



This work is the result of a collaboration with a great team. Thanks to my co-authors:
Eyal Ben David, Hadas Orgad, Eran Ofek, Yonatan Belinkov, Idan Szpektor, Jonathan Herzig, and Roi Reichart.
Paper: arxiv.org/abs/2503.15299
17/🧵 (end)
Eyal Ben David, Hadas Orgad, Eran Ofek, Yonatan Belinkov, Idan Szpektor, Jonathan Herzig, and Roi Reichart.
Paper: arxiv.org/abs/2503.15299
17/🧵 (end)

Inside-Out: Hidden Factual Knowledge in LLMs
This work presents a framework for assessing whether large language models (LLMs) encode more factual knowledge in their parameters than what they express in their outputs. While a few studies hint at...
arxiv.org
March 31, 2025 at 6:34 PM
This work is the result of a collaboration with a great team. Thanks to my co-authors:
Eyal Ben David, Hadas Orgad, Eran Ofek, Yonatan Belinkov, Idan Szpektor, Jonathan Herzig, and Roi Reichart.
Paper: arxiv.org/abs/2503.15299
17/🧵 (end)
Eyal Ben David, Hadas Orgad, Eran Ofek, Yonatan Belinkov, Idan Szpektor, Jonathan Herzig, and Roi Reichart.
Paper: arxiv.org/abs/2503.15299
17/🧵 (end)
We hope our framework facilitates future research on hidden knowledge, ultimately leading to more transparent and reliable LLMs.
16/🧵
16/🧵
March 31, 2025 at 6:34 PM
We hope our framework facilitates future research on hidden knowledge, ultimately leading to more transparent and reliable LLMs.
16/🧵
16/🧵
Yet the fact that models fail to generate known answers puts a practical constraint on scaling test-time compute via repeated sampling in closed-book QA. Significant gains remain inaccessible because we fail to sample answers that the probe would otherwise rank first.
15/🧵
15/🧵
March 31, 2025 at 6:34 PM
Yet the fact that models fail to generate known answers puts a practical constraint on scaling test-time compute via repeated sampling in closed-book QA. Significant gains remain inaccessible because we fail to sample answers that the probe would otherwise rank first.
15/🧵
15/🧵
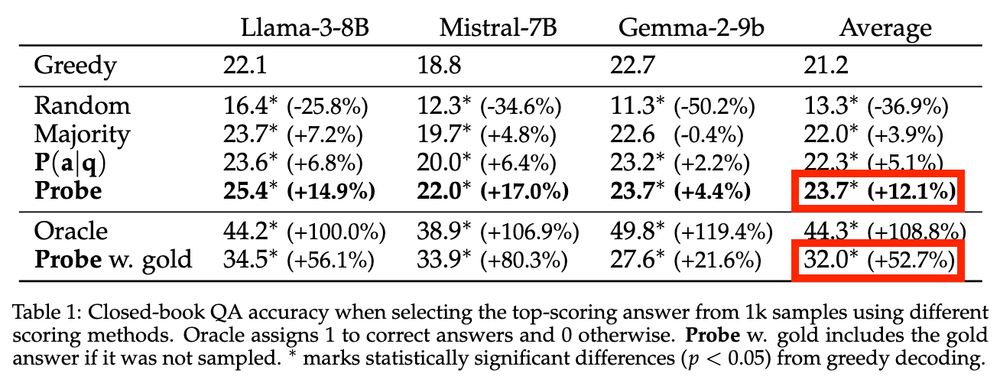
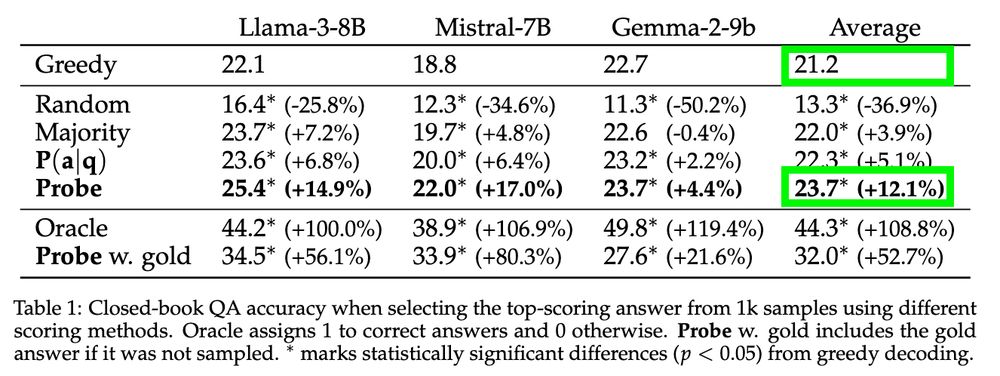
We also leverage our setup to enhance performance in a challenging closed-book QA setting, achieving a 12% average relative improvement over greedy decoding by increasing test-time compute: sampling a large set of answers and selecting the top one using our probe.
14/🧵
14/🧵
March 31, 2025 at 6:34 PM
We also leverage our setup to enhance performance in a challenging closed-book QA setting, achieving a 12% average relative improvement over greedy decoding by increasing test-time compute: sampling a large set of answers and selecting the top one using our probe.
14/🧵
14/🧵
For example, here the correct answer “Volvo Buses” gets a very low P(a | q) score, meaning it is unlikely to be generated. Accordingly, it wasn’t sampled after 1,000 attempts in our study. Yet the probe scores it higher than all other alternatives.
13/🧵
13/🧵

March 31, 2025 at 6:34 PM
For example, here the correct answer “Volvo Buses” gets a very low P(a | q) score, meaning it is unlikely to be generated. Accordingly, it wasn’t sampled after 1,000 attempts in our study. Yet the probe scores it higher than all other alternatives.
13/🧵
13/🧵
This shows that LLMs can know the answer but have practically zero chance of generating it even once, despite large-scale repeated sampling.
This highlights limitations in the generation process and opens interesting directions for future research on decoding mechanisms.
12/🧵
This highlights limitations in the generation process and opens interesting directions for future research on decoding mechanisms.
12/🧵
March 31, 2025 at 6:34 PM
This shows that LLMs can know the answer but have practically zero chance of generating it even once, despite large-scale repeated sampling.
This highlights limitations in the generation process and opens interesting directions for future research on decoding mechanisms.
12/🧵
This highlights limitations in the generation process and opens interesting directions for future research on decoding mechanisms.
12/🧵
We also discover an extreme case of hidden knowledge. When the ground-truth answer isn’t sampled after 1,000 attempts, manually adding it to the set of candidate answers leads to a substantial increase in knowledge scores.
11/🧵
11/🧵

March 31, 2025 at 6:34 PM
We also discover an extreme case of hidden knowledge. When the ground-truth answer isn’t sampled after 1,000 attempts, manually adding it to the set of candidate answers leads to a substantial increase in knowledge scores.
11/🧵
11/🧵
Our results indicate that LLMs consistently exhibit hidden knowledge, with an average relative gap of 40%.
This highlights the need to understand these differences and build models that better use their knowledge, for which our framework serves as a foundation.
10/🧵
This highlights the need to understand these differences and build models that better use their knowledge, for which our framework serves as a foundation.
10/🧵

March 31, 2025 at 6:34 PM
Our results indicate that LLMs consistently exhibit hidden knowledge, with an average relative gap of 40%.
This highlights the need to understand these differences and build models that better use their knowledge, for which our framework serves as a foundation.
10/🧵
This highlights the need to understand these differences and build models that better use their knowledge, for which our framework serves as a foundation.
10/🧵
We then compare internal and external knowledge.
Internal knowledge is measured using a linear probing classifier to score candidate answers, while external knowledge is measured using standard methods that rely on the model’s observable token-level probabilities.
9/🧵
Internal knowledge is measured using a linear probing classifier to score candidate answers, while external knowledge is measured using standard methods that rely on the model’s observable token-level probabilities.
9/🧵
March 31, 2025 at 6:34 PM
We then compare internal and external knowledge.
Internal knowledge is measured using a linear probing classifier to score candidate answers, while external knowledge is measured using standard methods that rely on the model’s observable token-level probabilities.
9/🧵
Internal knowledge is measured using a linear probing classifier to score candidate answers, while external knowledge is measured using standard methods that rely on the model’s observable token-level probabilities.
9/🧵
In our study, we estimate the set of (correct, incorrect) answer pairs per question using 1,000 model-generated answers, labeled for correctness by an LLM judge that compares each answer to the ground truth.
8/🧵
8/🧵

March 31, 2025 at 6:34 PM
In our study, we estimate the set of (correct, incorrect) answer pairs per question using 1,000 model-generated answers, labeled for correctness by an LLM judge that compares each answer to the ground truth.
8/🧵
8/🧵
We define hidden knowledge as the condition in which internal knowledge exceeds external knowledge.
7/🧵
7/🧵

March 31, 2025 at 6:34 PM
We define hidden knowledge as the condition in which internal knowledge exceeds external knowledge.
7/🧵
7/🧵
This allows us to measure internal and external knowledge using the same definition. We just use different scoring methods: external ones, that rely only on the model's observable token-level probabilities, and internal ones, that can use intermediate computations.
6/🧵
6/🧵
March 31, 2025 at 6:34 PM
This allows us to measure internal and external knowledge using the same definition. We just use different scoring methods: external ones, that rely only on the model's observable token-level probabilities, and internal ones, that can use intermediate computations.
6/🧵
6/🧵
We propose to measure knowledge relative to a function that scores answer candidates using signals from the model, and we formalize knowledge of a question as the fraction of correct-incorrect answer pairs where the correct one is scored higher.
5/🧵
5/🧵

March 31, 2025 at 6:33 PM
We propose to measure knowledge relative to a function that scores answer candidates using signals from the model, and we formalize knowledge of a question as the fraction of correct-incorrect answer pairs where the correct one is scored higher.
5/🧵
5/🧵
To define hidden knowledge, we first need a definition of “knowledge”, which is also not well defined for LLMs, as shown by @constanzafierro.bsky.social.
4/🧵
4/🧵
March 31, 2025 at 6:33 PM
To define hidden knowledge, we first need a definition of “knowledge”, which is also not well defined for LLMs, as shown by @constanzafierro.bsky.social.
4/🧵
4/🧵
Yet, despite its importance from both practical and interpretability perspectives, hidden knowledge hasn't been clearly defined and measured.
We propose such a definition, laying foundations for studying this concept, and use it in a study to demonstrate hidden knowledge.
3/🧵
We propose such a definition, laying foundations for studying this concept, and use it in a study to demonstrate hidden knowledge.
3/🧵
March 31, 2025 at 6:33 PM
Yet, despite its importance from both practical and interpretability perspectives, hidden knowledge hasn't been clearly defined and measured.
We propose such a definition, laying foundations for studying this concept, and use it in a study to demonstrate hidden knowledge.
3/🧵
We propose such a definition, laying foundations for studying this concept, and use it in a study to demonstrate hidden knowledge.
3/🧵
📜 arxiv.org/abs/2503.15299
Diverse evidence from prior work suggests the existence of hidden knowledge.
2/🧵
Diverse evidence from prior work suggests the existence of hidden knowledge.
2/🧵
Inside-Out: Hidden Factual Knowledge in LLMs
This work presents a framework for assessing whether large language models (LLMs) encode more factual knowledge in their parameters than what they express in their outputs. While a few studies hint at...
arxiv.org
March 31, 2025 at 6:33 PM
📜 arxiv.org/abs/2503.15299
Diverse evidence from prior work suggests the existence of hidden knowledge.
2/🧵
Diverse evidence from prior work suggests the existence of hidden knowledge.
2/🧵