



Yuhang Zang
@yuhangzang.bsky.social
Researcher at Shanghai AI Laboratory. Previous PhD at Nanyang Technological University. Working on open-world perception and reasoning.
Reposted by Yuhang Zang

Will you be at #NeurIPS2025? Come talk TMLR and collect swag!
EiCs Gautam Kamath (@gautamkamath.com) and Nihar Shah will be there -- if you are an AE or an Expert Reviewer, or have a Featured or Outstanding Certification, you can get a free TMLR laptop sticker! Locations ⬇️
EiCs Gautam Kamath (@gautamkamath.com) and Nihar Shah will be there -- if you are an AE or an Expert Reviewer, or have a Featured or Outstanding Certification, you can get a free TMLR laptop sticker! Locations ⬇️

November 27, 2025 at 5:16 PM
Will you be at #NeurIPS2025? Come talk TMLR and collect swag!
EiCs Gautam Kamath (@gautamkamath.com) and Nihar Shah will be there -- if you are an AE or an Expert Reviewer, or have a Featured or Outstanding Certification, you can get a free TMLR laptop sticker! Locations ⬇️
EiCs Gautam Kamath (@gautamkamath.com) and Nihar Shah will be there -- if you are an AE or an Expert Reviewer, or have a Featured or Outstanding Certification, you can get a free TMLR laptop sticker! Locations ⬇️
Reposted by Yuhang Zang


Reposted by Yuhang Zang
Our discussion period just started. Authors, please read our instructions carefully. We require responses by June 2.
But, what you really want to hear about is stats .... right? -> 🧵
But, what you really want to hear about is stats .... right? -> 🧵

May 27, 2025 at 5:41 PM
Our discussion period just started. Authors, please read our instructions carefully. We require responses by June 2.
But, what you really want to hear about is stats .... right? -> 🧵
But, what you really want to hear about is stats .... right? -> 🧵
Reposted by Yuhang Zang

o3’s weird hallucinations could indicate they used llm as a judge (or other softer verifiers) in high volume and in addition to math/code correctness.
This addition lets OpenAI scale RL by making more data available to train on, but has new downstream problems to solve.
This addition lets OpenAI scale RL by making more data available to train on, but has new downstream problems to solve.
April 20, 2025 at 2:06 PM
o3’s weird hallucinations could indicate they used llm as a judge (or other softer verifiers) in high volume and in addition to math/code correctness.
This addition lets OpenAI scale RL by making more data available to train on, but has new downstream problems to solve.
This addition lets OpenAI scale RL by making more data available to train on, but has new downstream problems to solve.
Reposted by Yuhang Zang
One of the first papers I've seen with RLVR / reinforcement finetuning of vision language models
Looks about as simple as we would expect it to be, lots of details to uncover.
Liu et al. Visual-RFT: Visual Reinforcement Fine-Tuning
buff.ly/DbGuYve
(posted a week ago, oops)
Looks about as simple as we would expect it to be, lots of details to uncover.
Liu et al. Visual-RFT: Visual Reinforcement Fine-Tuning
buff.ly/DbGuYve
(posted a week ago, oops)


March 10, 2025 at 3:44 PM
One of the first papers I've seen with RLVR / reinforcement finetuning of vision language models
Looks about as simple as we would expect it to be, lots of details to uncover.
Liu et al. Visual-RFT: Visual Reinforcement Fine-Tuning
buff.ly/DbGuYve
(posted a week ago, oops)
Looks about as simple as we would expect it to be, lots of details to uncover.
Liu et al. Visual-RFT: Visual Reinforcement Fine-Tuning
buff.ly/DbGuYve
(posted a week ago, oops)
Monitoring Reasoning Models for Misbehavior and the Risks of
Promoting Obfuscation cdn.openai.com/pdf/34f2ada6...
Promoting Obfuscation cdn.openai.com/pdf/34f2ada6...
cdn.openai.com
March 11, 2025 at 4:49 AM
Monitoring Reasoning Models for Misbehavior and the Risks of
Promoting Obfuscation cdn.openai.com/pdf/34f2ada6...
Promoting Obfuscation cdn.openai.com/pdf/34f2ada6...
Open-Reasoner-Zero: An Open Source Approach to Scaling Up
Reinforcement Learning on the Base Model
github.com/Open-Reasone...
Reinforcement Learning on the Base Model
github.com/Open-Reasone...
github.com
February 20, 2025 at 11:16 AM
Open-Reasoner-Zero: An Open Source Approach to Scaling Up
Reinforcement Learning on the Base Model
github.com/Open-Reasone...
Reinforcement Learning on the Base Model
github.com/Open-Reasone...
MoBA: Mixture of Block Attention for Long-Context LLMs github.com/MoonshotAI/M...

GitHub - MoonshotAI/MoBA: MoBA: Mixture of Block Attention for Long-Context LLMs
MoBA: Mixture of Block Attention for Long-Context LLMs - MoonshotAI/MoBA
github.com
February 18, 2025 at 12:30 PM
MoBA: Mixture of Block Attention for Long-Context LLMs github.com/MoonshotAI/M...
Preference Modeling: Binary Discrimination Versus Imitation Learning: swtheking.notion.site/182d3429a807...
Preference Modeling: Binary Discrimination Versus Imitation Learning | Notion
Author: Wei Shen, Yunhui Xia
TL;DR: This blog investigates a key observation from the paper
swtheking.notion.site
February 18, 2025 at 7:58 AM
Preference Modeling: Binary Discrimination Versus Imitation Learning: swtheking.notion.site/182d3429a807...
Reposted by Yuhang Zang
Rare that a paper these days uses the original literature of "Outcome reward model" and not just doing bradley-terry model on right/wrong labels.
Nature is healing.
Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning
Lyu et al
arxiv.org/abs/2502.06781
Nature is healing.
Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning
Lyu et al
arxiv.org/abs/2502.06781

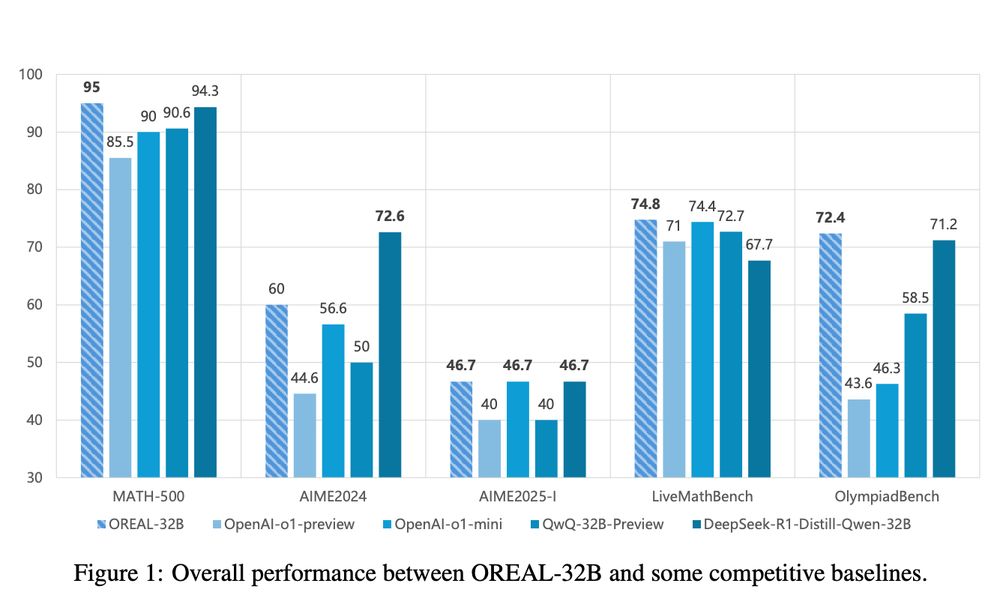
February 15, 2025 at 3:50 PM
Rare that a paper these days uses the original literature of "Outcome reward model" and not just doing bradley-terry model on right/wrong labels.
Nature is healing.
Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning
Lyu et al
arxiv.org/abs/2502.06781
Nature is healing.
Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning
Lyu et al
arxiv.org/abs/2502.06781
Examining False Positives under Inference Scaling for Mathematical Reasoning arxiv.org/pdf/2502.06217
arxiv.org
February 11, 2025 at 8:26 AM
Examining False Positives under Inference Scaling for Mathematical Reasoning arxiv.org/pdf/2502.06217
oatllm.notion.site/oat-zero
There May Not be Aha Moment in R1-Zero-like Training — A Pilot Study
#Papers
There May Not be Aha Moment in R1-Zero-like Training — A Pilot Study
#Papers

There May Not be Aha Moment in R1-Zero-like Training — A Pilot Study | Notion
One of the most inspiring results from DeepSeek-R1-Zero is the occurrence of “Aha moment” through pure reinforcement learning (RL). At the Aha moment, the model learns emergent skills such as self-ref...
oatllm.notion.site
February 7, 2025 at 10:21 AM
oatllm.notion.site/oat-zero
There May Not be Aha Moment in R1-Zero-like Training — A Pilot Study
#Papers
There May Not be Aha Moment in R1-Zero-like Training — A Pilot Study
#Papers
Reposted by Yuhang Zang
This is a potentially counterintuitive result. We actually want the reasoning models to generate more tokens for wrong answers. Eventually, models should “know” when they’re not right and keep spending more compute on it!
Regardless, is a great plot.
arxiv.org/abs/2501.18585
Regardless, is a great plot.
arxiv.org/abs/2501.18585

January 31, 2025 at 1:36 PM
This is a potentially counterintuitive result. We actually want the reasoning models to generate more tokens for wrong answers. Eventually, models should “know” when they’re not right and keep spending more compute on it!
Regardless, is a great plot.
arxiv.org/abs/2501.18585
Regardless, is a great plot.
arxiv.org/abs/2501.18585
Reposted by Yuhang Zang

✍️ Reminder to reviewers: Check author responses to your reviews, and ask follow up questions if needed.
50% of papers have discussion - let’s bring this number up!
50% of papers have discussion - let’s bring this number up!
November 25, 2024 at 12:45 PM
✍️ Reminder to reviewers: Check author responses to your reviews, and ask follow up questions if needed.
50% of papers have discussion - let’s bring this number up!
50% of papers have discussion - let’s bring this number up!