net/human-prefer...).
Our dataset (and code) with real humans: dataverse.tdl.org/dataset.xhtm...
Our dataset (and code) with real humans: dataverse.tdl.org/dataset.xhtm...
Vibecoding apparently requires a magic touch I lack. In two attempts from scratch, Cursor AI + Claude 3.5 goes off the rails constantly and has eventually degenerated into non-functionality.
Degeneration #2: Claude is only pretending to run terminal commands and edit my code. 🤦
Degeneration #2: Claude is only pretending to run terminal commands and edit my code. 🤦

March 4, 2025 at 6:01 PM
Vibecoding apparently requires a magic touch I lack. In two attempts from scratch, Cursor AI + Claude 3.5 goes off the rails constantly and has eventually degenerated into non-functionality.
Degeneration #2: Claude is only pretending to run terminal commands and edit my code. 🤦
Degeneration #2: Claude is only pretending to run terminal commands and edit my code. 🤦
Calling a reward function dense or sparse is a misnomer, AFAICT. (1/n)
February 24, 2025 at 5:27 PM
Calling a reward function dense or sparse is a misnomer, AFAICT. (1/n)
Reposted by Brad Knox

Some extra motivation for those of you in RLC deadline mode: our line-up of keynote speakers -- as all accepted papers get a talk, they may attend yours!
@rl-conference.bsky.social
@rl-conference.bsky.social

February 24, 2025 at 11:16 AM
Some extra motivation for those of you in RLC deadline mode: our line-up of keynote speakers -- as all accepted papers get a talk, they may attend yours!
@rl-conference.bsky.social
@rl-conference.bsky.social
Reposted by Brad Knox
Excited to announce the first RLC 2025 keynote speaker, a researcher who needs little introduction, whose textbook we've all read, and who keeps pushing the frontier on RL with human-level sample efficiency

January 8, 2025 at 3:03 PM
Excited to announce the first RLC 2025 keynote speaker, a researcher who needs little introduction, whose textbook we've all read, and who keeps pushing the frontier on RL with human-level sample efficiency
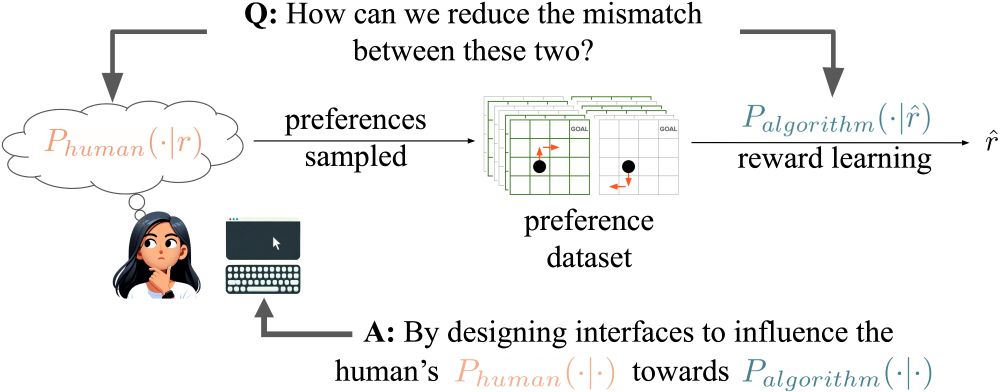
RLHF algorithms assume humans generate preferences according to normative models. We propose a new method for model alignment: influence humans to conform to these assumptions through interface design. Good news: it works!
#AI #MachineLearning #RLHF #Alignment (1/n)
#AI #MachineLearning #RLHF #Alignment (1/n)

January 14, 2025 at 11:51 PM
RLHF algorithms assume humans generate preferences according to normative models. We propose a new method for model alignment: influence humans to conform to these assumptions through interface design. Good news: it works!
#AI #MachineLearning #RLHF #Alignment (1/n)
#AI #MachineLearning #RLHF #Alignment (1/n)