



Zeta Alpha
@zeta-alpha.bsky.social
Zeta Alpha: A smarter way to discover and organize knowledge in AI and beyond. R&D in Neural Search. Papers and Trends in AI. Enjoy Discovery!
Check out the release notes via the Zeta Alpha blog.
www.zeta-alpha.com/post/zeta-al...
Enjoy Discovery!
www.zeta-alpha.com/post/zeta-al...
Enjoy Discovery!
November 26, 2025 at 10:09 AM
Check out the release notes via the Zeta Alpha blog.
www.zeta-alpha.com/post/zeta-al...
Enjoy Discovery!
www.zeta-alpha.com/post/zeta-al...
Enjoy Discovery!
Our new release allows your teams to not only create and schedule, but also to share powerful enterprise-ready AI Agents that connect securely to your internal knowledge, public research, and the web. Zeta Alpha empowers your teams to achieve more together, and faster.
November 26, 2025 at 10:09 AM
Our new release allows your teams to not only create and schedule, but also to share powerful enterprise-ready AI Agents that connect securely to your internal knowledge, public research, and the web. Zeta Alpha empowers your teams to achieve more together, and faster.
The great thing with AI agents is that they can do work in the background while you are busy doing something else, which is why we have built controls so that you are able to schedule them and they send you a notification when they are done.
November 26, 2025 at 10:09 AM
The great thing with AI agents is that they can do work in the background while you are busy doing something else, which is why we have built controls so that you are able to schedule them and they send you a notification when they are done.
Everyone is experimenting with AI Agents, but few are able to show real success yet. One of the main reasons is that AI Agents need a secure connection to your company’s internal and external knowledge sources, and that’s exactly where Zeta Alpha comes in.
November 26, 2025 at 10:09 AM
Everyone is experimenting with AI Agents, but few are able to show real success yet. One of the main reasons is that AI Agents need a secure connection to your company’s internal and external knowledge sources, and that’s exactly where Zeta Alpha comes in.
We'll cover how AI agents are accelerating research today, how close LLMs are to exploring new scientific ideas, and how they can support researchers’ knowledge work. As always, we'll round it out with the latest news in AI R&D, open-source releases, and the most trending papers of the month!
November 19, 2025 at 1:34 PM
We'll cover how AI agents are accelerating research today, how close LLMs are to exploring new scientific ideas, and how they can support researchers’ knowledge work. As always, we'll round it out with the latest news in AI R&D, open-source releases, and the most trending papers of the month!
Reposted by Zeta Alpha

Good advice. Don’t select AI vendors based on capital raised, news headlines or Gigawatts of compute, but on ability to partner and to deliver.

November 10, 2025 at 1:44 PM
Good advice. Don’t select AI vendors based on capital raised, news headlines or Gigawatts of compute, but on ability to partner and to deliver.
Reposted by Zeta Alpha
The most interesting takeaway from the keynote? 84% of IT leaders don’t track accuracy. How can you govern and improve something that you don’t measure.

November 10, 2025 at 1:40 PM
The most interesting takeaway from the keynote? 84% of IT leaders don’t track accuracy. How can you govern and improve something that you don’t measure.
Reposted by Zeta Alpha
Also cool: Context Engineering, the fastest hype cycle rise from Andrej Karpathy tweet to Gartner CIO strategy advisory in less than 5 months. (With due credit for Tobi Lutke)

November 10, 2025 at 1:48 PM
Also cool: Context Engineering, the fastest hype cycle rise from Andrej Karpathy tweet to Gartner CIO strategy advisory in less than 5 months. (With due credit for Tobi Lutke)
And as always, expect the freshest AI R&D news, the best open-source releases, and the most trending research papers of the month. Don’t miss it!
👉 lu.ma/trends-in-ai...
👉 lu.ma/trends-in-ai...

Trends in AI by Zeta Alpha - October 2025 · Zoom · Luma
Join us for the Zeta Alpha Trends in AI webinar on Friday, October 10th, at 8 AM PST / 5 PM CEST. The event is in person in Amsterdam (LAB42, Science Park),…
lu.ma
October 6, 2025 at 4:17 PM
And as always, expect the freshest AI R&D news, the best open-source releases, and the most trending research papers of the month. Don’t miss it!
👉 lu.ma/trends-in-ai...
👉 lu.ma/trends-in-ai...
We will dive into:
🔒 Secure AI infrastructure & data sovereignty
🧱 Guardrails & moderation for LLM outputs
💥 Jailbreaks & prompt injections in the wild
📜 Regulation like SB 53 and ISO 42001 compliance
🧠 Information integrity & the “AI workslop” productivity killer
🔒 Secure AI infrastructure & data sovereignty
🧱 Guardrails & moderation for LLM outputs
💥 Jailbreaks & prompt injections in the wild
📜 Regulation like SB 53 and ISO 42001 compliance
🧠 Information integrity & the “AI workslop” productivity killer
October 6, 2025 at 4:17 PM
We will dive into:
🔒 Secure AI infrastructure & data sovereignty
🧱 Guardrails & moderation for LLM outputs
💥 Jailbreaks & prompt injections in the wild
📜 Regulation like SB 53 and ISO 42001 compliance
🧠 Information integrity & the “AI workslop” productivity killer
🔒 Secure AI infrastructure & data sovereignty
🧱 Guardrails & moderation for LLM outputs
💥 Jailbreaks & prompt injections in the wild
📜 Regulation like SB 53 and ISO 42001 compliance
🧠 Information integrity & the “AI workslop” productivity killer
Check out the full EmbeddingGemma paper on Zeta Alpha, where you can easily explore more related work using the "Find similar" functionality. Until next time, enjoy discovery!
search.zeta-alpha.com/documents/4b...
search.zeta-alpha.com/documents/4b...

Zeta Alpha - AI Research Navigator
The Zeta Alpha Neural Discovery Platform is a smarter way to discover and organize knowledge in AI and beyond, using Generative LLMs and advanced Neural Search.
search.zeta-alpha.com
September 26, 2025 at 12:19 PM
Check out the full EmbeddingGemma paper on Zeta Alpha, where you can easily explore more related work using the "Find similar" functionality. Until next time, enjoy discovery!
search.zeta-alpha.com/documents/4b...
search.zeta-alpha.com/documents/4b...
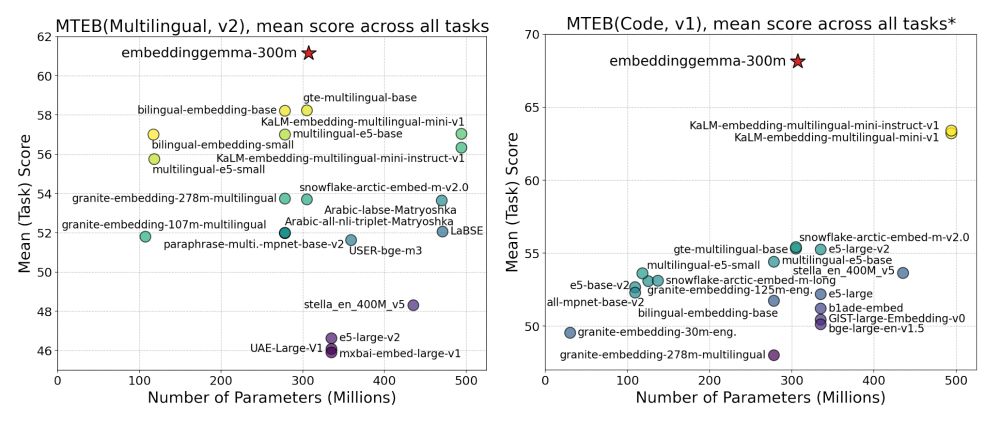
Performance
✦ SOTA on MTEB multilingual/English/code
✦ Minimal int8/int4 quantization degradation
✦ Graceful drop from 768d to 128d, still leading its class
✦ Cross-lingual: beats many larger open & API models
✦ SOTA on MTEB multilingual/English/code
✦ Minimal int8/int4 quantization degradation
✦ Graceful drop from 768d to 128d, still leading its class
✦ Cross-lingual: beats many larger open & API models

September 26, 2025 at 12:19 PM
Performance
✦ SOTA on MTEB multilingual/English/code
✦ Minimal int8/int4 quantization degradation
✦ Graceful drop from 768d to 128d, still leading its class
✦ Cross-lingual: beats many larger open & API models
✦ SOTA on MTEB multilingual/English/code
✦ Minimal int8/int4 quantization degradation
✦ Graceful drop from 768d to 128d, still leading its class
✦ Cross-lingual: beats many larger open & API models
Tricks
✦ "Spread-out" regularizer for quantization robustness
✦ Model souping across diverse data mixtures
✦ Quantization-aware training & MRL during finetuning
✦ "Spread-out" regularizer for quantization robustness
✦ Model souping across diverse data mixtures
✦ Quantization-aware training & MRL during finetuning



September 26, 2025 at 12:19 PM
Tricks
✦ "Spread-out" regularizer for quantization robustness
✦ Model souping across diverse data mixtures
✦ Quantization-aware training & MRL during finetuning
✦ "Spread-out" regularizer for quantization robustness
✦ Model souping across diverse data mixtures
✦ Quantization-aware training & MRL during finetuning
Training / Architecture
✦ Turn Gemma 3 into an encoder-decoder LLM using the UL2 objective (like GemmaT5)
✦ Keep the encoder, pre-finetune it on a large unsupervised dataset, then finetune on retrieval datasets with hard negatives
✦ Embedding distillation from Gemini Embedding
✦ Turn Gemma 3 into an encoder-decoder LLM using the UL2 objective (like GemmaT5)
✦ Keep the encoder, pre-finetune it on a large unsupervised dataset, then finetune on retrieval datasets with hard negatives
✦ Embedding distillation from Gemini Embedding

September 26, 2025 at 12:19 PM
Training / Architecture
✦ Turn Gemma 3 into an encoder-decoder LLM using the UL2 objective (like GemmaT5)
✦ Keep the encoder, pre-finetune it on a large unsupervised dataset, then finetune on retrieval datasets with hard negatives
✦ Embedding distillation from Gemini Embedding
✦ Turn Gemma 3 into an encoder-decoder LLM using the UL2 objective (like GemmaT5)
✦ Keep the encoder, pre-finetune it on a large unsupervised dataset, then finetune on retrieval datasets with hard negatives
✦ Embedding distillation from Gemini Embedding
What is EmbeddingGemma?
✦ 300M parameter text embedding model
✦ derived from Gemma 3
✦ SOTA on multilingual, English & code retrieval tasks
✦ matching performance of models 2x its size
✦ supports dimensionality reduction
✦ comes with quantization-aware checkpoints
✦ 300M parameter text embedding model
✦ derived from Gemma 3
✦ SOTA on multilingual, English & code retrieval tasks
✦ matching performance of models 2x its size
✦ supports dimensionality reduction
✦ comes with quantization-aware checkpoints
September 26, 2025 at 12:19 PM
What is EmbeddingGemma?
✦ 300M parameter text embedding model
✦ derived from Gemma 3
✦ SOTA on multilingual, English & code retrieval tasks
✦ matching performance of models 2x its size
✦ supports dimensionality reduction
✦ comes with quantization-aware checkpoints
✦ 300M parameter text embedding model
✦ derived from Gemma 3
✦ SOTA on multilingual, English & code retrieval tasks
✦ matching performance of models 2x its size
✦ supports dimensionality reduction
✦ comes with quantization-aware checkpoints