


Alexander Hoyle
@alexanderhoyle.bsky.social
Postdoctoral fellow at ETH AI Center, working on Computational Social Science + NLP. Previously a PhD in CS at UMD, advised by Philip Resnik. Internships at MSR, AI2. he/him.
On the job market this cycle!
alexanderhoyle.com
On the job market this cycle!
alexanderhoyle.com
Happy to be at #EMNLP2025! Please say hello and come see our lovely work

November 5, 2025 at 2:23 AM
Happy to be at #EMNLP2025! Please say hello and come see our lovely work
[corrected link]
LLMs are often used for text annotation in social science. In some cases, this involves placing text items on a scale: eg, 1 for liberal and 9 for conservative
There are a few ways to handle this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/abs/2509.03116
LLMs are often used for text annotation in social science. In some cases, this involves placing text items on a scale: eg, 1 for liberal and 9 for conservative
There are a few ways to handle this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/abs/2509.03116

October 28, 2025 at 6:23 AM
[corrected link]
LLMs are often used for text annotation in social science. In some cases, this involves placing text items on a scale: eg, 1 for liberal and 9 for conservative
There are a few ways to handle this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/abs/2509.03116
LLMs are often used for text annotation in social science. In some cases, this involves placing text items on a scale: eg, 1 for liberal and 9 for conservative
There are a few ways to handle this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/abs/2509.03116
Two takeaways:
- Directly prompting on a scale is surprisingly fine, but *only if* you take the token-probability weighted average over scale items, Σ⁹ₙ₌₁ int(n) ⋅ p(n|x) (cf @victorwang37.bsky.social)
- Finetuning w/ a smaller model can do really well! And with as few as 1,000 paired annotations
- Directly prompting on a scale is surprisingly fine, but *only if* you take the token-probability weighted average over scale items, Σ⁹ₙ₌₁ int(n) ⋅ p(n|x) (cf @victorwang37.bsky.social)
- Finetuning w/ a smaller model can do really well! And with as few as 1,000 paired annotations

October 27, 2025 at 2:59 PM
Two takeaways:
- Directly prompting on a scale is surprisingly fine, but *only if* you take the token-probability weighted average over scale items, Σ⁹ₙ₌₁ int(n) ⋅ p(n|x) (cf @victorwang37.bsky.social)
- Finetuning w/ a smaller model can do really well! And with as few as 1,000 paired annotations
- Directly prompting on a scale is surprisingly fine, but *only if* you take the token-probability weighted average over scale items, Σ⁹ₙ₌₁ int(n) ⋅ p(n|x) (cf @victorwang37.bsky.social)
- Finetuning w/ a smaller model can do really well! And with as few as 1,000 paired annotations
This collaboration began because some of us thought the more principled approach is to instead compare pairs of items, then induce a score with Bradley-Terry
After all, it is easier for *people* to compare items relatively than to score them directly
After all, it is easier for *people* to compare items relatively than to score them directly
![Alt text for Figure 4 (from Measuring Scalar Constructs in Social Science with LLMs):
A visual example of a pairwise comparison task used to measure Ad-Negativity.
The figure shows two light-blue boxes, each containing short excerpts from political campaign ads labeled Text 1 and Text 2.
Text 1 says: “[Announcer]: America was built on democratic principles. But, here's one simple question—What if your vote wasn't private….”
Text 2 says: “[Announcer]: They're at it again. Powerful interests with false attacks on Mark Udall. The facts: Mark Udall's voted to ….”
Below them, a dark-blue box poses the prompt:
“Which campaign ad is more negative towards the mentioned opposing candidates?”
This illustrates how human annotators or language models are asked to judge which of two texts better exemplifies a target construct such as negativity.
Copied figure caption (as printed):
Figure 4: Pairwise comparison places two text items relative to one another regarding a given construct.](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:hqplaidpke4v5anbvw2vehxf/bafkreialwq3fwec7tthosk5ddznzdggdtrlhpzcomve5il7noufkcrhxtm@jpeg)
October 27, 2025 at 2:59 PM
This collaboration began because some of us thought the more principled approach is to instead compare pairs of items, then induce a score with Bradley-Terry
After all, it is easier for *people* to compare items relatively than to score them directly
After all, it is easier for *people* to compare items relatively than to score them directly
The naive approach is to "just ask": instruct the LLM the output a score on the provided scale
However, this does not work very well---LLM outputs tend to cluster or "heap" around certain integers (and do so inconsistently between models)
However, this does not work very well---LLM outputs tend to cluster or "heap" around certain integers (and do so inconsistently between models)

October 27, 2025 at 2:59 PM
The naive approach is to "just ask": instruct the LLM the output a score on the provided scale
However, this does not work very well---LLM outputs tend to cluster or "heap" around certain integers (and do so inconsistently between models)
However, this does not work very well---LLM outputs tend to cluster or "heap" around certain integers (and do so inconsistently between models)
LLMs are often used for text annotation, especially in social science. In some cases, this involves placing text items on a scale: eg, 1 for liberal and 9 for conservative
There are a few ways to accomplish this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/pdf/2507.00828
There are a few ways to accomplish this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/pdf/2507.00828

October 27, 2025 at 2:59 PM
LLMs are often used for text annotation, especially in social science. In some cases, this involves placing text items on a scale: eg, 1 for liberal and 9 for conservative
There are a few ways to accomplish this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/pdf/2507.00828
There are a few ways to accomplish this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/pdf/2507.00828
a friend bought these a size too large and I love them . Can wear to work or (as I just did) on a long haul flight

August 15, 2025 at 3:55 AM
a friend bought these a size too large and I love them . Can wear to work or (as I just did) on a long haul flight
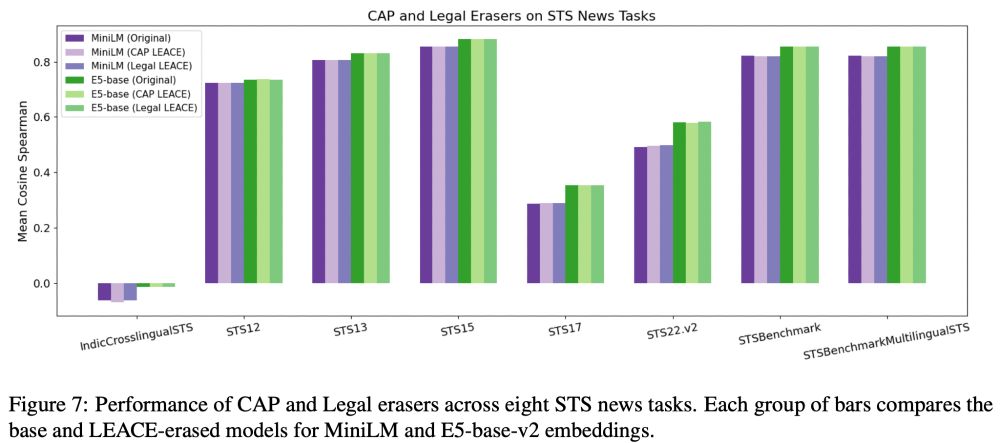
Despite the better metrics, we thought that erasure might degrade embeddings in ways we weren't measuring.
We applied LEACE models trained on our target datasets to out-of-domain embeddings from MTEB data. Surprisingly, MTEB metrics did not change!
We applied LEACE models trained on our target datasets to out-of-domain embeddings from MTEB data. Surprisingly, MTEB metrics did not change!
July 17, 2025 at 10:53 AM
Despite the better metrics, we thought that erasure might degrade embeddings in ways we weren't measuring.
We applied LEACE models trained on our target datasets to out-of-domain embeddings from MTEB data. Surprisingly, MTEB metrics did not change!
We applied LEACE models trained on our target datasets to out-of-domain embeddings from MTEB data. Surprisingly, MTEB metrics did not change!
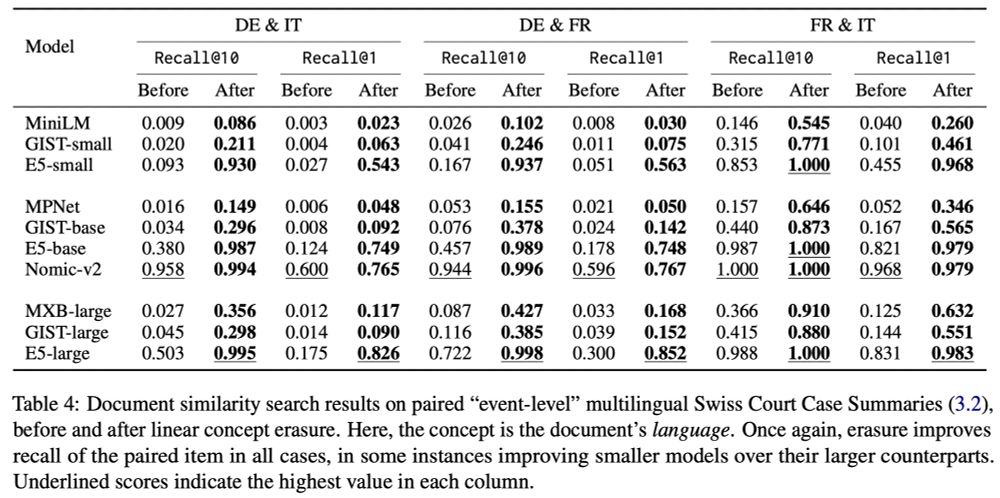
Applying linear erasure to remove source/language information from text embeddings (say, from sentence transformers) produces dramatic improvements on document similarty & clustering tasks
We use LEACE (@norabelrose.bsky.social et al. 2023), which is also cheap to run (seconds on a laptop)
We use LEACE (@norabelrose.bsky.social et al. 2023), which is also cheap to run (seconds on a laptop)
July 17, 2025 at 10:53 AM
Applying linear erasure to remove source/language information from text embeddings (say, from sentence transformers) produces dramatic improvements on document similarty & clustering tasks
We use LEACE (@norabelrose.bsky.social et al. 2023), which is also cheap to run (seconds on a laptop)
We use LEACE (@norabelrose.bsky.social et al. 2023), which is also cheap to run (seconds on a laptop)
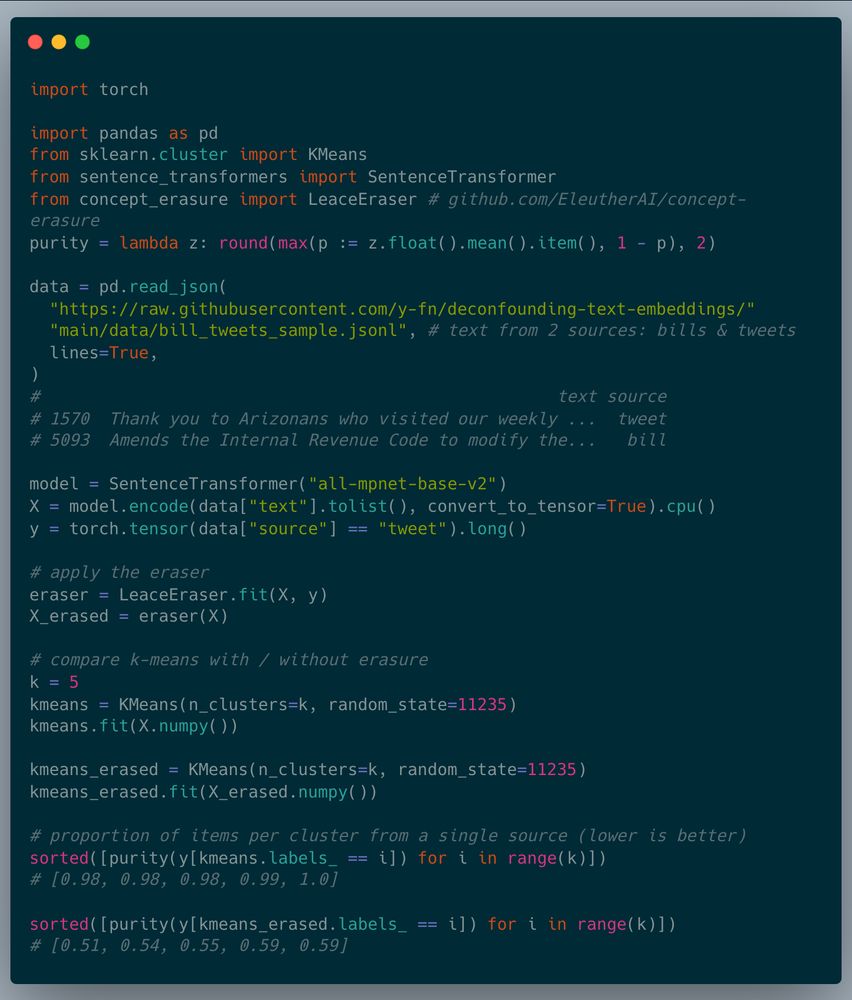
Attributes like language/source are confounders that distort distance-based applications
Debiasing methods remove unwanted information from embeddings—linear concept erasure in particular makes it so a linear predictor cannot recover a concept (eg, lang) from the representation
Debiasing methods remove unwanted information from embeddings—linear concept erasure in particular makes it so a linear predictor cannot recover a concept (eg, lang) from the representation
July 17, 2025 at 10:53 AM
Attributes like language/source are confounders that distort distance-based applications
Debiasing methods remove unwanted information from embeddings—linear concept erasure in particular makes it so a linear predictor cannot recover a concept (eg, lang) from the representation
Debiasing methods remove unwanted information from embeddings—linear concept erasure in particular makes it so a linear predictor cannot recover a concept (eg, lang) from the representation
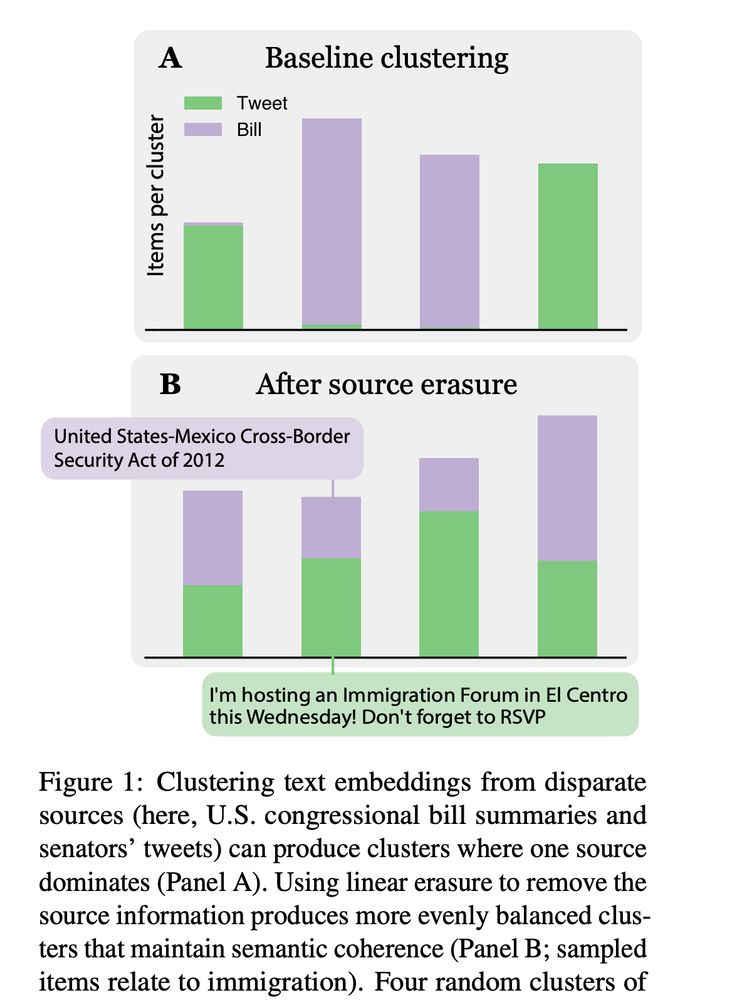
New preprint! Have you ever tried to cluster text embeddings from different sources, but the clusters just reproduce the sources? Or attempted to retrieve similar documents across multiple languages, and even multilingual embeddings return items in the same language?
Turns out there's an easy fix🧵
Turns out there's an easy fix🧵
July 17, 2025 at 10:53 AM
New preprint! Have you ever tried to cluster text embeddings from different sources, but the clusters just reproduce the sources? Or attempted to retrieve similar documents across multiple languages, and even multilingual embeddings return items in the same language?
Turns out there's an easy fix🧵
Turns out there's an easy fix🧵
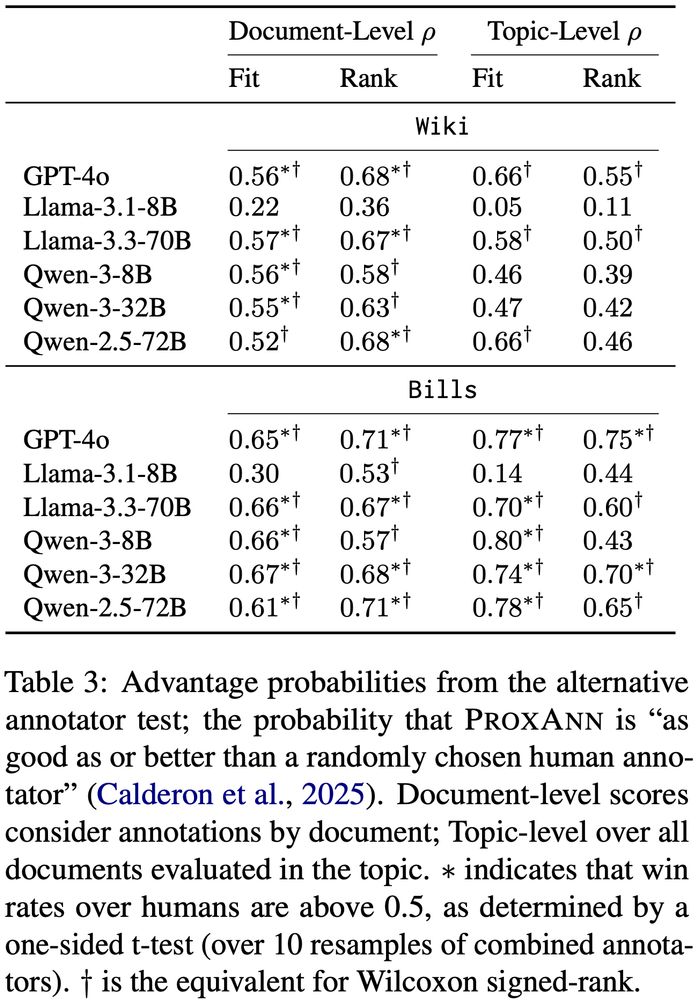
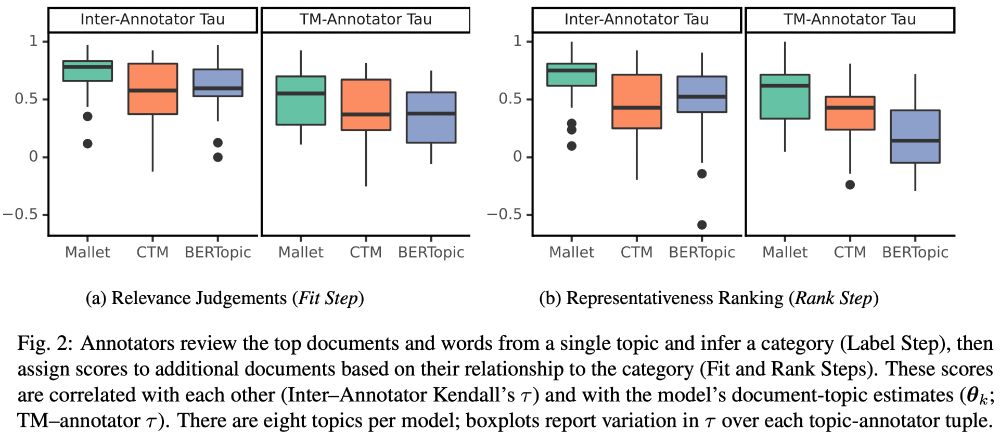
The protocol is also easily adapted to LLM judges: We call ours ProxAnn. While LLMs aren't perfect substitutes, they are about as good as an arbitrary human annotator
July 8, 2025 at 12:40 PM
The protocol is also easily adapted to LLM judges: We call ours ProxAnn. While LLMs aren't perfect substitutes, they are about as good as an arbitrary human annotator
Models are then evaluated by measuring whether annotations agree with model outputs: that is, do annotator scores correlate with document-topic probabilities (or distance to centroid)?
A human study finds that, in line with other work, classic LDA (Mallet) continues to work well
A human study finds that, in line with other work, classic LDA (Mallet) continues to work well
July 8, 2025 at 12:40 PM
Models are then evaluated by measuring whether annotations agree with model outputs: that is, do annotator scores correlate with document-topic probabilities (or distance to centroid)?
A human study finds that, in line with other work, classic LDA (Mallet) continues to work well
A human study finds that, in line with other work, classic LDA (Mallet) continues to work well
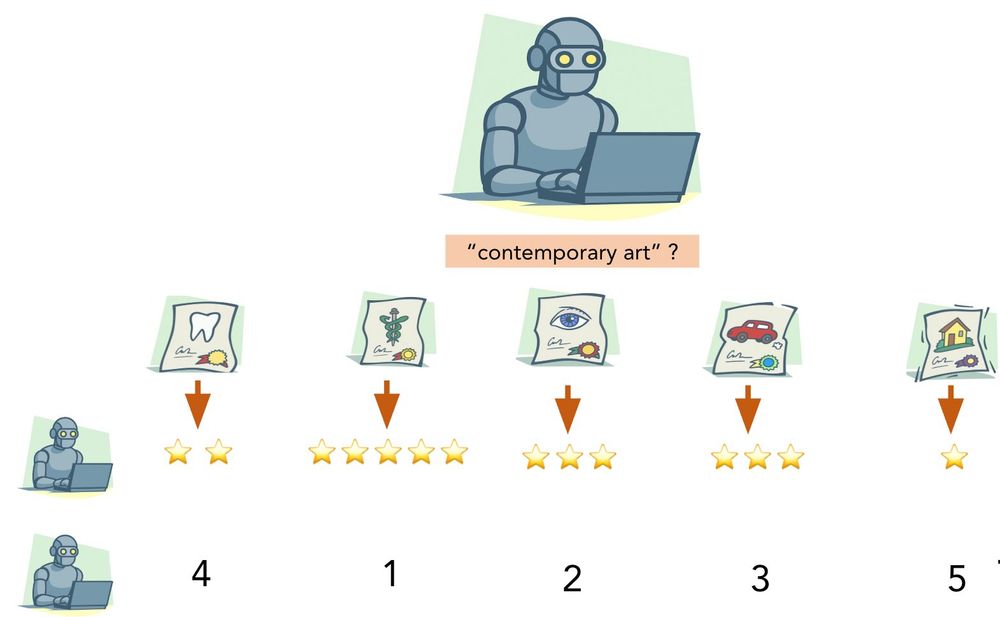
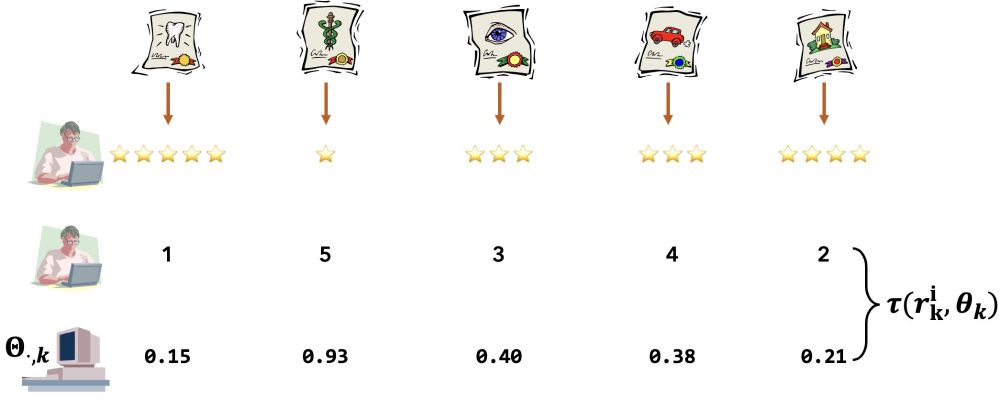
The setup approximates real world qualitative content analysis. An annotator
1. Reviews a small collection of documents (& top words) for a topic, and writes down a category label
2. Determines whether new documents fit that label
3. Ranks the documents by relevance to the label
1. Reviews a small collection of documents (& top words) for a topic, and writes down a category label
2. Determines whether new documents fit that label
3. Ranks the documents by relevance to the label
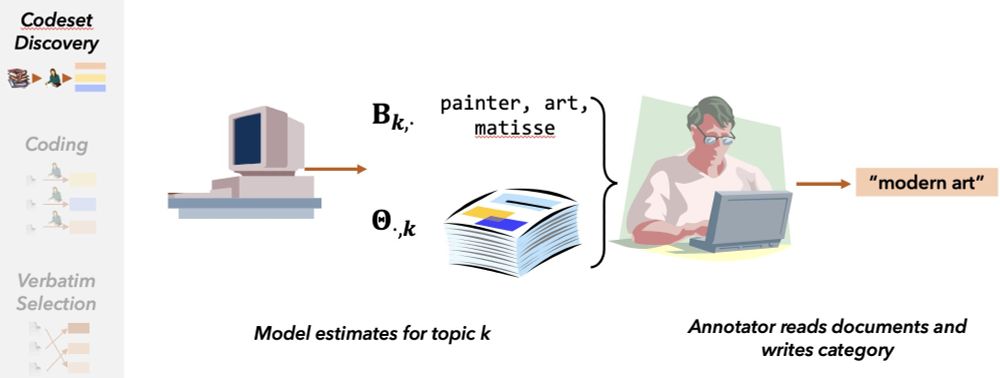

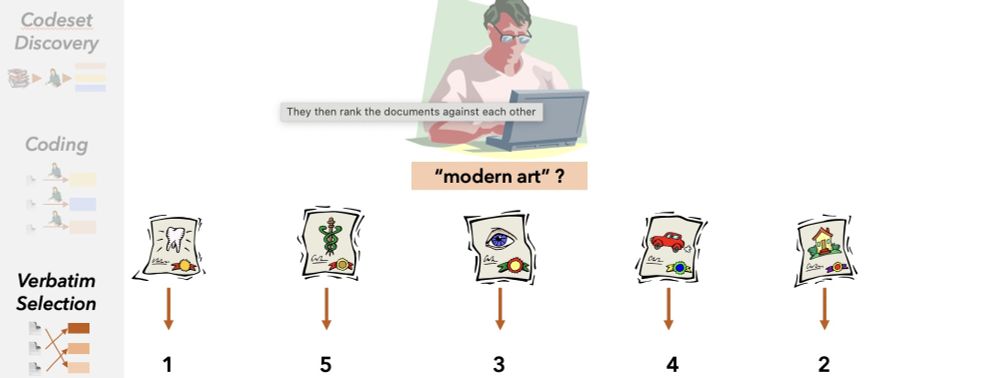
July 8, 2025 at 12:40 PM
The setup approximates real world qualitative content analysis. An annotator
1. Reviews a small collection of documents (& top words) for a topic, and writes down a category label
2. Determines whether new documents fit that label
3. Ranks the documents by relevance to the label
1. Reviews a small collection of documents (& top words) for a topic, and writes down a category label
2. Determines whether new documents fit that label
3. Ranks the documents by relevance to the label
In addition, standard evaluations don't really correspond to any real-world use case, and also don't align well with human judgments of topic coherence (per our previous work)
In this paper, we design a new evaluation protocol and LLM-as-judge proxy, ProxAnn
In this paper, we design a new evaluation protocol and LLM-as-judge proxy, ProxAnn

July 8, 2025 at 12:40 PM
In addition, standard evaluations don't really correspond to any real-world use case, and also don't align well with human judgments of topic coherence (per our previous work)
In this paper, we design a new evaluation protocol and LLM-as-judge proxy, ProxAnn
In this paper, we design a new evaluation protocol and LLM-as-judge proxy, ProxAnn
How do standard metrics work? Automated coherence computes how often the top n words in a topic appear together in some reference text (eg, Wikipedia)
This fails to consider which *documents* are associated with each topic, and so doesn't transfer well to text clustering methods
This fails to consider which *documents* are associated with each topic, and so doesn't transfer well to text clustering methods

July 8, 2025 at 12:40 PM
How do standard metrics work? Automated coherence computes how often the top n words in a topic appear together in some reference text (eg, Wikipedia)
This fails to consider which *documents* are associated with each topic, and so doesn't transfer well to text clustering methods
This fails to consider which *documents* are associated with each topic, and so doesn't transfer well to text clustering methods
Evaluating topic models (and document clustering methods) is hard. In fact, since our paper critiquing standard evaluation practices four years ago, there hasn't been a good replacement metric
That ends today (we hope)! Our new ACL paper introduces an LLM-based evaluation protocol 🧵
That ends today (we hope)! Our new ACL paper introduces an LLM-based evaluation protocol 🧵

July 8, 2025 at 12:40 PM
Evaluating topic models (and document clustering methods) is hard. In fact, since our paper critiquing standard evaluation practices four years ago, there hasn't been a good replacement metric
That ends today (we hope)! Our new ACL paper introduces an LLM-based evaluation protocol 🧵
That ends today (we hope)! Our new ACL paper introduces an LLM-based evaluation protocol 🧵
They added multi-file search!

May 11, 2025 at 9:55 PM
They added multi-file search!
You'd think so, but no

March 20, 2025 at 10:18 PM
You'd think so, but no

this holiday season I am thankful that, rather than fixing the literally decade-old problem of multi-file search, Overleaf instead implemented the world's worst writing assistance tool


December 12, 2024 at 10:37 AM
this holiday season I am thankful that, rather than fixing the literally decade-old problem of multi-file search, Overleaf instead implemented the world's worst writing assistance tool
Once again thinking about this description of a George Wallace campaign rally (from Gary Wills’ “Nixon Agonistes”)
![“He’ll have to go the whole way to satisfy this audience. “Ah hadn’ meant to say this tonight, but yew-know, if one of those hippies lays down in front of mah car when Ah become President …” They drown out the punch line in happy fulfilled anger. Refrain of some favorite song, it is too longed-for to be audible when it comes.
Their happiness is enough to break the heart. They vomit laughter. Trying to eject the vacuum inside them. They are not hungry or underprivileged or deprived in material ways. Each has, in some minor way, “made it.” And it all means nothing. Washington does not care. The children do not care. They have worked, and for what? As I looked through the crowd—the very young, and then a jump to middle age, no college students there but the protesting peaceniks—I wondered if the young mother from the street corner was there (someone watching her bright smear of baby), the one who screamed at the marching priests. Had the policeman come, the one who said last night that he did not back off in fourteen years? Had he turned in his resignation that day?—the[…]”
Excerpt From
Nixon Agonistes
Garry Wills](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:hqplaidpke4v5anbvw2vehxf/bafkreih663dhrs5qowcb4pavclkh3hsfz2l6ayraquntomiwue225wqp24@jpeg)
November 7, 2024 at 5:36 PM
Once again thinking about this description of a George Wallace campaign rally (from Gary Wills’ “Nixon Agonistes”)
The recent New Yorker piece where he features heavily gave an interesting perspective
www.newyorker.com/magazine/202...
www.newyorker.com/magazine/202...

February 23, 2024 at 6:05 PM
The recent New Yorker piece where he features heavily gave an interesting perspective
www.newyorker.com/magazine/202...
www.newyorker.com/magazine/202...
the last time i had fried chicken in a bucket it was actually ice cream coated in corn flakes. fakery!!!

February 7, 2024 at 10:09 PM
the last time i had fried chicken in a bucket it was actually ice cream coated in corn flakes. fakery!!!
But as I mentioned in response to @tedunderwood.me on Twitter, the picture Krippendorf paints is a bit more nuanced---that it the variation in interpretation is desirable.
I suppose that the issue for me is that a wordlist is too information-sparse to ground a close reading on their own
I suppose that the issue for me is that a wordlist is too information-sparse to ground a close reading on their own

November 3, 2023 at 8:37 PM
But as I mentioned in response to @tedunderwood.me on Twitter, the picture Krippendorf paints is a bit more nuanced---that it the variation in interpretation is desirable.
I suppose that the issue for me is that a wordlist is too information-sparse to ground a close reading on their own
I suppose that the issue for me is that a wordlist is too information-sparse to ground a close reading on their own