



Oh wie cool, es gibt jetzt hier an der Uni #bamberg ein Projekt zur Struktur- und Inhaltserkennung für historische #tabellen #ocr https://fis.uni-bamberg.de/handle/uniba/106526
Aufbau und Bereitstellung eines Benchmark-Datensatzes von historischen Tabellen (1750-1990)
BenchmarkDatensatz [2025-03-01 - ] Tabellarisch strukturierte Quellen spielen in der Sozial- und Wirtschaftsgeschichte sowie in anderen historisch arbeitenden Geisteswissenschaften eine zentrale Rolle als Datenlieferanten. Während in den letzten Jahren die KI-gestützte Texterkennung angewandt auf narrative Quellen rasante Fortschritte verzeichnen konnte, hinkt der Bereich der KI-gestützten Struktur- und Inhaltserkennung von historischen gedruckten Tabellen, noch stark hinterher. Tabellarisch aufgebaute Nachschlagewerke mit einer zentralen Bedeutung für die Sozial- und Wirtschaftsgeschichte, wie etwa Preiskuranten, Bevölkerungstabellen, oder Nachschlagewerke für den kaufmännischen Gebrauch, sind zwar als Digitalisate verfügbar, aber aufgrund ihrer komplexen tabellarischen Struktur kaum umfassend auswertbar. Im jetzigen Status Quo ist die KI-gestützte Bearbeitung von historischen Tabellen bestenfalls teil-automatisiert, in der Nachbearbeitung zeitaufwendig, und aufgrund der Vielfalt und Komplexität historischer Tabellen kaum skalierbar. Vorhandene Tools, wie etwa das in der Beta-Version verfügbare Tabellenerfassungstool von Transkribus, bieten entweder für ein bestimmtes, konsistentes Tabellenformat eine Lösung oder müssen händisch auf Tabellen angewandt werden. Das Projekt setzt sich zum Ziel, die KI-gestützte automatische Struktur- und Inhaltserkennung von historischen Tabellen wesentlich zu verbessern. Um dieses Ziel zu erreichen, planen wir den Aufbau und die Bereitstellung eines Benchmark-Datensatzes von gedruckten historischen Tabellen aus dem Zeitraum von 1750 bis 1990 – von der frühstatistischen Zeit bis zu den Anfängen des WWW, der die Vielfalt und die historische Entwicklung von tabellarischen Datenrepräsentationen abbildet und die Merkmale der Tabellen in Labels (Annotationen) erfasst. Wir planen mit einem Umfang von ca. 10.000 Tabellenseiten, und streben eine Verteilung an, die der relativen Bedeutung der Jahrhunderte in unserem Zeitraum entspricht (15% 1750-1800; 30% 1800-1900 und 55% 1900-1990). Wir widmen uns ausschließlich gedruckten ganzseitigen, doppelseitigen und mehrseitigen Tabellen und Tabellenwerken (d.h. Büchern, die (fast) ausschließlich aus Tabellen bestehen). Im Rahmen der ICDAR, die International Conference on Document Analysis and Recognition, fand zuletzt 2019 einen Wettbewerb zu einem Benchmark-Datensatz mit gedruckten und zum Teil sogar einigen handgeschriebenen archivalischen Tabellen statt. Auch in anderen Konstellationen wurden Benchmark-Datensätze (z.B. TableBank und PubTables-1M) für die Struktur- und Inhaltserkennung von Tabellen entwickelt und getestet, an denen wir uns für die Beantwortung von methodischen, technischen und infrastrukturellen Fragen orientieren werden. Mit unserem annotierten Benchmark-Datensatz werden zum ersten Mal überhaupt Trainingsdaten im großen Umfang zur Verfügung stehen, anhand dessen die Entwicklung von neuen informatischen Lösungen für die Erschließung von historischen Tabellenbeständen erprobt und ausgewertet werden kann. Das streben wir gezielt an, indem wir uns mit einem Wettbewerb für die Teilnahme an der ICDAR Konferenz in Wien 2026 bewerben werden. Für den Aufbau und die Bereitstellung des Benchmark-Datensatzes orientieren wir uns an Best Practices im Bereich der Tabellenerkennung in den Computer Sciences. Zum Benchmark-Datensatz stellen wir ein Evaluationsprotokoll zur Verfügung. Darüber hinaus stellen wir für ausgewählte Tabellen auch Ground Truth Daten für die Tabelleninhaltserkennung zur Verfügung, die von Mitgliedern der Community von Sozial- und Wirtschaftshistorikerinnen und –historikern geliefert werden.
fis.uni-bamberg.de
March 20, 2025 at 10:33 AM
Oh wie cool, es gibt jetzt hier an der Uni #bamberg ein Projekt zur Struktur- und Inhaltserkennung für historische #tabellen #ocr https://fis.uni-bamberg.de/handle/uniba/106526

ELIXIR-IT coordinates SUNRISE, a national project by CNR with UNIBA, UNINA, and UNISS.
🎯 Goal: Strengthen ELIXIR-IT, EBRAINS-Italy, and Euro-BioImaging-ITALY promoting research-industry integration.
📣 EOI: 23/05/25
🔗 www.urp.cnr.it/node/27204
🎯 Goal: Strengthen ELIXIR-IT, EBRAINS-Italy, and Euro-BioImaging-ITALY promoting research-industry integration.
📣 EOI: 23/05/25
🔗 www.urp.cnr.it/node/27204
id-20250509-143223 | CNR - Unità Relazioni con il Pubblico e Comunicazione integrata
www.urp.cnr.it
May 15, 2025 at 9:43 AM
ELIXIR-IT coordinates SUNRISE, a national project by CNR with UNIBA, UNINA, and UNISS.
🎯 Goal: Strengthen ELIXIR-IT, EBRAINS-Italy, and Euro-BioImaging-ITALY promoting research-industry integration.
📣 EOI: 23/05/25
🔗 www.urp.cnr.it/node/27204
🎯 Goal: Strengthen ELIXIR-IT, EBRAINS-Italy, and Euro-BioImaging-ITALY promoting research-industry integration.
📣 EOI: 23/05/25
🔗 www.urp.cnr.it/node/27204

📣 New Podcast! "09 Grige & Bauman (Eng) | 2.1-2 Functions of intonation; Lexical and morphological marking; Syntactic functions" on @Spreaker #bauman #comunicazione #grice #intonation #language #linguistica #savino #scienze #study #uniba

09 Grige & Bauman (Eng) | 2.1-2 Functions of intonation; Lexical and morphological marking; Syntactic functions
2. Functions of intonation
In spoken language, intonation serves diverse linguistic and paralinguistic functions, ranging from the marking of sentence modality to the expression of emotional and attitudinal nuances. It is important to identify how they are expressed in the learner's native language, so that differences between the native and target languages are identified. It is particularly important to point out that many aspects of information structure and indirect speech acts are expressed differently across languages. Making learners aware of the existence of these functions will not only help them learn to express them, but will also help them to interpret what they hear in a more analytic way, thus reducing the danger of attributing unexpected intonation patterns as (solely) a function of the attitude or emotional state of the speaker.
We have seen that intonation analysis involves categorical decisions about whether there is stress or accent, and, if there is an accent, which type of pitch accent it is. It also involves decisions about whether a boundary is present, and if so which pitch movement or level is used to mark it. There are also many gradient aspects to intonation, such as variation in pitch height or in the exact shape of the contour (equivalent to allophonic variation in the segmental domain).
2.1. Lexical and morphological marking
Lexical and morphological marking does not belong to intonation proper but uses pitch, and to some extent also the other channels used by intonation. Categorical tonal contrasts at word level are characteristic of tone languages. Two quite different examples of tone languages are Standard Chinese, which has lexical contrasts such as the well-known example of the syllable ma with four different tonal contours, each which constitutes a distinct lexical item (mother, hemp, horse and scold), and the West African (Niger Congo) language Bini, which has grammatical tone: a change of tone marks the difference between tenses, e.g. low tone marking present tense and high or high-low tones marking past tense (see Crystal 1987: 172). Categorical tonal contrasts are also characteristic of so-called pitch accent languages which may also have lexical or grammatical tone. Both Swedish and Japanese are pitch accent languages. The difference between tone languages and pitch accent languages is that the former have contrastive tone on almost all syllables, whilst the latter restrict their tonal contrasts to specific syllables, which bear a pitch accent. However, it is difficult to draw a dividing line between these two language categories (see
Gussenhoven 2004: 47).
In intonation languages (the most thoroughly studied of which are generally also stress accent languages) like English and German, pitch is solely a postlexical feature, i.e. it is only relevant at utterance level. All tone and pitch accent languages have intonation in addition to their lexical and/or grammatical tone, although the complexity of their intonation systems varies considerably.
2.2. Syntactic functions
As we have already pointed out, syntactic structure and intonational phrasing are strongly related, but do not have to correspond exactly. Intonation can be used to disambiguate in certain cases between two different syntactic structures. The attachment of prepositional phrases is often said to be signalled by intonation. For example, in (6), a phrase break after verfolgt tends to lead to the interpretation that it is the man with the motorbike which Rainer is following. A phrase break after Mann would tend to lead to the interpretation that Rainer is on his motorbike and is following a man whilst riding it. In the first case the prepositional phrase modifies the noun phrase (den Mann) and in the second it modifies the verb (verfolgt). This phrasing has the same effect in the English translation.
(6) Rainer verfolgt den Mann mit dem Motorrad.
‘Rainer is following the man with the motorbike.’
However, it is often unnecessary to disambiguate between two readings, particularly if the context is clear. It should therefore not be expected that speakers will make such distinctions all of the time. A study on Italian and English syntactic disambiguation (Hirschberg and Avesani 2000) showed this particularly clearly, not only for prepositional phrase attachments, as in (7a), but also for ambiguously attached adverbials, as in (7b) (adapted from Hirschberg and Avesani 2000: 93).
(7a) Ha disegnato un bambino con una penna. ‘lit. He drew a child with a pen’
(7b) Lui le aveva parlato chiaramente. ‘lit. He to her has spoken clearly.’
The two readings of (7b) are either that it was clear that he spoke to her (the adverbial modifies the sentence) or that he spoke to her in a clear manner (the adverbial modifies the verb).
www.spreaker.com
November 16, 2025 at 6:45 PM
📣 New Podcast! "09 Grige & Bauman (Eng) | 2.1-2 Functions of intonation; Lexical and morphological marking; Syntactic functions" on @Spreaker #bauman #comunicazione #grice #intonation #language #linguistica #savino #scienze #study #uniba

Hey! Connect with us to follow the news on project UkraIntegration - Navigating Ukrainians’ Integration in Slovakia:
Multifaceted approach to identifying its barriers and facilitators.
More information on the project and the opening round table soon.
#migration #research #socialresearch #UNIBA
Multifaceted approach to identifying its barriers and facilitators.
More information on the project and the opening round table soon.
#migration #research #socialresearch #UNIBA
November 7, 2025 at 4:50 PM
Hey! Connect with us to follow the news on project UkraIntegration - Navigating Ukrainians’ Integration in Slovakia:
Multifaceted approach to identifying its barriers and facilitators.
More information on the project and the opening round table soon.
#migration #research #socialresearch #UNIBA
Multifaceted approach to identifying its barriers and facilitators.
More information on the project and the opening round table soon.
#migration #research #socialresearch #UNIBA

🧠🎉 New paper in #AdvancedScience! 👏
Giuseppe Stolfa, from #UNIBA, used a novel #graph-based approach to define meta-ROIs on resting-state #fMRI data from 1,200+ subjects. Prefrontal-striatal #connectivity is associated to executive function and altered in #psychosis, even without cognitive deficits
Giuseppe Stolfa, from #UNIBA, used a novel #graph-based approach to define meta-ROIs on resting-state #fMRI data from 1,200+ subjects. Prefrontal-striatal #connectivity is associated to executive function and altered in #psychosis, even without cognitive deficits
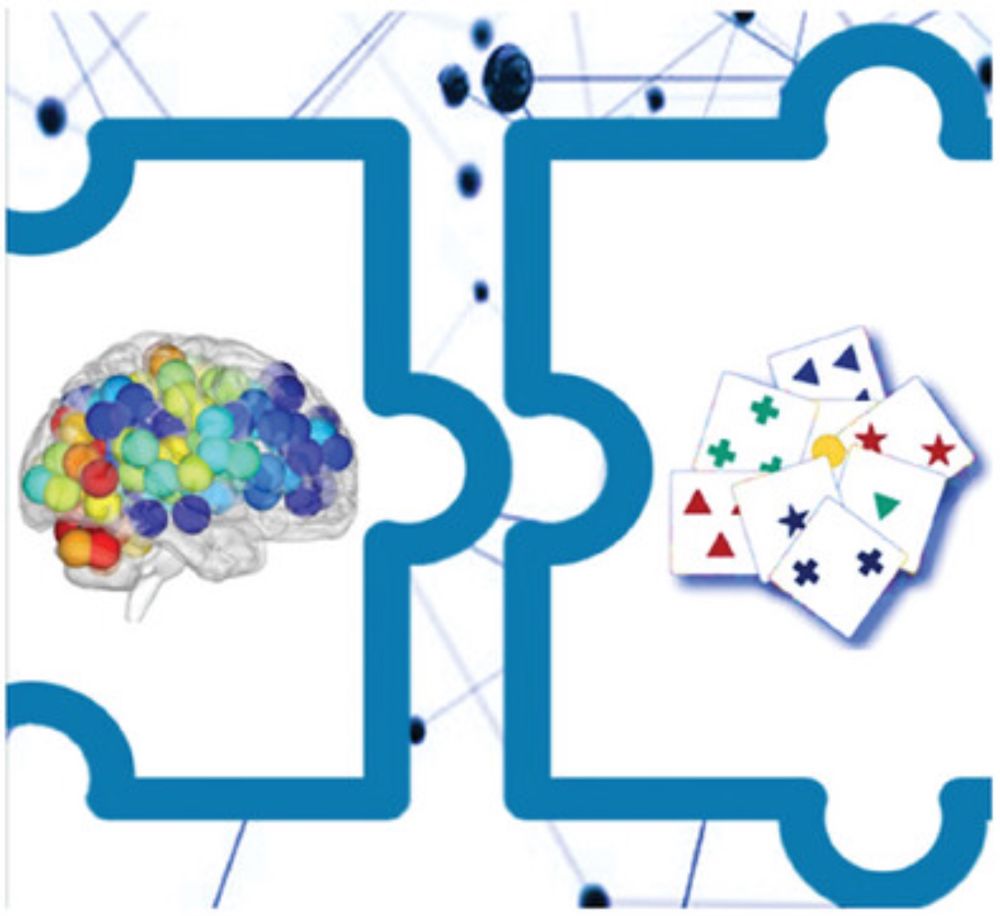
Altered Brain‐Behavior Association During Resting State is a Potential Psychosis Risk Marker
The study detects a potential multimodal biomarker that can be promising for identifying early markers of psychosis. It shows a consistent brain-behavior association between a circuit of interconnect...
advanced.onlinelibrary.wiley.com
April 4, 2025 at 9:20 AM
🧠🎉 New paper in #AdvancedScience! 👏
Giuseppe Stolfa, from #UNIBA, used a novel #graph-based approach to define meta-ROIs on resting-state #fMRI data from 1,200+ subjects. Prefrontal-striatal #connectivity is associated to executive function and altered in #psychosis, even without cognitive deficits
Giuseppe Stolfa, from #UNIBA, used a novel #graph-based approach to define meta-ROIs on resting-state #fMRI data from 1,200+ subjects. Prefrontal-striatal #connectivity is associated to executive function and altered in #psychosis, even without cognitive deficits

Ma quello è il polifunzionale di medicina uniba!
November 29, 2024 at 12:00 PM
Ma quello è il polifunzionale di medicina uniba!

Uniba Papua dorong peningkatan literasi digital dan kearifan lokal - https://www.antaranews.com/berita/5090597/uniba-papua-dorong-peningkatan-literasi-digital-dan-kearifan-lokal

Uniba Papua dorong peningkatan literasi digital dan kearifan lokal
Universitas Baliem (Uniba) Papua mendorong peningkatan literasi digital dan kearifan lokal guna meningkatkan pengetahuan modern dan tradisional.Uniba Papua ...
www.antaranews.com
September 6, 2025 at 5:39 AM
Uniba Papua dorong peningkatan literasi digital dan kearifan lokal - https://www.antaranews.com/berita/5090597/uniba-papua-dorong-peningkatan-literasi-digital-dan-kearifan-lokal

EFHW給電点の検証😇
github.com/DG1JAN/UniBa...
github.com/DG1JAN/UniBa...




March 31, 2024 at 12:02 PM
EFHW給電点の検証😇
github.com/DG1JAN/UniBa...
github.com/DG1JAN/UniBa...

[10:24] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (12 listeners) listen at j1fm.tokyo
June 19, 2025 at 1:24 AM
[10:24] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (12 listeners) listen at j1fm.tokyo

Call for Papers: Arbeit – Macht – Würde. Machtasymmetrien und Würdeverletzungen in Arbeitskontexten https://samf.de/wp-content/uploads/2024/10/CfP-Samf-HBS-FES-DIFIS-UniBA-Tagung2025.pdf
October 24, 2024 at 12:42 PM
Call for Papers: Arbeit – Macht – Würde. Machtasymmetrien und Würdeverletzungen in Arbeitskontexten https://samf.de/wp-content/uploads/2024/10/CfP-Samf-HBS-FES-DIFIS-UniBA-Tagung2025.pdf
📣 New Podcast! "06 Grige & Bauman (Eng) | 1.1. Highlighting" on @Spreaker #comunicazione #grice #intonazione #linguistica #savino #uniba
06 Grige & Bauman (Eng) | 1.1. Highlighting
In languages like English and German, utterance level prominence is realised on a designated syllable either by means of increased loudness and length, and unreduced vowel quality (all contributing to stress) or by means of the above, accompanied by a pitch movement (accent). This is not the case for all languages. Some languages use pitch movement without the accompanying loudness, length and vowel reduction (or at least using them to a lesser degree). English and German are referred to by Beckman (1986) as ‘stress-accent languages’, in contrast to, e.g., Japanese, which is a ‘non-stress accent language’. Both pitch movements with stress in stress-accent languages, and those without stress in non-stress-accent languages are referred to as pitch accents. In what is to follow, we concentrate on pitch accents in stress-accent languages.
The notion of ‘stress’ applies to both word and utterance levels. We differentiate between ‘lexical stress’, also called ‘word stress’, denoting abstract prominences at word level, and ‘postlexical stress’, concrete prominences at utterance level. Table 2 summarises the different levels of description.
The difference between stresses and accents entails a difference in the strength or degree of (postlexical) prominence. There are at least four different degrees of prominence at utterance level, as listed in table 3.
In (3) we provide an extended version of utterance (1) above. It might conceivably be produced with a nuclear pitch accent on Haus (‘house’), a non-nuclear pitch accent on the first syllable of schönes (‘beautiful’), and stress on the first syllable of Lena (and possibly also on –kauft). All other syllables can be thought of as unaccented. In this and later examples, pitch accents are indicated by capital letters, stresses by small capitals.
www.spreaker.com
November 16, 2025 at 5:52 PM
📣 New Podcast! "06 Grige & Bauman (Eng) | 1.1. Highlighting" on @Spreaker #comunicazione #grice #intonazione #linguistica #savino #uniba
[23:26] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (20 listeners) listen at j1fm.tokyo
July 27, 2025 at 2:26 PM
[23:26] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (20 listeners) listen at j1fm.tokyo
[09:24] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (11 listeners) listen at j1fm.tokyo
December 11, 2025 at 12:24 AM
[09:24] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (11 listeners) listen at j1fm.tokyo

🎓Oggi, studenti di Salve,Supersano e Alliste al CNR-IRET e #UniSalento per scoprire la biodiversità nascosta!
Con #ITINERIS, #Uniba e @lifewatcheric.bsky.social , la ricerca tra i giovani per:
✅ Combattere la povertà educativa
🌱 Valorizzare gli ecosistemi
👥 Rafforzare la partecipazione
Con #ITINERIS, #Uniba e @lifewatcheric.bsky.social , la ricerca tra i giovani per:
✅ Combattere la povertà educativa
🌱 Valorizzare gli ecosistemi
👥 Rafforzare la partecipazione




May 9, 2025 at 11:24 AM
🎓Oggi, studenti di Salve,Supersano e Alliste al CNR-IRET e #UniSalento per scoprire la biodiversità nascosta!
Con #ITINERIS, #Uniba e @lifewatcheric.bsky.social , la ricerca tra i giovani per:
✅ Combattere la povertà educativa
🌱 Valorizzare gli ecosistemi
👥 Rafforzare la partecipazione
Con #ITINERIS, #Uniba e @lifewatcheric.bsky.social , la ricerca tra i giovani per:
✅ Combattere la povertà educativa
🌱 Valorizzare gli ecosistemi
👥 Rafforzare la partecipazione
[08:18] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (10 listeners) listen at j1fm.tokyo
March 27, 2025 at 11:18 PM
[08:18] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (10 listeners) listen at j1fm.tokyo
[04:15] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (18 listeners) listen at j1fm.tokyo
May 16, 2025 at 7:15 PM
[04:15] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (18 listeners) listen at j1fm.tokyo

📌Reminder! La deadline per l'invio delle proposte per il #ConvegnoGiovaniSISEC (UNIBA, 16-17/10/25) è il 20 giugno 2025👇
#convegni II Convegno Early-career Researchers SISEC - PER UNA GIUSTA TRIPLA TRANSIZIONE. IL COMPLESSO INTRECCIO TRA AMBIENTE, TECNOLOGIA E DEMOGRAFIA @ Dip di Scienze Politiche, Univ di Bari Aldo Moro,
16-17/10/25. Deadline per invio proposte: 20/6/25. Tutte le info 👇🏻
sisec.it/convegni-gio...
16-17/10/25. Deadline per invio proposte: 20/6/25. Tutte le info 👇🏻
sisec.it/convegni-gio...

II° Convegno Early-career Researchers SISEC – BARI 2025 - SISEC
Convegni Early-career Researchers II Convegno Early-career Researchers SISEC - BARI 2025 16 - 17 ottobre 2025 Informazioni Call for abstract Il convegno “Per una giusta Tripla Transizione. Il compless...
sisec.it
June 16, 2025 at 10:13 AM
📌Reminder! La deadline per l'invio delle proposte per il #ConvegnoGiovaniSISEC (UNIBA, 16-17/10/25) è il 20 giugno 2025👇




July 10, 2025 at 6:19 AM

[23:05] J1 HD - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - listen at j1fm.tokyo and FM 99.1 HD3 Malibu & LA western facing beaches.
November 3, 2025 at 7:05 AM
[23:05] J1 HD - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - listen at j1fm.tokyo and FM 99.1 HD3 Malibu & LA western facing beaches.
📌Reminder! La deadline per l'invio delle proposte per il #ConvegnoGiovaniSISEC (UNIBA, 16-17/10/25) è il 20 giugno 2025👇
#convegni II Convegno Early-career Researchers SISEC - PER UNA GIUSTA TRIPLA TRANSIZIONE. IL COMPLESSO INTRECCIO TRA AMBIENTE, TECNOLOGIA E DEMOGRAFIA @ Dip di Scienze Politiche, Univ di Bari Aldo Moro,
16-17/10/25. Deadline per invio proposte: 20/6/25. Tutte le info 👇🏻
sisec.it/convegni-gio...
16-17/10/25. Deadline per invio proposte: 20/6/25. Tutte le info 👇🏻
sisec.it/convegni-gio...
II° Convegno Early-career Researchers SISEC – BARI 2025 - SISEC
Convegni Early-career Researchers II Convegno Early-career Researchers SISEC - BARI 2025 16 - 17 ottobre 2025 Informazioni Call for abstract Il convegno “Per una giusta Tripla Transizione. Il compless...
sisec.it
May 6, 2025 at 2:35 PM
📌Reminder! La deadline per l'invio delle proposte per il #ConvegnoGiovaniSISEC (UNIBA, 16-17/10/25) è il 20 giugno 2025👇
[11:22] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (18 listeners) listen at j1fm.tokyo
July 8, 2025 at 2:22 AM
[11:22] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (18 listeners) listen at j1fm.tokyo
[09:52] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (12 listeners) listen at j1fm.tokyo
December 16, 2025 at 12:52 AM
[09:52] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (12 listeners) listen at j1fm.tokyo
[11:34] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (16 listeners) listen at j1fm.tokyo
May 2, 2025 at 2:34 AM
[11:34] J1 XTRA - Now Playing: Mimori Suzuko (三森すずこ) - Uniba Page (ユニバーページ) - (16 listeners) listen at j1fm.tokyo

allhamdulilah tetep uniba di gencangan dan di tempuran org org pada milih ugm ui dkk 😝😝
September 25, 2025 at 9:03 AM
allhamdulilah tetep uniba di gencangan dan di tempuran org org pada milih ugm ui dkk 😝😝