



I took an initial look at using Large language models with @llamastack from the perspective of a #nodejs developer. Check it out here - developers.redhat.com/articles/202...

A practical guide to Llama Stack for Node.js developers | Red Hat Developer
Explore how to run tools with Node.js using Llama Stack's completions API, agent API, and support for in-line tools, local MCP tools, and remote MCP tools.
developers.redhat.com
April 2, 2025 at 1:56 PM
I took an initial look at using Large language models with @llamastack from the perspective of a #nodejs developer. Check it out here - developers.redhat.com/articles/202...

Introducing vLLM Inference Provider in Llama Stack
blog.vllm.ai/2025/01/27/i...
#artificialintelligence #AI #vLLM #llamastack #opensource #RedHat
blog.vllm.ai/2025/01/27/i...
#artificialintelligence #AI #vLLM #llamastack #opensource #RedHat
Introducing vLLM Inference Provider in Llama Stack
We are excited to announce that vLLM inference provider is now available in Llama Stack through the collaboration between the Red Hat AI Engineering team and the Llama Stack team from Meta. This artic...
blog.vllm.ai
February 4, 2025 at 5:09 PM
Introducing vLLM Inference Provider in Llama Stack
blog.vllm.ai/2025/01/27/i...
#artificialintelligence #AI #vLLM #llamastack #opensource #RedHat
blog.vllm.ai/2025/01/27/i...
#artificialintelligence #AI #vLLM #llamastack #opensource #RedHat
I have been looking at using @llamastack with #nodejs and JavaScript. In this blog post I cover what I learned about doing Retrieval Augmented Generation (RAG) with large language models and LLama stack - developers.redhat.com/articles/202...

Retrieval-augmented generation with Llama Stack and Node.js | Red Hat Developer
This tutorial shows you how to use the Llama Stack API to implement retrieval-augmented generation for an AI application built with Node.js
developers.redhat.com
April 30, 2025 at 2:31 PM
I have been looking at using @llamastack with #nodejs and JavaScript. In this blog post I cover what I learned about doing Retrieval Augmented Generation (RAG) with large language models and LLama stack - developers.redhat.com/articles/202...

As LLMs move into production, #Observability is essential for Reliability, Performance & Responsible AI.
Learn how to deploy an #opensource observability stack - using Prometheus, Grafana, Tempo, and more - and monitor real #AI workloads with #vLLM & #Llamastack.
🎥 #InfoQ video: bit.ly/4hn2dlo
Learn how to deploy an #opensource observability stack - using Prometheus, Grafana, Tempo, and more - and monitor real #AI workloads with #vLLM & #Llamastack.
🎥 #InfoQ video: bit.ly/4hn2dlo

Why Observability Matters (More!) with AI Applications
Sally O'Malley explains the unique observability challenges of LLMs and provides a reproducible, open-source stack for monitoring AI workloads. She demonstrates deploying Prometheus, Grafana, OpenTele...
bit.ly
October 24, 2025 at 5:55 AM
As LLMs move into production, #Observability is essential for Reliability, Performance & Responsible AI.
Learn how to deploy an #opensource observability stack - using Prometheus, Grafana, Tempo, and more - and monitor real #AI workloads with #vLLM & #Llamastack.
🎥 #InfoQ video: bit.ly/4hn2dlo
Learn how to deploy an #opensource observability stack - using Prometheus, Grafana, Tempo, and more - and monitor real #AI workloads with #vLLM & #Llamastack.
🎥 #InfoQ video: bit.ly/4hn2dlo

Introducing vLLM Inference Provider in Llama Stack
https://blog.vllm.ai/2025/01/27/intro-to-llama-stack-with-vllm.html
#artificialintelligence #ai #vllm #llamastack #opensource #redhat
https://blog.vllm.ai/2025/01/27/intro-to-llama-stack-with-vllm.html
#artificialintelligence #ai #vllm #llamastack #opensource #redhat
Introducing vLLM Inference Provider in Llama Stack
<p>We are excited to announce that vLLM inference provider is now available in <a href="https://github.com/meta-llama/llama-stack">Llama Stack</a> through the collaboration between the Red Hat AI Engineering team and the Llama Stack team from Meta. This article provides an introduction to this integration and a tutorial to help you get started using it locally or deploying it in a Kubernetes cluster.</p>
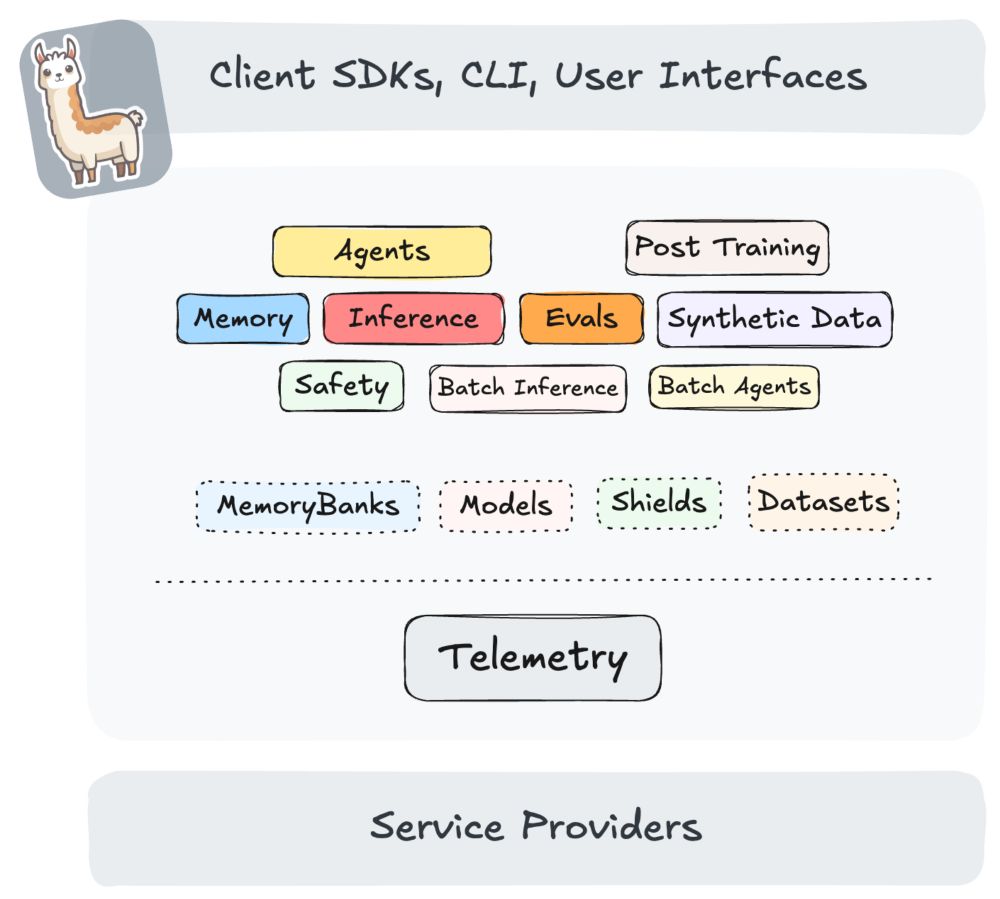
<h1 id="what-is-llama-stack">What is Llama Stack?</h1>
<p><img align="right" alt="llama-stack-diagram" height="50%" src="https://blog.vllm.ai/assets/figures/llama-stack/llama-stack.png" width="50%"/></p>
<p>Llama Stack defines and standardizes the set of core building blocks needed to bring generative AI applications to market. These building blocks are presented in the form of interoperable APIs with a broad set of Service Providers providing their implementations.</p>
<p>Llama Stack focuses on making it easy to build production applications with a variety of models - ranging from the latest Llama 3.3 model to specialized models like Llama Guard for safety and other models. The goal is to provide pre-packaged implementations (aka “distributions”) which can be run in a variety of deployment environments. The Stack can assist you in your entire app development lifecycle - start iterating on local, mobile or desktop and seamlessly transition to on-prem or public cloud deployments. At every point in this transition, the same set of APIs and the same developer experience are available.</p>
<p>Each specific implementation of an API is called a “Provider” in this architecture. Users can swap providers via configuration. vLLM is a prominent example of a high-performance API backing the inference API.</p>
<h1 id="vllm-inference-provider">vLLM Inference Provider</h1>
<p>Llama Stack provides two vLLM inference providers:</p>
<ol>
<li><a href="https://llama-stack.readthedocs.io/en/latest/distributions/self_hosted_distro/remote-vllm.html">Remote vLLM inference provider</a> through vLLM’s <a href="https://docs.vllm.ai/en/latest/getting_started/quickstart.html#openai-completions-api-with-vllm">OpenAI-compatible server</a>;</li>
<li><a href="https://github.com/meta-llama/llama-stack/tree/main/llama_stack/providers/inline/inference/vllm">Inline vLLM inference provider</a> that runs alongside with Llama Stack server.</li>
</ol>
<p>In this article, we will demonstrate the functionality through the remote vLLM inference provider.</p>
<h1 id="tutorial">Tutorial</h1>
<h2 id="prerequisites">Prerequisites</h2>
<ul>
<li>Linux operating system</li>
<li><a href="https://huggingface.co/docs/huggingface_hub/main/en/guides/cli">Hugging Face CLI</a> if you’d like to download the model via CLI.</li>
<li>OCI-compliant container technologies like <a href="https://podman.io/">Podman</a> or <a href="https://www.docker.com/">Docker</a> (can be specified via the <code class="language-plaintext highlighter-rouge">CONTAINER_BINARY</code> environment variable when running <code class="language-plaintext highlighter-rouge">llama stack</code> CLI commands).</li>
<li><a href="https://kind.sigs.k8s.io/">Kind</a> for Kubernetes deployment.</li>
<li><a href="https://github.com/conda/conda">Conda</a> for managing Python environment.</li>
</ul>
<h2 id="get-started-via-containers">Get Started via Containers</h2>
<h3 id="start-vllm-server">Start vLLM Server</h3>
<p>We first download the “Llama-3.2-1B-Instruct” model using the <a href="https://huggingface.co/docs/huggingface_hub/main/en/guides/cli">Hugging Face CLI</a>. Note that you’ll need to specify your Hugging Face token when logging in.</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="nb">mkdir</span> /tmp/test-vllm-llama-stack
huggingface-cli login <span class="nt">--token</span> <YOUR-HF-TOKEN>
huggingface-cli download meta-llama/Llama-3.2-1B-Instruct <span class="nt">--local-dir</span> /tmp/test-vllm-llama-stack/.cache/huggingface/hub/models/Llama-3.2-1B-Instruct
</code></pre></div></div>
<p>Next, let’s build the vLLM CPU container image from source. Note that while we use it for demonstration purposes, there are plenty of <a href="https://docs.vllm.ai/en/latest/getting_started/installation/index.html">other images available for different hardware and architectures</a>.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>git clone git@github.com:vllm-project/vllm.git /tmp/test-vllm-llama-stack
cd /tmp/test-vllm-llama-stack/vllm
podman build -f Dockerfile.cpu -t vllm-cpu-env --shm-size=4g .
</code></pre></div></div>
<p>We can then start the vLLM container:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>podman run <span class="nt">-it</span> <span class="nt">--network</span><span class="o">=</span>host <span class="se">\</span>
<span class="nt">--group-add</span><span class="o">=</span>video <span class="se">\</span>
<span class="nt">--ipc</span><span class="o">=</span>host <span class="se">\</span>
<span class="nt">--cap-add</span><span class="o">=</span>SYS_PTRACE <span class="se">\</span>
<span class="nt">--security-opt</span> <span class="nv">seccomp</span><span class="o">=</span>unconfined <span class="se">\</span>
<span class="nt">--device</span> /dev/kfd <span class="se">\</span>
<span class="nt">--device</span> /dev/dri <span class="se">\</span>
<span class="nt">-v</span> /tmp/test-vllm-llama-stack/.cache/huggingface/hub/models/Llama-3.2-1B-Instruct:/app/model <span class="se">\</span>
<span class="nt">--entrypoint</span><span class="o">=</span><span class="s1">'["python3", "-m", "vllm.entrypoints.openai.api_server", "--model", "/app/model", "--served-model-name", "meta-llama/Llama-3.2-1B-Instruct", "--port", "8000"]'</span> <span class="se">\</span>
vllm-cpu-env
</code></pre></div></div>
<p>We can get a list of models and test a prompt once the model server has started:</p>
<div class="language-bash highlighter-rouge"><div class="highlight"><pre class="highlight"><code>curl http://localhost:8000/v1/models
curl http://localhost:8000/v1/completions <span class="se">\</span>
<span class="nt">-H</span> <span class="s2">"Content-Type: application/json"</span> <span class="se">\</span>
<span class="nt">-d</span> <span class="s1">'{
"model": "meta-llama/Llama-3.2-1B-Instruct",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'</span>
</code></pre></div></div>
<h3 id="start-llama-stack-server">Start Llama Stack Server</h3>
<p>Once we verify that the vLLM server has started successfully and is able to serve requests, we can then build and start the Llama Stack server.</p>
<p>First, we clone the Llama Stack source code and create a Conda environment that includes all the dependencies:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>git clone git@github.com:meta-llama/llama-stack.git /tmp/test-vllm-llama-stack/llama-stack
cd /tmp/test-vllm-llama-stack/llama-stack
conda create -n stack python=3.10
conda activate stack
pip install .
</code></pre></div></div>
<p>Next, we build the container image with <code class="language-plaintext highlighter-rouge">llama stack build</code>:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat > /tmp/test-vllm-llama-stack/vllm-llama-stack-build.yaml << "EOF"
name: vllm
distribution_spec:
description: Like local, but use vLLM for running LLM inference
providers:
inference: remote::vllm
safety: inline::llama-guard
agents: inline::meta-reference
vector_io: inline::faiss
datasetio: inline::localfs
scoring: inline::basic
eval: inline::meta-reference
post_training: inline::torchtune
telemetry: inline::meta-reference
image_type: container
EOF
export CONTAINER_BINARY=podman
LLAMA_STACK_DIR=. PYTHONPATH=. python -m llama_stack.cli.llama stack build --config /tmp/test-vllm-llama-stack/vllm-llama-stack-build.yaml --image-name distribution-myenv
</code></pre></div></div>
<p>Once the container image has been built successfully, we can then edit the generated <code class="language-plaintext highlighter-rouge">vllm-run.yaml</code> to be <code class="language-plaintext highlighter-rouge">/tmp/test-vllm-llama-stack/vllm-llama-stack-run.yaml</code> with the following change in the <code class="language-plaintext highlighter-rouge">models</code> field:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>models:
- metadata: {}
model_id: ${env.INFERENCE_MODEL}
provider_id: vllm
provider_model_id: null
</code></pre></div></div>
<p>Then we can start the LlamaStack Server with the image we built via <code class="language-plaintext highlighter-rouge">llama stack run</code>:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>export INFERENCE_ADDR=host.containers.internal
export INFERENCE_PORT=8000
export INFERENCE_MODEL=meta-llama/Llama-3.2-1B-Instruct
export LLAMA_STACK_PORT=5000
LLAMA_STACK_DIR=. PYTHONPATH=. python -m llama_stack.cli.llama stack run \
--env INFERENCE_MODEL=$INFERENCE_MODEL \
--env VLLM_URL=http://$INFERENCE_ADDR:$INFERENCE_PORT/v1 \
--env VLLM_MAX_TOKENS=8192 \
--env VLLM_API_TOKEN=fake \
--env LLAMA_STACK_PORT=$LLAMA_STACK_PORT \
/tmp/test-vllm-llama-stack/vllm-llama-stack-run.yaml
</code></pre></div></div>
<p>Alternatively, we can run the following <code class="language-plaintext highlighter-rouge">podman run</code> command instead:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>podman run --security-opt label=disable -it --network host -v /tmp/test-vllm-llama-stack/vllm-llama-stack-run.yaml:/app/config.yaml -v /tmp/test-vllm-llama-stack/llama-stack:/app/llama-stack-source \
--env INFERENCE_MODEL=$INFERENCE_MODEL \
--env VLLM_URL=http://$INFERENCE_ADDR:$INFERENCE_PORT/v1 \
--env VLLM_MAX_TOKENS=8192 \
--env VLLM_API_TOKEN=fake \
--env LLAMA_STACK_PORT=$LLAMA_STACK_PORT \
--entrypoint='["python", "-m", "llama_stack.distribution.server.server", "--yaml-config", "/app/config.yaml"]' \
localhost/distribution-myenv:dev
</code></pre></div></div>
<p>Once we start the Llama Stack server successfully, we can then start testing a inference request:</p>
<p>Via Bash:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>llama-stack-client --endpoint http://localhost:5000 inference chat-completion --message "hello, what model are you?"
</code></pre></div></div>
<p>Output:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>ChatCompletionResponse(
completion_message=CompletionMessage(
content="Hello! I'm an AI, a conversational AI model. I'm a type of computer program designed to understand and respond to human language. My creators have
trained me on a vast amount of text data, allowing me to generate human-like responses to a wide range of questions and topics. I'm here to help answer any question you
may have, so feel free to ask me anything!",
role='assistant',
stop_reason='end_of_turn',
tool_calls=[]
),
logprobs=None
)
</code></pre></div></div>
<p>Via Python:</p>
<div class="language-python highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="kn">import</span> <span class="n">os</span>
<span class="kn">from</span> <span class="n">llama_stack_client</span> <span class="kn">import</span> <span class="n">LlamaStackClient</span>
<span class="n">client</span> <span class="o">=</span> <span class="nc">LlamaStackClient</span><span class="p">(</span><span class="n">base_url</span><span class="o">=</span><span class="sa">f</span><span class="sh">"</span><span class="s">http://localhost:</span><span class="si">{</span><span class="n">os</span><span class="p">.</span><span class="n">environ</span><span class="p">[</span><span class="sh">'</span><span class="s">LLAMA_STACK_PORT</span><span class="sh">'</span><span class="p">]</span><span class="si">}</span><span class="sh">"</span><span class="p">)</span>
<span class="c1"># List available models
</span><span class="n">models</span> <span class="o">=</span> <span class="n">client</span><span class="p">.</span><span class="n">models</span><span class="p">.</span><span class="nf">list</span><span class="p">()</span>
<span class="nf">print</span><span class="p">(</span><span class="n">models</span><span class="p">)</span>
<span class="n">response</span> <span class="o">=</span> <span class="n">client</span><span class="p">.</span><span class="n">inference</span><span class="p">.</span><span class="nf">chat_completion</span><span class="p">(</span>
<span class="n">model_id</span><span class="o">=</span><span class="n">os</span><span class="p">.</span><span class="n">environ</span><span class="p">[</span><span class="sh">"</span><span class="s">INFERENCE_MODEL</span><span class="sh">"</span><span class="p">],</span>
<span class="n">messages</span><span class="o">=</span><span class="p">[</span>
<span class="p">{</span><span class="sh">"</span><span class="s">role</span><span class="sh">"</span><span class="p">:</span> <span class="sh">"</span><span class="s">system</span><span class="sh">"</span><span class="p">,</span> <span class="sh">"</span><span class="s">content</span><span class="sh">"</span><span class="p">:</span> <span class="sh">"</span><span class="s">You are a helpful assistant.</span><span class="sh">"</span><span class="p">},</span>
<span class="p">{</span><span class="sh">"</span><span class="s">role</span><span class="sh">"</span><span class="p">:</span> <span class="sh">"</span><span class="s">user</span><span class="sh">"</span><span class="p">,</span> <span class="sh">"</span><span class="s">content</span><span class="sh">"</span><span class="p">:</span> <span class="sh">"</span><span class="s">Write a haiku about coding</span><span class="sh">"</span><span class="p">}</span>
<span class="p">]</span>
<span class="p">)</span>
<span class="nf">print</span><span class="p">(</span><span class="n">response</span><span class="p">.</span><span class="n">completion_message</span><span class="p">.</span><span class="n">content</span><span class="p">)</span>
</code></pre></div></div>
<p>Output:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>[Model(identifier='meta-llama/Llama-3.2-1B-Instruct', metadata={}, api_model_type='llm', provider_id='vllm', provider_resource_id='meta-llama/Llama-3.2-1B-Instruct', type='model', model_type='llm')]
Here is a haiku about coding:
Columns of code flow
Logic codes the endless night
Tech's silent dawn rise
</code></pre></div></div>
<h2 id="deployment-on-kubernetes">Deployment on Kubernetes</h2>
<p>Instead of starting the Llama Stack and vLLM servers locally. We can deploy them in a Kubernetes cluster. We’ll use a local Kind cluster for demonstration purposes:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kind create cluster --image kindest/node:v1.32.0 --name llama-stack-test
</code></pre></div></div>
<p>Start vLLM server as a Kubernetes Pod and Service (remember to replace <code class="language-plaintext highlighter-rouge"><YOUR-HF-TOKEN></code> with your actual token):</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat <<EOF |kubectl apply -f -
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vllm-models
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 50Gi
---
apiVersion: v1
kind: Secret
metadata:
name: hf-token-secret
type: Opaque
data:
token: "<YOUR-HF-TOKEN>"
---
apiVersion: v1
kind: Pod
metadata:
name: vllm-server
labels:
app: vllm
spec:
containers:
- name: llama-stack
image: localhost/vllm-cpu-env:latest
command:
- bash
- -c
- |
MODEL="meta-llama/Llama-3.2-1B-Instruct"
MODEL_PATH=/app/model/$(basename $MODEL)
huggingface-cli login --token $HUGGING_FACE_HUB_TOKEN
huggingface-cli download $MODEL --local-dir $MODEL_PATH --cache-dir $MODEL_PATH
python3 -m vllm.entrypoints.openai.api_server --model $MODEL_PATH --served-model-name $MODEL --port 8000
ports:
- containerPort: 8000
volumeMounts:
- name: llama-storage
mountPath: /app/model
env:
- name: HUGGING_FACE_HUB_TOKEN
valueFrom:
secretKeyRef:
name: hf-token-secret
key: token
volumes:
- name: llama-storage
persistentVolumeClaim:
claimName: vllm-models
---
apiVersion: v1
kind: Service
metadata:
name: vllm-server
spec:
selector:
app: vllm
ports:
- port: 8000
targetPort: 8000
type: NodePort
EOF
</code></pre></div></div>
<p>We can verify that the vLLM server has started successfully via the logs (this might take a couple of minutes to download the model):</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl logs vllm-server
...
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
</code></pre></div></div>
<p>Then we can modify the previously created <code class="language-plaintext highlighter-rouge">vllm-llama-stack-run.yaml</code> to <code class="language-plaintext highlighter-rouge">/tmp/test-vllm-llama-stack/vllm-llama-stack-run-k8s.yaml</code> with the following inference provider:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>providers:
inference:
- provider_id: vllm
provider_type: remote::vllm
config:
url: ${env.VLLM_URL}
max_tokens: ${env.VLLM_MAX_TOKENS:4096}
api_token: ${env.VLLM_API_TOKEN:fake}
</code></pre></div></div>
<p>Once we have defined the run configuration for Llama Stack, we can build an image with that configuration the server source code:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat >/tmp/test-vllm-llama-stack/Containerfile.llama-stack-run-k8s <<EOF
FROM distribution-myenv:dev
RUN apt-get update && apt-get install -y git
RUN git clone https://github.com/meta-llama/llama-stack.git /app/llama-stack-source
ADD ./vllm-llama-stack-run-k8s.yaml /app/config.yaml
EOF
podman build -f /tmp/test-vllm-llama-stack/Containerfile.llama-stack-run-k8s -t llama-stack-run-k8s /tmp/test-vllm-llama-stack
</code></pre></div></div>
<p>We can then start the LlamaStack server by deploying a Kubernetes Pod and Service:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>cat <<EOF |kubectl apply -f -
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: llama-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:
name: llama-stack-pod
labels:
app: llama-stack
spec:
containers:
- name: llama-stack
image: localhost/llama-stack-run-k8s:latest
imagePullPolicy: IfNotPresent
command: ["python", "-m", "llama_stack.distribution.server.server", "--yaml-config", "/app/config.yaml"]
ports:
- containerPort: 5000
volumeMounts:
- name: llama-storage
mountPath: /root/.llama
volumes:
- name: llama-storage
persistentVolumeClaim:
claimName: llama-pvc
---
apiVersion: v1
kind: Service
metadata:
name: llama-stack-service
spec:
selector:
app: llama-stack
ports:
- protocol: TCP
port: 5000
targetPort: 5000
type: ClusterIP
EOF
</code></pre></div></div>
<p>We can check that the LlamaStack server has started:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>$ kubectl logs vllm-server
...
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: ASGI 'lifespan' protocol appears unsupported.
INFO: Application startup complete.
INFO: Uvicorn running on http://['::', '0.0.0.0']:5000 (Press CTRL+C to quit)
</code></pre></div></div>
<p>Now let’s forward the Kubernetes service to a local port and test some inference requests against it via the Llama Stack Client:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>kubectl port-forward service/llama-stack-service 5000:5000
llama-stack-client --endpoint http://localhost:5000 inference chat-completion --message "hello, what model are you?"
</code></pre></div></div>
<p>You can learn more about different providers and functionalities of Llama Stack on <a href="https://llama-stack.readthedocs.io">the official documentation</a>.</p>
<h2 id="acknowledgement">Acknowledgement</h2>
<p>We’d like to thank the Red Hat AI Engineering team for the implementation of the vLLM inference providers, contributions to many bug fixes, improvements, and key design discussions. We also want to thank the Llama Stack team from Meta and the vLLM team for their timely PR reviews and bug fixes.</p>
blog.vllm.ai
February 4, 2025 at 5:11 PM
Introducing vLLM Inference Provider in Llama Stack
https://blog.vllm.ai/2025/01/27/intro-to-llama-stack-with-vllm.html
#artificialintelligence #ai #vllm #llamastack #opensource #redhat
https://blog.vllm.ai/2025/01/27/intro-to-llama-stack-with-vllm.html
#artificialintelligence #ai #vllm #llamastack #opensource #redhat

Bluesky's Top 10 Trending Words (past 10min):
💨x125 - d'angelo
💨x1* - gaza 🔓
💨x1* - democracy 🔓
💨x1* - ukraine 🔓
💨x30 - struzan
💨x20 - réforme
💨x20 - disarm
💨x18 - retraites
💨x15 - dissidia
💨x14 - r+b
*🔓 = Unlocked Emergency Words (see img)
#йобанарусня 🇺🇦
(Something not right? Reply!)



![Emoji Legend
💨x# | "Increased Trending Rate" for a Word (meaningful value; "💨x8 - burger" will mean "burger" is trending at 8 times its own normal rate for this time of day)
🔓 | "Unlocked" Ongoing Emergency Word (such words are not weighted down by their own previous usage; their *ongoing* increased usage--weeks, months, years--would otherwise move them down the list.)
[PREVIOUSLY USED]
⚠️💨# | "Trend Strength Rating"
⚠️🌀💨 | "Trend Strength Rating" (see above)
⚠️🌀 CAT. # | [same; "CAT." = Category, like hurricane]
💬# | 10min Post Count
🆎# | 10min Word Count
🙂# | 10min Emoji Count](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:mcb6n67plnrlx4lg35natk2b/bafkreigp6bgag3jzkool6uxrujpcrwtn6zkd7cbfrmevhaxaqhhewgolmu@jpeg)
October 14, 2025 at 6:30 PM

Open-source AI needs infrastructure that scales responsibly.
Llama Stack isn’t everything — but it’s a focused contribution:
• Minimal lock-in
• Broad compatibility
• Strong community roots
🧵 #opensourceAI #AIinfra #llamastack #genAI #LLMops
Llama Stack isn’t everything — but it’s a focused contribution:
• Minimal lock-in
• Broad compatibility
• Strong community roots
🧵 #opensourceAI #AIinfra #llamastack #genAI #LLMops
July 23, 2025 at 1:04 PM
Open-source AI needs infrastructure that scales responsibly.
Llama Stack isn’t everything — but it’s a focused contribution:
• Minimal lock-in
• Broad compatibility
• Strong community roots
🧵 #opensourceAI #AIinfra #llamastack #genAI #LLMops
Llama Stack isn’t everything — but it’s a focused contribution:
• Minimal lock-in
• Broad compatibility
• Strong community roots
🧵 #opensourceAI #AIinfra #llamastack #genAI #LLMops

Opened my first bug report on llama-stack as weirdly it doesn't accept the application/json mime type for Agent documents but text/json, which AFAIK has been defunct for ages, works fine.
github.com/llamastack/l...
github.com/llamastack/l...

Agent does not accept documents with mime type of application/json · Issue #3300 · llamastack/llama-stack
System Info I'm just using the llama-stack starter distribution with an OpenAI inference back-end. Information The official example scripts My own modified scripts 🐛 Describe the bug When attemptin...
github.com
September 1, 2025 at 7:42 PM
Opened my first bug report on llama-stack as weirdly it doesn't accept the application/json mime type for Agent documents but text/json, which AFAIK has been defunct for ages, works fine.
github.com/llamastack/l...
github.com/llamastack/l...

✨LLAMA MACOS DESKTOP CONTROLLER✨
MacOS LLM Controller lets users execute macOS commands using natural language via text or voice. It displays a real-time status and command history. Uses LlamaStack, React, and Flask. See setup steps in readme.
MacOS LLM Controller lets users execute macOS commands using natural language via text or voice. It displays a real-time status and command history. Uses LlamaStack, React, and Flask. See setup steps in readme.

LLAMA MACOS DESKTOP CONTROLLER
MacOS LLM Controller lets users execute macOS commands using natural language via text or voice. It displays a real-time status and command history. Uses LlamaStack, React, and Flask. See setup steps in readme.
github.com
April 15, 2025 at 2:16 AM
✨LLAMA MACOS DESKTOP CONTROLLER✨
MacOS LLM Controller lets users execute macOS commands using natural language via text or voice. It displays a real-time status and command history. Uses LlamaStack, React, and Flask. See setup steps in readme.
MacOS LLM Controller lets users execute macOS commands using natural language via text or voice. It displays a real-time status and command history. Uses LlamaStack, React, and Flask. See setup steps in readme.

rhdedgar commented on pull request llamastack/llama-stack-k8s-operator#44 rhdedgar commented on llamastack/llama-stack-k8s-operator#44 · June 4, 2025 19:59 rhdedgar commented Jun 4, 2025 +1, That should work as long as it's not being blocked by a Netwo...
| Details | Interest | Feed |
| Details | Interest | Feed |
Origin
github.com
June 4, 2025 at 8:14 PM
If you're building with or around open-source AI infra, here are ways to plug in:
🤝 Partner interest:
events.thealliance.ai/llamastack?u...
🧠 GitHub:
github.com/The-AI-Allia...
📬 Updates:
thealliance.ai/contact?utm_...
🤝 Partner interest:
events.thealliance.ai/llamastack?u...
🧠 GitHub:
github.com/The-AI-Allia...
📬 Updates:
thealliance.ai/contact?utm_...
AI Alliance Llama Stack Business Survey
events.thealliance.ai
July 23, 2025 at 1:04 PM
If you're building with or around open-source AI infra, here are ways to plug in:
🤝 Partner interest:
events.thealliance.ai/llamastack?u...
🧠 GitHub:
github.com/The-AI-Allia...
📬 Updates:
thealliance.ai/contact?utm_...
🤝 Partner interest:
events.thealliance.ai/llamastack?u...
🧠 GitHub:
github.com/The-AI-Allia...
📬 Updates:
thealliance.ai/contact?utm_...

Good to run integration test after this kind of change
github.com/llamastack/llama-stack/pull/3969/files They added access control logic in get_session_info and get_session_if_accessible: if user is None They skip certain checks. That means behaviors for anonymous user might diverge. While the…
github.com/llamastack/llama-stack/pull/3969/files They added access control logic in get_session_info and get_session_if_accessible: if user is None They skip certain checks. That means behaviors for anonymous user might diverge. While the…
Good to run integration test after this kind of change
github.com/llamastack/llama-stack/pull/3969/files They added access control logic in get_session_info and get_session_if_accessible: if user is None They skip certain checks. That means behaviors for anonymous user might diverge. While the type safety improves, sometimes stricter types can force runtime changes or reveal latent bugs
kvnbbg.fr
October 29, 2025 at 8:51 PM
Good to run integration test after this kind of change
github.com/llamastack/llama-stack/pull/3969/files They added access control logic in get_session_info and get_session_if_accessible: if user is None They skip certain checks. That means behaviors for anonymous user might diverge. While the…
github.com/llamastack/llama-stack/pull/3969/files They added access control logic in get_session_info and get_session_if_accessible: if user is None They skip certain checks. That means behaviors for anonymous user might diverge. While the…

A critical vulnerability in Meta's Llama Stack enables potential remote code execution. Meta has issued a patch; users are urged to upgrade to the latest version to maintain security. Stay safe and secure your applications. #cybersecurity #threat #Meta #LlamaStack

Critical Vulnerability Identified in Meta's Llama Stack
A critical vulnerability identified in Meta's Llama Stack framework allows for potential remote code execution, prompting the company to release a patch and recommend users upgrade to a newer version.
decrypt.lol
January 23, 2025 at 10:17 PM
A critical vulnerability in Meta's Llama Stack enables potential remote code execution. Meta has issued a patch; users are urged to upgrade to the latest version to maintain security. Stay safe and secure your applications. #cybersecurity #threat #Meta #LlamaStack

#LlamaStack: Open APIs for #GenerativeAI apps 🦙 #OpenSource specs & providers for inference, safety, memory & more Standardizes building blocks across dev lifecycle Supports various environments: local, hosted, on-device #AI #LLM #Productivity
github.com/meta-llama/l...
github.com/meta-llama/l...

GitHub - meta-llama/llama-stack: Model components of the Llama Stack APIs
Model components of the Llama Stack APIs. Contribute to meta-llama/llama-stack development by creating an account on GitHub.
github.com
September 29, 2024 at 8:34 PM
#LlamaStack: Open APIs for #GenerativeAI apps 🦙 #OpenSource specs & providers for inference, safety, memory & more Standardizes building blocks across dev lifecycle Supports various environments: local, hosted, on-device #AI #LLM #Productivity
github.com/meta-llama/l...
github.com/meta-llama/l...

Great to see practical examples like Michael Dawson’s article @developers.RedHat.com on using #MCP, function calls etc from #LLMs (with #LlamaStack in this case)!

A practical guide to Llama Stack for Node.js developers | Red Hat Developer
Explore how to run tools with Node.js using Llama Stack's completions API, agent API, and support for in-line tools, local MCP tools, and remote MCP tools.
developers.redhat.com
April 2, 2025 at 9:39 AM
Great to see practical examples like Michael Dawson’s article @developers.RedHat.com on using #MCP, function calls etc from #LLMs (with #LlamaStack in this case)!

Couldn’t be happier after a busy few days in Berlin for @wearedevelopers.bsky.social World Congress, catching up with friends & hanging out at the #RedHat stage! I’ll link my own developer & AI engineer focused sessions below, featuring @podmanio.bsky.social #vLLM & Meta’s #LlamaStack!



July 11, 2025 at 1:47 PM
Couldn’t be happier after a busy few days in Berlin for @wearedevelopers.bsky.social World Congress, catching up with friends & hanging out at the #RedHat stage! I’ll link my own developer & AI engineer focused sessions below, featuring @podmanio.bsky.social #vLLM & Meta’s #LlamaStack!

rhdedgar commented on pull request llamastack/llama-stack-k8s-operator#44 rhdedgar commented on l...
https://github.com/llamastack/llama-stack-k8s-operator/pull/44#discussion_r2127342429
Result Details
https://github.com/llamastack/llama-stack-k8s-operator/pull/44#discussion_r2127342429
Result Details
Awakari App
awakari.com
June 4, 2025 at 8:16 PM
rhdedgar commented on pull request llamastack/llama-stack-k8s-operator#44 rhdedgar commented on l...
https://github.com/llamastack/llama-stack-k8s-operator/pull/44#discussion_r2127342429
Result Details
https://github.com/llamastack/llama-stack-k8s-operator/pull/44#discussion_r2127342429
Result Details