



Yet the fact that models fail to generate known answers puts a practical constraint on scaling test-time compute via repeated sampling in closed-book QA. Significant gains remain inaccessible because we fail to sample answers that the probe would otherwise rank first.
15/🧵
15/🧵
March 31, 2025 at 6:34 PM
Yet the fact that models fail to generate known answers puts a practical constraint on scaling test-time compute via repeated sampling in closed-book QA. Significant gains remain inaccessible because we fail to sample answers that the probe would otherwise rank first.
15/🧵
15/🧵
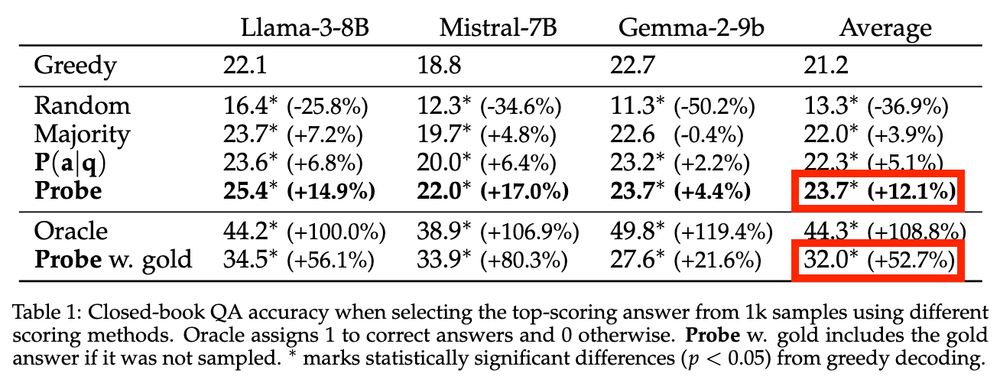
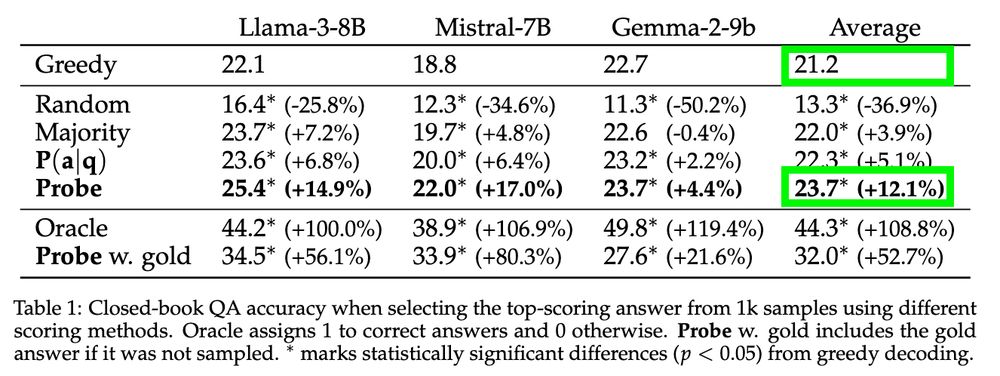
We also leverage our setup to enhance performance in a challenging closed-book QA setting, achieving a 12% average relative improvement over greedy decoding by increasing test-time compute: sampling a large set of answers and selecting the top one using our probe.
14/🧵
14/🧵
March 31, 2025 at 6:34 PM
We also leverage our setup to enhance performance in a challenging closed-book QA setting, achieving a 12% average relative improvement over greedy decoding by increasing test-time compute: sampling a large set of answers and selecting the top one using our probe.
14/🧵
14/🧵
For example, here the correct answer “Volvo Buses” gets a very low P(a | q) score, meaning it is unlikely to be generated. Accordingly, it wasn’t sampled after 1,000 attempts in our study. Yet the probe scores it higher than all other alternatives.
13/🧵
13/🧵

March 31, 2025 at 6:34 PM
For example, here the correct answer “Volvo Buses” gets a very low P(a | q) score, meaning it is unlikely to be generated. Accordingly, it wasn’t sampled after 1,000 attempts in our study. Yet the probe scores it higher than all other alternatives.
13/🧵
13/🧵
We also discover an extreme case of hidden knowledge. When the ground-truth answer isn’t sampled after 1,000 attempts, manually adding it to the set of candidate answers leads to a substantial increase in knowledge scores.
11/🧵
11/🧵

March 31, 2025 at 6:34 PM
We also discover an extreme case of hidden knowledge. When the ground-truth answer isn’t sampled after 1,000 attempts, manually adding it to the set of candidate answers leads to a substantial increase in knowledge scores.
11/🧵
11/🧵
Our results indicate that LLMs consistently exhibit hidden knowledge, with an average relative gap of 40%.
This highlights the need to understand these differences and build models that better use their knowledge, for which our framework serves as a foundation.
10/🧵
This highlights the need to understand these differences and build models that better use their knowledge, for which our framework serves as a foundation.
10/🧵

March 31, 2025 at 6:34 PM
Our results indicate that LLMs consistently exhibit hidden knowledge, with an average relative gap of 40%.
This highlights the need to understand these differences and build models that better use their knowledge, for which our framework serves as a foundation.
10/🧵
This highlights the need to understand these differences and build models that better use their knowledge, for which our framework serves as a foundation.
10/🧵
In our study, we estimate the set of (correct, incorrect) answer pairs per question using 1,000 model-generated answers, labeled for correctness by an LLM judge that compares each answer to the ground truth.
8/🧵
8/🧵

March 31, 2025 at 6:34 PM
In our study, we estimate the set of (correct, incorrect) answer pairs per question using 1,000 model-generated answers, labeled for correctness by an LLM judge that compares each answer to the ground truth.
8/🧵
8/🧵
We define hidden knowledge as the condition in which internal knowledge exceeds external knowledge.
7/🧵
7/🧵

March 31, 2025 at 6:34 PM
We define hidden knowledge as the condition in which internal knowledge exceeds external knowledge.
7/🧵
7/🧵
We propose to measure knowledge relative to a function that scores answer candidates using signals from the model, and we formalize knowledge of a question as the fraction of correct-incorrect answer pairs where the correct one is scored higher.
5/🧵
5/🧵

March 31, 2025 at 6:33 PM
We propose to measure knowledge relative to a function that scores answer candidates using signals from the model, and we formalize knowledge of a question as the fraction of correct-incorrect answer pairs where the correct one is scored higher.
5/🧵
5/🧵
🚨 It's often claimed that LLMs know more facts than they show in their outputs, but what does this actually mean, and how can we measure this “hidden knowledge”?
In our new paper, we clearly define this concept and design controlled experiments to test it.
1/🧵
In our new paper, we clearly define this concept and design controlled experiments to test it.
1/🧵

March 31, 2025 at 6:33 PM
🚨 It's often claimed that LLMs know more facts than they show in their outputs, but what does this actually mean, and how can we measure this “hidden knowledge”?
In our new paper, we clearly define this concept and design controlled experiments to test it.
1/🧵
In our new paper, we clearly define this concept and design controlled experiments to test it.
1/🧵