



Alexander Hoyle
@alexanderhoyle.bsky.social
Postdoctoral fellow at ETH AI Center, working on Computational Social Science + NLP. Previously a PhD in CS at UMD, advised by Philip Resnik. Internships at MSR, AI2. he/him.
On the job market this cycle!
alexanderhoyle.com
On the job market this cycle!
alexanderhoyle.com
Happy to be at #EMNLP2025! Please say hello and come see our lovely work

November 5, 2025 at 2:23 AM
Happy to be at #EMNLP2025! Please say hello and come see our lovely work
[corrected link]
LLMs are often used for text annotation in social science. In some cases, this involves placing text items on a scale: eg, 1 for liberal and 9 for conservative
There are a few ways to handle this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/abs/2509.03116
LLMs are often used for text annotation in social science. In some cases, this involves placing text items on a scale: eg, 1 for liberal and 9 for conservative
There are a few ways to handle this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/abs/2509.03116

October 28, 2025 at 6:23 AM
[corrected link]
LLMs are often used for text annotation in social science. In some cases, this involves placing text items on a scale: eg, 1 for liberal and 9 for conservative
There are a few ways to handle this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/abs/2509.03116
LLMs are often used for text annotation in social science. In some cases, this involves placing text items on a scale: eg, 1 for liberal and 9 for conservative
There are a few ways to handle this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/abs/2509.03116
LLMs are often used for text annotation, especially in social science. In some cases, this involves placing text items on a scale: eg, 1 for liberal and 9 for conservative
There are a few ways to accomplish this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/pdf/2507.00828
There are a few ways to accomplish this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/pdf/2507.00828

October 27, 2025 at 2:59 PM
LLMs are often used for text annotation, especially in social science. In some cases, this involves placing text items on a scale: eg, 1 for liberal and 9 for conservative
There are a few ways to accomplish this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/pdf/2507.00828
There are a few ways to accomplish this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/pdf/2507.00828
Reposted by Alexander Hoyle

Computer Science is no longer just about building systems or proving theorems--it's about observation and experiments.
In my latest blog post, I argue it’s time we had our own "Econometrics," a discipline devoted to empirical rigor.
doomscrollingbabel.manoel.xyz/p/the-missin...
In my latest blog post, I argue it’s time we had our own "Econometrics," a discipline devoted to empirical rigor.
doomscrollingbabel.manoel.xyz/p/the-missin...

October 5, 2025 at 4:07 PM
Computer Science is no longer just about building systems or proving theorems--it's about observation and experiments.
In my latest blog post, I argue it’s time we had our own "Econometrics," a discipline devoted to empirical rigor.
doomscrollingbabel.manoel.xyz/p/the-missin...
In my latest blog post, I argue it’s time we had our own "Econometrics," a discipline devoted to empirical rigor.
doomscrollingbabel.manoel.xyz/p/the-missin...
Accepted to EMNLP (and more to come 👀)! The camera ready version is now online---very happy with how this turned out
arxiv.org/abs/2507.01234
arxiv.org/abs/2507.01234
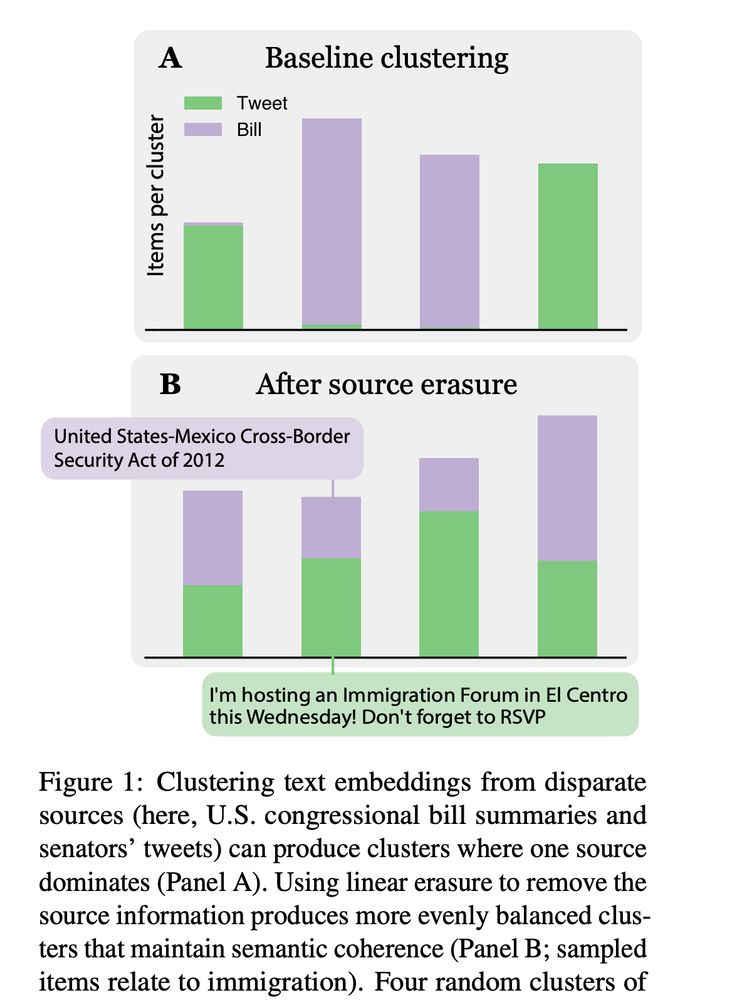
New preprint! Have you ever tried to cluster text embeddings from different sources, but the clusters just reproduce the sources? Or attempted to retrieve similar documents across multiple languages, and even multilingual embeddings return items in the same language?
Turns out there's an easy fix🧵
Turns out there's an easy fix🧵
September 24, 2025 at 3:21 PM
Accepted to EMNLP (and more to come 👀)! The camera ready version is now online---very happy with how this turned out
arxiv.org/abs/2507.01234
arxiv.org/abs/2507.01234
this looks terrific, very excited to read

LLMs introduce a huge range of new capabilities for research, but also make it possible for researchers to "hack" their results in new ways by how they chose to use models for annotation
This is a useful pass at quantifying some of the risk, and some mitigation strategies arxiv.org/pdf/2509.08825
This is a useful pass at quantifying some of the risk, and some mitigation strategies arxiv.org/pdf/2509.08825


September 15, 2025 at 7:53 PM
this looks terrific, very excited to read
Reposted by Alexander Hoyle

I am delighted to share our new #PNAS paper, with @grvkamath.bsky.social @msonderegger.bsky.social and @sivareddyg.bsky.social, on whether age matters for the adoption of new meanings. That is, as words change meaning, does the rate of adoption vary across generations? www.pnas.org/doi/epdf/10....

July 29, 2025 at 12:31 PM
I am delighted to share our new #PNAS paper, with @grvkamath.bsky.social @msonderegger.bsky.social and @sivareddyg.bsky.social, on whether age matters for the adoption of new meanings. That is, as words change meaning, does the rate of adoption vary across generations? www.pnas.org/doi/epdf/10....
At #ACL2025 this week! Please reach out if you want to chat :)
We have two lovely posters:
Tues Session 2, 10:30-11:50 — Large Language Models Struggle to Describe the Haystack without Human Help
Wed Session 4 11:00-12:30 — ProxAnn: Use-Oriented Evaluations of Topic Models and Document Clustering
We have two lovely posters:
Tues Session 2, 10:30-11:50 — Large Language Models Struggle to Describe the Haystack without Human Help
Wed Session 4 11:00-12:30 — ProxAnn: Use-Oriented Evaluations of Topic Models and Document Clustering
Evaluating topic models (and document clustering methods) is hard. In fact, since our paper critiquing standard evaluation practices four years ago, there hasn't been a good replacement metric
That ends today (we hope)! Our new ACL paper introduces an LLM-based evaluation protocol 🧵
That ends today (we hope)! Our new ACL paper introduces an LLM-based evaluation protocol 🧵

July 27, 2025 at 9:30 AM
At #ACL2025 this week! Please reach out if you want to chat :)
We have two lovely posters:
Tues Session 2, 10:30-11:50 — Large Language Models Struggle to Describe the Haystack without Human Help
Wed Session 4 11:00-12:30 — ProxAnn: Use-Oriented Evaluations of Topic Models and Document Clustering
We have two lovely posters:
Tues Session 2, 10:30-11:50 — Large Language Models Struggle to Describe the Haystack without Human Help
Wed Session 4 11:00-12:30 — ProxAnn: Use-Oriented Evaluations of Topic Models and Document Clustering
Reposted by Alexander Hoyle

🗣️ Excited to share our new #ACL2025 Findings paper: “Just Put a Human in the Loop? Investigating LLM-Assisted Annotation for Subjective Tasks” with Jad Kabbara and Deb Roy. Arxiv: arxiv.org/abs/2507.15821
Read about our findings ⤵️
Read about our findings ⤵️

Just Put a Human in the Loop? Investigating LLM-Assisted Annotation for Subjective Tasks
LLM use in annotation is becoming widespread, and given LLMs' overall promising performance and speed, simply "reviewing" LLM annotations in interpretive tasks can be tempting. In subjective annotatio...
arxiv.org
July 22, 2025 at 8:32 AM
🗣️ Excited to share our new #ACL2025 Findings paper: “Just Put a Human in the Loop? Investigating LLM-Assisted Annotation for Subjective Tasks” with Jad Kabbara and Deb Roy. Arxiv: arxiv.org/abs/2507.15821
Read about our findings ⤵️
Read about our findings ⤵️
Reposted by Alexander Hoyle

The precursor to this paper "The Incoherence of Coherence" had our most-watched paper video ever, so I thought we had to surpass it somehow ... so we decided to do a song parody (of Roxanne, obviously):
youtu.be/87OBxEM8a9E
youtu.be/87OBxEM8a9E
July 18, 2025 at 6:37 PM
The precursor to this paper "The Incoherence of Coherence" had our most-watched paper video ever, so I thought we had to surpass it somehow ... so we decided to do a song parody (of Roxanne, obviously):
youtu.be/87OBxEM8a9E
youtu.be/87OBxEM8a9E
New preprint! Have you ever tried to cluster text embeddings from different sources, but the clusters just reproduce the sources? Or attempted to retrieve similar documents across multiple languages, and even multilingual embeddings return items in the same language?
Turns out there's an easy fix🧵
Turns out there's an easy fix🧵
July 17, 2025 at 10:53 AM
New preprint! Have you ever tried to cluster text embeddings from different sources, but the clusters just reproduce the sources? Or attempted to retrieve similar documents across multiple languages, and even multilingual embeddings return items in the same language?
Turns out there's an easy fix🧵
Turns out there's an easy fix🧵
Evaluating topic models (and document clustering methods) is hard. In fact, since our paper critiquing standard evaluation practices four years ago, there hasn't been a good replacement metric
That ends today (we hope)! Our new ACL paper introduces an LLM-based evaluation protocol 🧵
That ends today (we hope)! Our new ACL paper introduces an LLM-based evaluation protocol 🧵
July 8, 2025 at 12:40 PM
Evaluating topic models (and document clustering methods) is hard. In fact, since our paper critiquing standard evaluation practices four years ago, there hasn't been a good replacement metric
That ends today (we hope)! Our new ACL paper introduces an LLM-based evaluation protocol 🧵
That ends today (we hope)! Our new ACL paper introduces an LLM-based evaluation protocol 🧵
Michael Roth's recent outspokenness has made me proud to be a Wes alum. A decade of NYT op-ed handwringing about "free speech" on campuses has only provided ammunition for bad faith attacks on academia
(Perhaps I should be better at responding to those fundraising emails)
(Perhaps I should be better at responding to those fundraising emails)


June 26, 2025 at 2:09 PM
Michael Roth's recent outspokenness has made me proud to be a Wes alum. A decade of NYT op-ed handwringing about "free speech" on campuses has only provided ammunition for bad faith attacks on academia
(Perhaps I should be better at responding to those fundraising emails)
(Perhaps I should be better at responding to those fundraising emails)
I for one am grateful for the opportunity to meditate on the meaning of “scientific artifact” at 2:15am

Do folks really find the ARR checklist valuable enough to justify that a paper submission takes this much effort?
May 20, 2025 at 1:08 PM
I for one am grateful for the opportunity to meditate on the meaning of “scientific artifact” at 2:15am
They added multi-file search!

May 11, 2025 at 9:55 PM
They added multi-file search!
Heartbreaking and evil. International students have always been treated like an indentured underclass, but we’ve moved from byzantine indifference to deliberate terrorizing. Unforgivable
Are there mutual aid networks for international students? What can we as citizens do here?
Are there mutual aid networks for international students? What can we as citizens do here?

A dozen Johns Hopkins students have had their visas revoked, for unspecified reasons. This confirms rumors swirling around campus yesterday. www.thebaltimorebanner.com/education/hi...

April 8, 2025 at 8:48 PM
Heartbreaking and evil. International students have always been treated like an indentured underclass, but we’ve moved from byzantine indifference to deliberate terrorizing. Unforgivable
Are there mutual aid networks for international students? What can we as citizens do here?
Are there mutual aid networks for international students? What can we as citizens do here?
this holiday season I am thankful that, rather than fixing the literally decade-old problem of multi-file search, Overleaf instead implemented the world's worst writing assistance tool


December 12, 2024 at 10:37 AM
this holiday season I am thankful that, rather than fixing the literally decade-old problem of multi-file search, Overleaf instead implemented the world's worst writing assistance tool
BERTopic users: how do you retrieve the documents most associated with a given topic? I can see some possible options from the documentation, but I'm most interested in standard practice
(NB: please don't take this question as a tacit endorsement of BERTopic, I'm just trying to evaluate it fairly)
(NB: please don't take this question as a tacit endorsement of BERTopic, I'm just trying to evaluate it fairly)
December 4, 2024 at 12:44 PM
BERTopic users: how do you retrieve the documents most associated with a given topic? I can see some possible options from the documentation, but I'm most interested in standard practice
(NB: please don't take this question as a tacit endorsement of BERTopic, I'm just trying to evaluate it fairly)
(NB: please don't take this question as a tacit endorsement of BERTopic, I'm just trying to evaluate it fairly)
Maria has been a consistent source of excellent insight, advice, and research since I’ve known her—you should apply!
(And now the bluesky is taking off you will be connected to NLP’s #1 influencer ! )
(And now the bluesky is taking off you will be connected to NLP’s #1 influencer ! )

I'm recruiting 1-2 PhD students to work with me at the University of Colorado Boulder! Looking for creative students with interests in #NLP and #CulturalAnalytics.
Boulder is a lovely college town 30 minutes from Denver and 1 hour from Rocky Mountain National Park 😎
Apply by December 15th!
Boulder is a lovely college town 30 minutes from Denver and 1 hour from Rocky Mountain National Park 😎
Apply by December 15th!

November 19, 2024 at 2:37 PM
Maria has been a consistent source of excellent insight, advice, and research since I’ve known her—you should apply!
(And now the bluesky is taking off you will be connected to NLP’s #1 influencer ! )
(And now the bluesky is taking off you will be connected to NLP’s #1 influencer ! )
Once again thinking about this description of a George Wallace campaign rally (from Gary Wills’ “Nixon Agonistes”)
![“He’ll have to go the whole way to satisfy this audience. “Ah hadn’ meant to say this tonight, but yew-know, if one of those hippies lays down in front of mah car when Ah become President …” They drown out the punch line in happy fulfilled anger. Refrain of some favorite song, it is too longed-for to be audible when it comes.
Their happiness is enough to break the heart. They vomit laughter. Trying to eject the vacuum inside them. They are not hungry or underprivileged or deprived in material ways. Each has, in some minor way, “made it.” And it all means nothing. Washington does not care. The children do not care. They have worked, and for what? As I looked through the crowd—the very young, and then a jump to middle age, no college students there but the protesting peaceniks—I wondered if the young mother from the street corner was there (someone watching her bright smear of baby), the one who screamed at the marching priests. Had the policeman come, the one who said last night that he did not back off in fourteen years? Had he turned in his resignation that day?—the[…]”
Excerpt From
Nixon Agonistes
Garry Wills](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:hqplaidpke4v5anbvw2vehxf/bafkreih663dhrs5qowcb4pavclkh3hsfz2l6ayraquntomiwue225wqp24@jpeg)
November 7, 2024 at 5:36 PM
Once again thinking about this description of a George Wallace campaign rally (from Gary Wills’ “Nixon Agonistes”)
Reposted by Alexander Hoyle

if a computer told you how fucking stupid this is would you believe it
twitter.com/emollick/sta...
twitter.com/emollick/sta...

April 21, 2024 at 2:03 AM
if a computer told you how fucking stupid this is would you believe it
twitter.com/emollick/sta...
twitter.com/emollick/sta...
What is in the water in Amsterdam?? For my dissertation I've been reading these excellent critical papers on measurement and validation and so many authors have a connection to UvA
pubmed.ncbi.nlm.nih.gov/15482073/
www.tandfonline.com/doi/epdf/10....
www.tandfonline.com/doi/full/10....
pubmed.ncbi.nlm.nih.gov/15482073/
www.tandfonline.com/doi/epdf/10....
www.tandfonline.com/doi/full/10....

I am super excited to share that our paper "Undesirable Biases in NLP: Addressing Challenges of Measurement" has been published in JAIR!
doi.org/10.1613/jair...
doi.org/10.1613/jair...
Undesirable Biases in NLP: Addressing Challenges of Measurement
| Journal of Artificial In...
doi.org
January 29, 2024 at 5:21 PM
What is in the water in Amsterdam?? For my dissertation I've been reading these excellent critical papers on measurement and validation and so many authors have a connection to UvA
pubmed.ncbi.nlm.nih.gov/15482073/
www.tandfonline.com/doi/epdf/10....
www.tandfonline.com/doi/full/10....
pubmed.ncbi.nlm.nih.gov/15482073/
www.tandfonline.com/doi/epdf/10....
www.tandfonline.com/doi/full/10....
Reposted by Alexander Hoyle

The #DataSittersClub is back with an all-new book on topic modeling! If the LDA buffet explainer didn't do it for you, give this one a try: thanks to Xanda Schofield and her student Sathvika Anand, I now feel like I actually understand how it works. datasittersclub.github.io/site/dsc20.h...

November 30, 2023 at 3:30 PM
The #DataSittersClub is back with an all-new book on topic modeling! If the LDA buffet explainer didn't do it for you, give this one a try: thanks to Xanda Schofield and her student Sathvika Anand, I now feel like I actually understand how it works. datasittersclub.github.io/site/dsc20.h...
Reposted by Alexander Hoyle

Dominik @dominsta.bsky.social talks about how to evaluate topic models, particularly with LLMs. 📄🧾📑🗞️📰📜
Joint work with Alexander @alexanderhoyle.bsky.social, Mrinmaya Sachan, and Elliott @elliottash.bsky.social.
www.youtube.com/watch?v=qIDj...
Joint work with Alexander @alexanderhoyle.bsky.social, Mrinmaya Sachan, and Elliott @elliottash.bsky.social.
www.youtube.com/watch?v=qIDj...
- YouTube
Enjoy the videos and music you love, upload original content, and share it all with friends, family, and the world on YouTube.
www.youtube.com
November 9, 2023 at 2:49 PM
Dominik @dominsta.bsky.social talks about how to evaluate topic models, particularly with LLMs. 📄🧾📑🗞️📰📜
Joint work with Alexander @alexanderhoyle.bsky.social, Mrinmaya Sachan, and Elliott @elliottash.bsky.social.
www.youtube.com/watch?v=qIDj...
Joint work with Alexander @alexanderhoyle.bsky.social, Mrinmaya Sachan, and Elliott @elliottash.bsky.social.
www.youtube.com/watch?v=qIDj...
Reposted by Alexander Hoyle

Honored my paper was accepted to Findings of #EMNLP2023! Many psycholinguistics studies use LLMs to estimate the probability of words in context. But LLMs process statistically derived subword tokens, while human processing doesn't. Does this matter? (w/Philip Resnik) 🧵
arxiv.org/abs/2310.17774
arxiv.org/abs/2310.17774

November 2, 2023 at 10:20 PM
Honored my paper was accepted to Findings of #EMNLP2023! Many psycholinguistics studies use LLMs to estimate the probability of words in context. But LLMs process statistically derived subword tokens, while human processing doesn't. Does this matter? (w/Philip Resnik) 🧵
arxiv.org/abs/2310.17774
arxiv.org/abs/2310.17774