



Zhaofeng Wu
@zhaofengwu.bsky.social
PhD student @ MIT | Previously PYI @ AI2 | MS'21 BS'19 BA'19 @ UW | zhaofengwu.github.io
Paper: arxiv.org/abs/2503.11751
It has been a very fun project. Thanks so much to all my collaborators Michi, Andrew, Yoon, Asli, and Marjan!
It has been a very fun project. Thanks so much to all my collaborators Michi, Andrew, Yoon, Asli, and Marjan!

reWordBench: Benchmarking and Improving the Robustness of Reward Models with Transformed Inputs
Reward models have become a staple in modern NLP, serving as not only a scalable text evaluator, but also an indispensable component in many alignment recipes and inference-time algorithms. However, w...
arxiv.org
March 18, 2025 at 4:01 PM
Paper: arxiv.org/abs/2503.11751
It has been a very fun project. Thanks so much to all my collaborators Michi, Andrew, Yoon, Asli, and Marjan!
It has been a very fun project. Thanks so much to all my collaborators Michi, Andrew, Yoon, Asli, and Marjan!
💡A simple method improves robustness: including an aux loss that encourages reward similarity between paraphrases ⚖️ This generalizes to improving RM perf on diverse reWordBench transformations. More surprisingly, during alignment, regularized RMs lead to better outputs too 📈

March 18, 2025 at 4:01 PM
💡A simple method improves robustness: including an aux loss that encourages reward similarity between paraphrases ⚖️ This generalizes to improving RM perf on diverse reWordBench transformations. More surprisingly, during alignment, regularized RMs lead to better outputs too 📈
We create a benchmark 🌟reWordBench🌟 that consists of systematically transformed instances from RewardBench that maintain their semantics/ranking 🎛 On it, all top RMs on RewardBench degrade in accuracy ⏬ regardless of their size and type (classifier vs. generative)

March 18, 2025 at 4:01 PM
We create a benchmark 🌟reWordBench🌟 that consists of systematically transformed instances from RewardBench that maintain their semantics/ranking 🎛 On it, all top RMs on RewardBench degrade in accuracy ⏬ regardless of their size and type (classifier vs. generative)
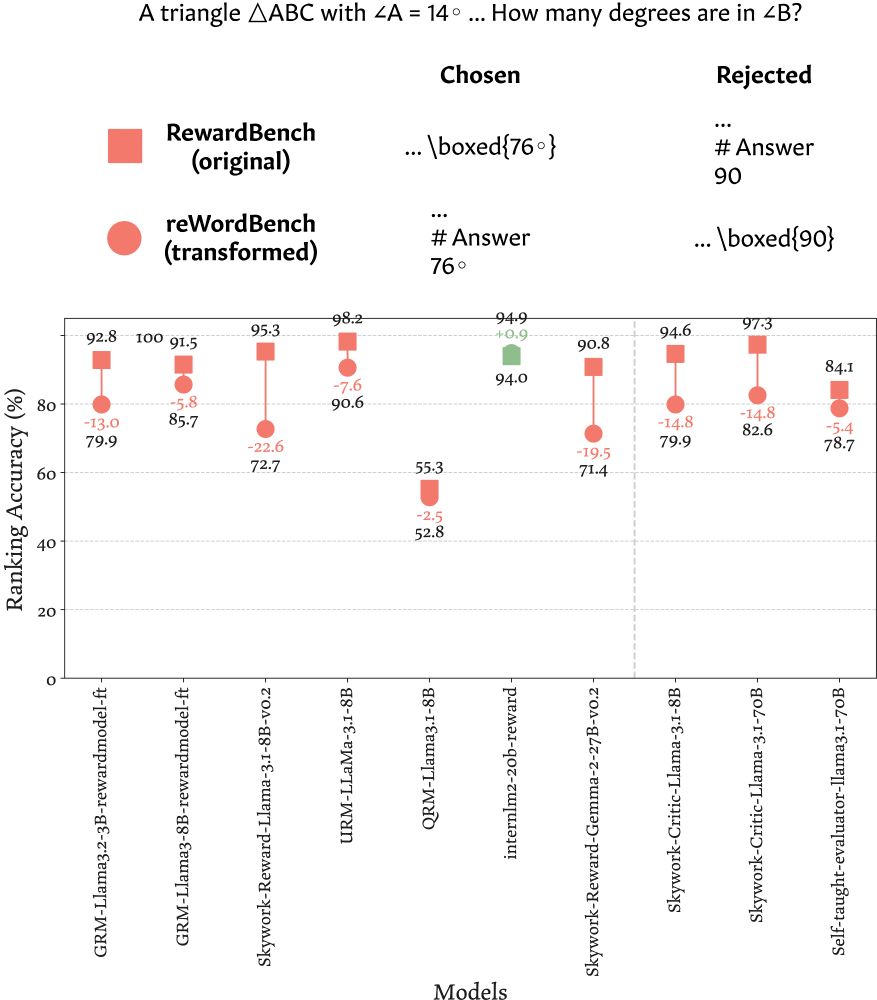
E.g., all math instances in RewardBench have an artifact: the preferred responses have the results in \boxed{} and the rejected responses put the results after a `# Answer` markdown header 💀 Flipping the format 🔄 consistently degrades SOTA RM accuracy, up to >22% 📉
March 18, 2025 at 4:01 PM
E.g., all math instances in RewardBench have an artifact: the preferred responses have the results in \boxed{} and the rejected responses put the results after a `# Answer` markdown header 💀 Flipping the format 🔄 consistently degrades SOTA RM accuracy, up to >22% 📉
We hope our observations could inspire more work on understanding 🔍 model representations & algorithms and on controlling models; eventually leading to better models.🦙
This has been a super fun project with co-authors
@velocityyu.bsky.social, Dani, Jiasen, and Yoon!
December 2, 2024 at 6:08 PM
We hope our observations could inspire more work on understanding 🔍 model representations & algorithms and on controlling models; eventually leading to better models.🦙
This has been a super fun project with co-authors
@velocityyu.bsky.social, Dani, Jiasen, and Yoon!
📍3️⃣ we can intervene in this “semantic hub” using English tokens to predictably & reliably steer 🎛️ model behavior, even with non-English/non-language inputs. This means that the “semantic hub” is not a vestigial byproduct of pretraining, but it causally affects model output.
December 2, 2024 at 6:08 PM
📍3️⃣ we can intervene in this “semantic hub” using English tokens to predictably & reliably steer 🎛️ model behavior, even with non-English/non-language inputs. This means that the “semantic hub” is not a vestigial byproduct of pretraining, but it causally affects model output.
📍2️⃣ this “semantic hub” is scaffolded by tokens in English, which allows representations of inputs from other languages/modalities to be interpreted and controlled in English (e.g. in our main figure). 📚
December 2, 2024 at 6:08 PM
📍2️⃣ this “semantic hub” is scaffolded by tokens in English, which allows representations of inputs from other languages/modalities to be interpreted and controlled in English (e.g. in our main figure). 📚
For English-centric models (analogously for others)📍1️⃣ semantically-equiv. inputs from distinct data types (e.g. English-Chinese parallel sentences; or an image & its caption) have similar repr. in intermediate transformer layers 🖇, functioning as this transmodal “semantic hub”

December 2, 2024 at 6:08 PM
For English-centric models (analogously for others)📍1️⃣ semantically-equiv. inputs from distinct data types (e.g. English-Chinese parallel sentences; or an image & its caption) have similar repr. in intermediate transformer layers 🖇, functioning as this transmodal “semantic hub”
Neuroscience studies posit that the human brain follows a “hub-and-spoke” model where a transmodal semantic “hub” integrates info. from modality-specific “spokes” regions 🕸 We hypothesize that LMs have a similar “semantic hub” that abstractly processes info. (fig from Ralph+17)

December 2, 2024 at 6:08 PM
Neuroscience studies posit that the human brain follows a “hub-and-spoke” model where a transmodal semantic “hub” integrates info. from modality-specific “spokes” regions 🕸 We hypothesize that LMs have a similar “semantic hub” that abstractly processes info. (fig from Ralph+17)
