



Brad Knox
@bradknox.bsky.social
Research Associate Professor in CS at UT Austin. I research how humans can specify aligned reward functions.
Our paper, Towards Improving Reward Design in RL: A Reward Alignment Metric for RL Practitioners, won the Outstanding Paper Award on Emerging Topics in Reinforcement Learning this year at RLC! Congrats to 1st author @cmuslima.bsky.social!
Paper: sites.google.com/ualberta.ca/...
Paper: sites.google.com/ualberta.ca/...

August 8, 2025 at 12:21 AM
Our paper, Towards Improving Reward Design in RL: A Reward Alignment Metric for RL Practitioners, won the Outstanding Paper Award on Emerging Topics in Reinforcement Learning this year at RLC! Congrats to 1st author @cmuslima.bsky.social!
Paper: sites.google.com/ualberta.ca/...
Paper: sites.google.com/ualberta.ca/...
Vibecoding apparently requires a magic touch I lack. In two attempts from scratch, Cursor AI + Claude 3.5 goes off the rails constantly and has eventually degenerated into non-functionality.
Degeneration #2: Claude is only pretending to run terminal commands and edit my code. 🤦
Degeneration #2: Claude is only pretending to run terminal commands and edit my code. 🤦

March 4, 2025 at 6:01 PM
Vibecoding apparently requires a magic touch I lack. In two attempts from scratch, Cursor AI + Claude 3.5 goes off the rails constantly and has eventually degenerated into non-functionality.
Degeneration #2: Claude is only pretending to run terminal commands and edit my code. 🤦
Degeneration #2: Claude is only pretending to run terminal commands and edit my code. 🤦
Study 3: Simply changing the question asked during preference elicitation. (7/n)

January 14, 2025 at 11:51 PM
Study 3: Simply changing the question asked during preference elicitation. (7/n)
Study 2: Training people to follow a specific preference model. (6/n)

January 14, 2025 at 11:51 PM
Study 2: Training people to follow a specific preference model. (6/n)
Study 1 intervention: Show humans the quantities that underlie a preference model---normally unobservable information derived from the reward function. (5/n)

January 14, 2025 at 11:51 PM
Study 1 intervention: Show humans the quantities that underlie a preference model---normally unobservable information derived from the reward function. (5/n)
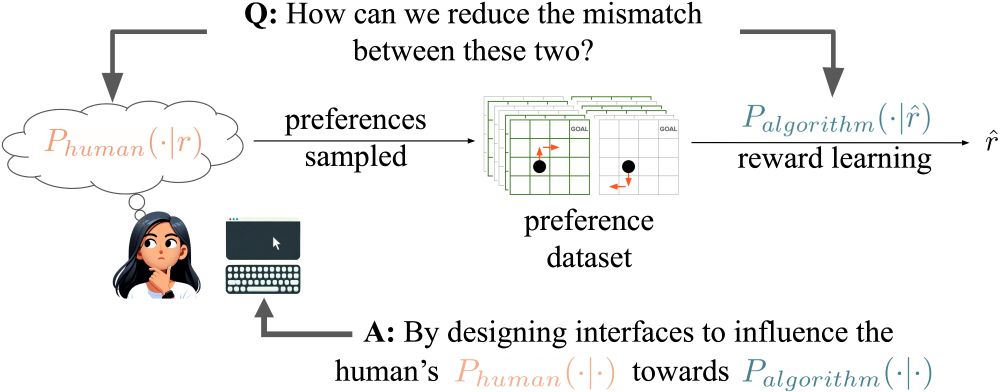
RLHF algorithms assume humans generate preferences according to normative models. We propose a new method for model alignment: influence humans to conform to these assumptions through interface design. Good news: it works!
#AI #MachineLearning #RLHF #Alignment (1/n)
#AI #MachineLearning #RLHF #Alignment (1/n)

January 14, 2025 at 11:51 PM
RLHF algorithms assume humans generate preferences according to normative models. We propose a new method for model alignment: influence humans to conform to these assumptions through interface design. Good news: it works!
#AI #MachineLearning #RLHF #Alignment (1/n)
#AI #MachineLearning #RLHF #Alignment (1/n)