



Zeta Alpha
@zeta-alpha.bsky.social
Zeta Alpha: A smarter way to discover and organize knowledge in AI and beyond. R&D in Neural Search. Papers and Trends in AI. Enjoy Discovery!
Our new release allows your teams to not only create and schedule, but also to share powerful enterprise-ready AI Agents that connect securely to your internal knowledge, public research, and the web. Zeta Alpha empowers your teams to achieve more together, and faster.
November 26, 2025 at 10:09 AM
Our new release allows your teams to not only create and schedule, but also to share powerful enterprise-ready AI Agents that connect securely to your internal knowledge, public research, and the web. Zeta Alpha empowers your teams to achieve more together, and faster.
Zeta Alpha launches custom AI agents built for knowledge-intensive enterprise teams. Easily create, share, schedule and manage your own AI agents that get real work done.
November 26, 2025 at 10:09 AM
Zeta Alpha launches custom AI agents built for knowledge-intensive enterprise teams. Easily create, share, schedule and manage your own AI agents that get real work done.
Join us this Friday, October 10th at 8 AM PST / 5 PM CEST for a special episode of our “Trends in AI” show, with a focus on Enterprise AI Safety.

October 6, 2025 at 4:17 PM
Join us this Friday, October 10th at 8 AM PST / 5 PM CEST for a special episode of our “Trends in AI” show, with a focus on Enterprise AI Safety.
Performance
✦ SOTA on MTEB multilingual/English/code
✦ Minimal int8/int4 quantization degradation
✦ Graceful drop from 768d to 128d, still leading its class
✦ Cross-lingual: beats many larger open & API models
✦ SOTA on MTEB multilingual/English/code
✦ Minimal int8/int4 quantization degradation
✦ Graceful drop from 768d to 128d, still leading its class
✦ Cross-lingual: beats many larger open & API models

September 26, 2025 at 12:19 PM
Performance
✦ SOTA on MTEB multilingual/English/code
✦ Minimal int8/int4 quantization degradation
✦ Graceful drop from 768d to 128d, still leading its class
✦ Cross-lingual: beats many larger open & API models
✦ SOTA on MTEB multilingual/English/code
✦ Minimal int8/int4 quantization degradation
✦ Graceful drop from 768d to 128d, still leading its class
✦ Cross-lingual: beats many larger open & API models
Tricks
✦ "Spread-out" regularizer for quantization robustness
✦ Model souping across diverse data mixtures
✦ Quantization-aware training & MRL during finetuning
✦ "Spread-out" regularizer for quantization robustness
✦ Model souping across diverse data mixtures
✦ Quantization-aware training & MRL during finetuning



September 26, 2025 at 12:19 PM
Tricks
✦ "Spread-out" regularizer for quantization robustness
✦ Model souping across diverse data mixtures
✦ Quantization-aware training & MRL during finetuning
✦ "Spread-out" regularizer for quantization robustness
✦ Model souping across diverse data mixtures
✦ Quantization-aware training & MRL during finetuning
Training / Architecture
✦ Turn Gemma 3 into an encoder-decoder LLM using the UL2 objective (like GemmaT5)
✦ Keep the encoder, pre-finetune it on a large unsupervised dataset, then finetune on retrieval datasets with hard negatives
✦ Embedding distillation from Gemini Embedding
✦ Turn Gemma 3 into an encoder-decoder LLM using the UL2 objective (like GemmaT5)
✦ Keep the encoder, pre-finetune it on a large unsupervised dataset, then finetune on retrieval datasets with hard negatives
✦ Embedding distillation from Gemini Embedding

September 26, 2025 at 12:19 PM
Training / Architecture
✦ Turn Gemma 3 into an encoder-decoder LLM using the UL2 objective (like GemmaT5)
✦ Keep the encoder, pre-finetune it on a large unsupervised dataset, then finetune on retrieval datasets with hard negatives
✦ Embedding distillation from Gemini Embedding
✦ Turn Gemma 3 into an encoder-decoder LLM using the UL2 objective (like GemmaT5)
✦ Keep the encoder, pre-finetune it on a large unsupervised dataset, then finetune on retrieval datasets with hard negatives
✦ Embedding distillation from Gemini Embedding
What is EmbeddingGemma?
✦ 300M parameter text embedding model
✦ derived from Gemma 3
✦ SOTA on multilingual, English & code retrieval tasks
✦ matching performance of models 2x its size
✦ supports dimensionality reduction
✦ comes with quantization-aware checkpoints
✦ 300M parameter text embedding model
✦ derived from Gemma 3
✦ SOTA on multilingual, English & code retrieval tasks
✦ matching performance of models 2x its size
✦ supports dimensionality reduction
✦ comes with quantization-aware checkpoints
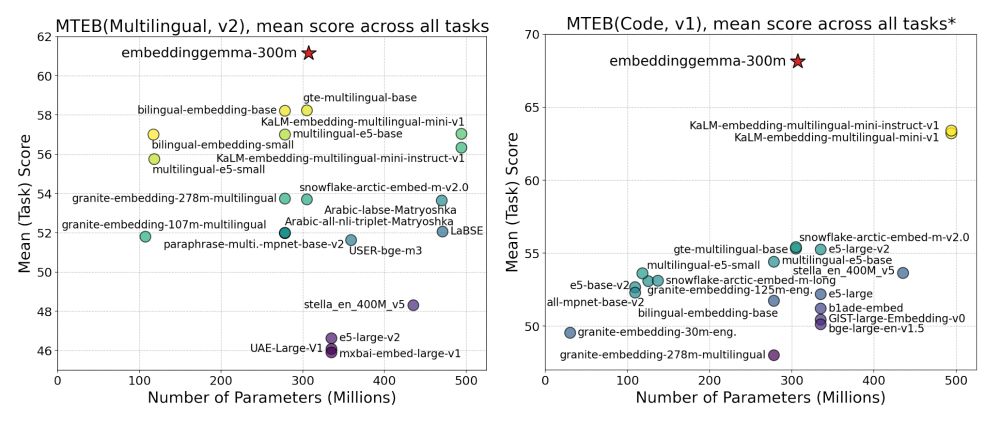
September 26, 2025 at 12:19 PM
What is EmbeddingGemma?
✦ 300M parameter text embedding model
✦ derived from Gemma 3
✦ SOTA on multilingual, English & code retrieval tasks
✦ matching performance of models 2x its size
✦ supports dimensionality reduction
✦ comes with quantization-aware checkpoints
✦ 300M parameter text embedding model
✦ derived from Gemma 3
✦ SOTA on multilingual, English & code retrieval tasks
✦ matching performance of models 2x its size
✦ supports dimensionality reduction
✦ comes with quantization-aware checkpoints
DeepMind just dropped the technical report behind their SOTA open-weights embedding model, packed with training details, including ablations on modeling choices like encoder-decoder initialization, mean pooling, and model souping. Let's take a look! 📚

September 26, 2025 at 12:19 PM
DeepMind just dropped the technical report behind their SOTA open-weights embedding model, packed with training details, including ablations on modeling choices like encoder-decoder initialization, mean pooling, and model souping. Let's take a look! 📚
Join us for a special episode of our "Trends in AI" show on Friday, September 12th at 8 AM PST / 5 PM CEST, focused on Enterprise RAG. Secure your spot at: lu.ma/trends-in-ai...

September 8, 2025 at 3:13 PM
Join us for a special episode of our "Trends in AI" show on Friday, September 12th at 8 AM PST / 5 PM CEST, focused on Enterprise RAG. Secure your spot at: lu.ma/trends-in-ai...
AI agents are only as useful as the tools they can reliably access, and the latest release of our Agents SDK makes it easy to connect to MCP servers.
We've prepared a quick guide where we bootstrap a minimal MCP-powered chat agent with just a few lines of code:
www.zeta-alpha.com/post/build-m...
We've prepared a quick guide where we bootstrap a minimal MCP-powered chat agent with just a few lines of code:
www.zeta-alpha.com/post/build-m...

August 8, 2025 at 2:13 PM
AI agents are only as useful as the tools they can reliably access, and the latest release of our Agents SDK makes it easy to connect to MCP servers.
We've prepared a quick guide where we bootstrap a minimal MCP-powered chat agent with just a few lines of code:
www.zeta-alpha.com/post/build-m...
We've prepared a quick guide where we bootstrap a minimal MCP-powered chat agent with just a few lines of code:
www.zeta-alpha.com/post/build-m...
Join us for the Zeta Alpha "Trends in AI" show on Friday, July 11th at 8 AM PST / 5 PM CEST live from LAB42 in Amsterdam, and online in San Francisco and around the globe.
Register to receive your Zoom webinar invitation, or watch our live stream on YouTube and LinkedIn: lu.ma/trends-in-ai...
Register to receive your Zoom webinar invitation, or watch our live stream on YouTube and LinkedIn: lu.ma/trends-in-ai...

July 9, 2025 at 9:11 AM
Join us for the Zeta Alpha "Trends in AI" show on Friday, July 11th at 8 AM PST / 5 PM CEST live from LAB42 in Amsterdam, and online in San Francisco and around the globe.
Register to receive your Zoom webinar invitation, or watch our live stream on YouTube and LinkedIn: lu.ma/trends-in-ai...
Register to receive your Zoom webinar invitation, or watch our live stream on YouTube and LinkedIn: lu.ma/trends-in-ai...
Catch us live today at 8 AM PST / 5 PM CEST for our monthly Trends in AI webinar - diving into AI evaluations, LLM benchmarking, relevance metrics for RAG, popular eval libraries, and the quirks of LLM-as-a-Judge for automated & continuous assessment of AI systems' performance.
lu.ma/trends-in-ai...
lu.ma/trends-in-ai...

May 9, 2025 at 12:00 PM
Catch us live today at 8 AM PST / 5 PM CEST for our monthly Trends in AI webinar - diving into AI evaluations, LLM benchmarking, relevance metrics for RAG, popular eval libraries, and the quirks of LLM-as-a-Judge for automated & continuous assessment of AI systems' performance.
lu.ma/trends-in-ai...
lu.ma/trends-in-ai...
Join us for the Zeta Alpha "Trends in AI" webinar on Friday, May 9th at 8 AM PST / 5 PM CEST, live from LAB42 in Amsterdam, and online from San Francisco and around the globe.
Register on Luma to receive your webinar invitation, or watch our live stream on YouTube & LinkedIn:
lu.ma/trends-in-ai...
Register on Luma to receive your webinar invitation, or watch our live stream on YouTube & LinkedIn:
lu.ma/trends-in-ai...
May 2, 2025 at 8:43 AM
Join us for the Zeta Alpha "Trends in AI" webinar on Friday, May 9th at 8 AM PST / 5 PM CEST, live from LAB42 in Amsterdam, and online from San Francisco and around the globe.
Register on Luma to receive your webinar invitation, or watch our live stream on YouTube & LinkedIn:
lu.ma/trends-in-ai...
Register on Luma to receive your webinar invitation, or watch our live stream on YouTube & LinkedIn:
lu.ma/trends-in-ai...
Are you attending #OpenSearchCon Europe 2025?
Don't miss out on our two talks today!
• RAG from Text & Images Using OpenSearch and Vision Language Models @ 14:55 - sched.co/1uxsf
• How to Search 1 Billion Vectors in OpenSearch Without Losing Your Mind or Wallet @ 16:35 - sched.co/1uxsu
Don't miss out on our two talks today!
• RAG from Text & Images Using OpenSearch and Vision Language Models @ 14:55 - sched.co/1uxsf
• How to Search 1 Billion Vectors in OpenSearch Without Losing Your Mind or Wallet @ 16:35 - sched.co/1uxsu


May 1, 2025 at 7:55 AM
Are you attending #OpenSearchCon Europe 2025?
Don't miss out on our two talks today!
• RAG from Text & Images Using OpenSearch and Vision Language Models @ 14:55 - sched.co/1uxsf
• How to Search 1 Billion Vectors in OpenSearch Without Losing Your Mind or Wallet @ 16:35 - sched.co/1uxsu
Don't miss out on our two talks today!
• RAG from Text & Images Using OpenSearch and Vision Language Models @ 14:55 - sched.co/1uxsf
• How to Search 1 Billion Vectors in OpenSearch Without Losing Your Mind or Wallet @ 16:35 - sched.co/1uxsu
How To Search 1 Billion Vectors in OpenSearch Without Losing Your Mind or Wallet (Fernando Rejon Barrera)
Scaling vector search to a billion vectors is a high-stakes balancing act. Lessons learnt from building such a system in OpenSearch, covering aspects like model selection & hardware essentials.
Scaling vector search to a billion vectors is a high-stakes balancing act. Lessons learnt from building such a system in OpenSearch, covering aspects like model selection & hardware essentials.
April 24, 2025 at 3:39 PM
How To Search 1 Billion Vectors in OpenSearch Without Losing Your Mind or Wallet (Fernando Rejon Barrera)
Scaling vector search to a billion vectors is a high-stakes balancing act. Lessons learnt from building such a system in OpenSearch, covering aspects like model selection & hardware essentials.
Scaling vector search to a billion vectors is a high-stakes balancing act. Lessons learnt from building such a system in OpenSearch, covering aspects like model selection & hardware essentials.
RAG From Text & Images Using OpenSearch and Vision Language Models (Jakub Zavrel, Batu Helvacıoğlu)
Learn how to incorporate Vision Language Models in a multimodal RAG pipeline with approaches like ColPali, enabling unprecedented accuracy for RAG on visually complex documents and presentations.
Learn how to incorporate Vision Language Models in a multimodal RAG pipeline with approaches like ColPali, enabling unprecedented accuracy for RAG on visually complex documents and presentations.
April 24, 2025 at 3:39 PM
RAG From Text & Images Using OpenSearch and Vision Language Models (Jakub Zavrel, Batu Helvacıoğlu)
Learn how to incorporate Vision Language Models in a multimodal RAG pipeline with approaches like ColPali, enabling unprecedented accuracy for RAG on visually complex documents and presentations.
Learn how to incorporate Vision Language Models in a multimodal RAG pipeline with approaches like ColPali, enabling unprecedented accuracy for RAG on visually complex documents and presentations.
This month, we're exploring how AI is transforming engineering, industrial tech, and R&D. Expect deep dives into how LLMs, Agents, RAG, and GenAI are being applied in fields like manufacturing and industrial automation plus the usual mix of trending papers, cutting-edge models, and open-source gems.

April 1, 2025 at 4:03 PM
This month, we're exploring how AI is transforming engineering, industrial tech, and R&D. Expect deep dives into how LLMs, Agents, RAG, and GenAI are being applied in fields like manufacturing and industrial automation plus the usual mix of trending papers, cutting-edge models, and open-source gems.
Dewey achieves impressive performance, ranking competitively among much larger models on MTEB English (v2) despite being zero-shot. Additionally, its multi-vector variant sets a new state-of-the-art on challenging long-document benchmarks like LongEmbed and LoCoV1.

March 27, 2025 at 5:32 PM
Dewey achieves impressive performance, ranking competitively among much larger models on MTEB English (v2) despite being zero-shot. Additionally, its multi-vector variant sets a new state-of-the-art on challenging long-document benchmarks like LongEmbed and LoCoV1.
Dewey is trained with two non-contrastive losses, designed to align the representation space of the student model using the teacher's embeddings. The training data contain ~10M documents (~100M chunks total), sourced from 2 unsupervised datasets (Infinity-Instruct & FineWeb-Edu).

March 27, 2025 at 5:32 PM
Dewey is trained with two non-contrastive losses, designed to align the representation space of the student model using the teacher's embeddings. The training data contain ~10M documents (~100M chunks total), sourced from 2 unsupervised datasets (Infinity-Instruct & FineWeb-Edu).
At the core of Dewey is a new distillation technique called chunk alignment training, generating:
- A global [CLS] embedding for the entire document.
- Individual chunk embeddings through mean-pooling.
- A unified embedding from averaging all token embeddings across chunks.
- A global [CLS] embedding for the entire document.
- Individual chunk embeddings through mean-pooling.
- A unified embedding from averaging all token embeddings across chunks.

March 27, 2025 at 5:32 PM
At the core of Dewey is a new distillation technique called chunk alignment training, generating:
- A global [CLS] embedding for the entire document.
- Individual chunk embeddings through mean-pooling.
- A unified embedding from averaging all token embeddings across chunks.
- A global [CLS] embedding for the entire document.
- Individual chunk embeddings through mean-pooling.
- A unified embedding from averaging all token embeddings across chunks.
The creators of Stella and Jasper continue their impressive work on embedding models, now releasing Dewey - a model designed for long-document retrieval tasks. Let's have a look at the key findings from their freshly published technical report: 📄

March 27, 2025 at 5:32 PM
The creators of Stella and Jasper continue their impressive work on embedding models, now releasing Dewey - a model designed for long-document retrieval tasks. Let's have a look at the key findings from their freshly published technical report: 📄

3. Synthetic data generation is useful for classification.
4. Filtering retrieval datasets improves multilingual retrieval.
5. Including hard negatives is beneficial, yet adding more beyond a certain point offers diminishing returns.
4. Filtering retrieval datasets improves multilingual retrieval.
5. Including hard negatives is beneficial, yet adding more beyond a certain point offers diminishing returns.

March 20, 2025 at 11:22 AM
3. Synthetic data generation is useful for classification.
4. Filtering retrieval datasets improves multilingual retrieval.
5. Including hard negatives is beneficial, yet adding more beyond a certain point offers diminishing returns.
4. Filtering retrieval datasets improves multilingual retrieval.
5. Including hard negatives is beneficial, yet adding more beyond a certain point offers diminishing returns.
The ablations provide additional insights, showing that:
1. English-only training already exhibits both strong multilingual and cross-lingual retrieval performance.
2. Multi-lingual fine-tuning improves performance on long-tail languages in XTREME-UP.
1. English-only training already exhibits both strong multilingual and cross-lingual retrieval performance.
2. Multi-lingual fine-tuning improves performance on long-tail languages in XTREME-UP.

March 20, 2025 at 11:22 AM
The ablations provide additional insights, showing that:
1. English-only training already exhibits both strong multilingual and cross-lingual retrieval performance.
2. Multi-lingual fine-tuning improves performance on long-tail languages in XTREME-UP.
1. English-only training already exhibits both strong multilingual and cross-lingual retrieval performance.
2. Multi-lingual fine-tuning improves performance on long-tail languages in XTREME-UP.
The empirical results are highly impressive. Gemini Embedding not only tops the MTEB leaderboard for English, multilingual, and code retrieval tasks, but it also demonstrates strong capabilities in cross-lingual retrieval such as in XTREME-UP and XOR-Retrieval.


March 20, 2025 at 11:22 AM
The empirical results are highly impressive. Gemini Embedding not only tops the MTEB leaderboard for English, multilingual, and code retrieval tasks, but it also demonstrates strong capabilities in cross-lingual retrieval such as in XTREME-UP and XOR-Retrieval.