



Zhaofeng Wu
@zhaofengwu.bsky.social
PhD student @ MIT | Previously PYI @ AI2 | MS'21 BS'19 BA'19 @ UW | zhaofengwu.github.io
Robust reward models are critical for alignment/inference-time algos, auto eval, etc. (e.g. to prevent reward hacking which could render alignment ineffective). ⚠️ But we found that SOTA RMs are brittle 🫧 and easily flip predictions when the inputs are slightly transformed 🍃 🧵

March 18, 2025 at 4:01 PM
Robust reward models are critical for alignment/inference-time algos, auto eval, etc. (e.g. to prevent reward hacking which could render alignment ineffective). ⚠️ But we found that SOTA RMs are brittle 🫧 and easily flip predictions when the inputs are slightly transformed 🍃 🧵
Reposted by Zhaofeng Wu

Like human brains, large language models reason about diverse data in a general way.
A new study shows LLMs represent different data types based on their underlying meaning & reason about data in their dominant language: bit.ly/3QrZvyy
A new study shows LLMs represent different data types based on their underlying meaning & reason about data in their dominant language: bit.ly/3QrZvyy

Like human brains, large language models reason about diverse data in a general way
MIT researchers find large language models process diverse types of data, like different languages, audio inputs, images, etc., similarly to how humans reason about complex problems. Like humans, LLMs...
bit.ly
February 19, 2025 at 10:30 PM
Like human brains, large language models reason about diverse data in a general way.
A new study shows LLMs represent different data types based on their underlying meaning & reason about data in their dominant language: bit.ly/3QrZvyy
A new study shows LLMs represent different data types based on their underlying meaning & reason about data in their dominant language: bit.ly/3QrZvyy
To appear @ #ICLR2025! We show that LMs represent semantically-equivalent inputs across languages, modalities, etc. similarly. This shared representation space is structured by the LM's dominant language, which is also relevant to recent phenomena where LMs "think" in Chinese🀄️ in English🔠 contexts
💡We find that models “think” 💭 in English (or in general, their dominant language) when processing distinct non-English or even non-language data types 🤯 like texts in other languages, arithmetic expressions, code, visual inputs, & audio inputs‼️ 🧵⬇️ arxiv.org/abs/2411.04986

January 22, 2025 at 6:10 PM
To appear @ #ICLR2025! We show that LMs represent semantically-equivalent inputs across languages, modalities, etc. similarly. This shared representation space is structured by the LM's dominant language, which is also relevant to recent phenomena where LMs "think" in Chinese🀄️ in English🔠 contexts
We have released our code at github.com/ZhaofengWu/s.... We hope that this could be useful for future studies understanding the how LMs work!
💡We find that models “think” 💭 in English (or in general, their dominant language) when processing distinct non-English or even non-language data types 🤯 like texts in other languages, arithmetic expressions, code, visual inputs, & audio inputs‼️ 🧵⬇️ arxiv.org/abs/2411.04986
December 17, 2024 at 3:26 PM
We have released our code at github.com/ZhaofengWu/s.... We hope that this could be useful for future studies understanding the how LMs work!
Reposted by Zhaofeng Wu

excited to be at #NeurIPS2024! I'll be presenting our data mixture inference attack 🗓️ Thu 4:30pm w/ @jon.jon.ke — stop by to learn what trained tokenizers reveal about LLM development (‼️) and chat about all things tokenizers.
🔗 arxiv.org/abs/2407.16607
🔗 arxiv.org/abs/2407.16607

December 11, 2024 at 10:08 PM
excited to be at #NeurIPS2024! I'll be presenting our data mixture inference attack 🗓️ Thu 4:30pm w/ @jon.jon.ke — stop by to learn what trained tokenizers reveal about LLM development (‼️) and chat about all things tokenizers.
🔗 arxiv.org/abs/2407.16607
🔗 arxiv.org/abs/2407.16607
Reposted by Zhaofeng Wu

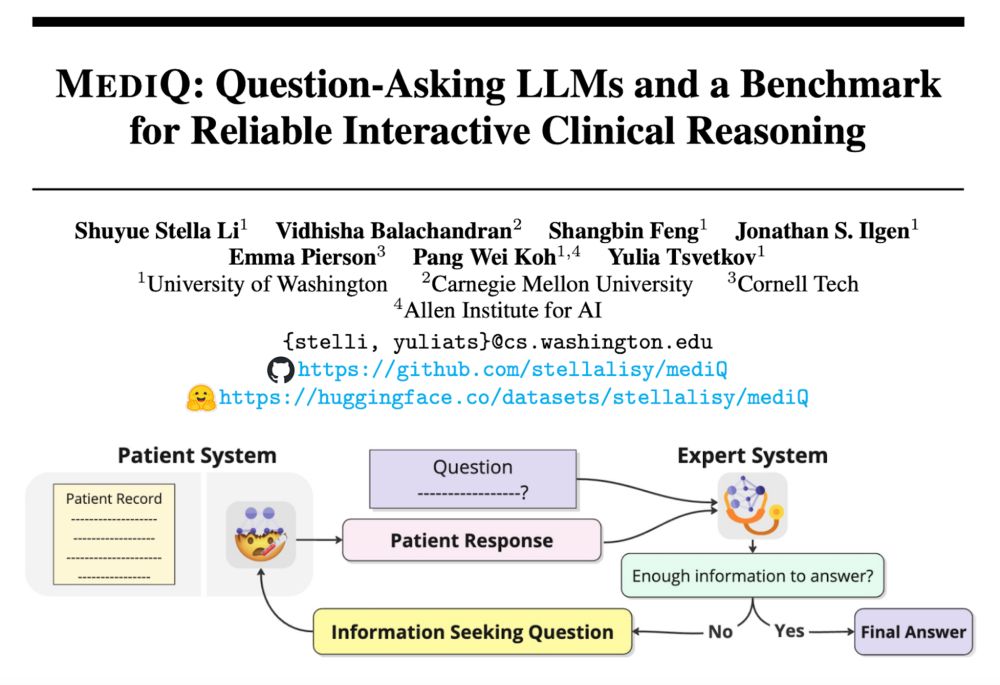
31% of US adults use generative AI for healthcare 🤯But most AI systems answer questions assertively—even when they don’t have the necessary context. Introducing #MediQ a framework that enables LLMs to recognize uncertainty🤔and ask the right questions❓when info is missing: 🧵
December 6, 2024 at 10:51 PM
31% of US adults use generative AI for healthcare 🤯But most AI systems answer questions assertively—even when they don’t have the necessary context. Introducing #MediQ a framework that enables LLMs to recognize uncertainty🤔and ask the right questions❓when info is missing: 🧵
💡We find that models “think” 💭 in English (or in general, their dominant language) when processing distinct non-English or even non-language data types 🤯 like texts in other languages, arithmetic expressions, code, visual inputs, & audio inputs‼️ 🧵⬇️ arxiv.org/abs/2411.04986
December 2, 2024 at 6:08 PM
💡We find that models “think” 💭 in English (or in general, their dominant language) when processing distinct non-English or even non-language data types 🤯 like texts in other languages, arithmetic expressions, code, visual inputs, & audio inputs‼️ 🧵⬇️ arxiv.org/abs/2411.04986
Reposted by Zhaofeng Wu

🚨New dataset + challenge🚨
We release ASL STEM Wiki: the first signing dataset of STEM articles!
📰 254 Wikipedia articles
📹 ~300 hours of ASL interpretations
👋 New task: automatic sign suggestion to make STEM education more accessible
microsoft.com/en-us/resear...
🧵 #EMNLP2024
We release ASL STEM Wiki: the first signing dataset of STEM articles!
📰 254 Wikipedia articles
📹 ~300 hours of ASL interpretations
👋 New task: automatic sign suggestion to make STEM education more accessible
microsoft.com/en-us/resear...
🧵 #EMNLP2024
November 19, 2024 at 12:19 AM
🚨New dataset + challenge🚨
We release ASL STEM Wiki: the first signing dataset of STEM articles!
📰 254 Wikipedia articles
📹 ~300 hours of ASL interpretations
👋 New task: automatic sign suggestion to make STEM education more accessible
microsoft.com/en-us/resear...
🧵 #EMNLP2024
We release ASL STEM Wiki: the first signing dataset of STEM articles!
📰 254 Wikipedia articles
📹 ~300 hours of ASL interpretations
👋 New task: automatic sign suggestion to make STEM education more accessible
microsoft.com/en-us/resear...
🧵 #EMNLP2024