



Harini Sudha
@yoursharini.bsky.social
PhD student at Berens lab @hertie-ai.bsky.social @unituebingen.bsky.social | #ELLIS PhD student & associated w IMPRS-IS | ML for science, NeuroAI | ex: @fz-juelich.de KTH IISERP
Reposted by Harini Sudha

🎓 We're hiring two PhD students in #MachineLearning for my new group at the Hertie Institute for AI in Brain Health, University of Tübingen!
Work on unsupervised learning, #DeepLearning, and #Neuroscience in a vibrant research environment.
👇 Details below
Work on unsupervised learning, #DeepLearning, and #Neuroscience in a vibrant research environment.
👇 Details below
November 13, 2025 at 9:41 AM
🎓 We're hiring two PhD students in #MachineLearning for my new group at the Hertie Institute for AI in Brain Health, University of Tübingen!
Work on unsupervised learning, #DeepLearning, and #Neuroscience in a vibrant research environment.
👇 Details below
Work on unsupervised learning, #DeepLearning, and #Neuroscience in a vibrant research environment.
👇 Details below
Reposted by Harini Sudha

TLDR; The PSF has made the decision to put our community and our shared diversity, equity, and inclusion values ahead of seeking $1.5M in new revenue. Please read and share. pyfound.blogspot.com/2025/10/NSF-...
🧵
🧵

The official home of the Python Programming Language
www.python.org
October 27, 2025 at 2:47 PM
TLDR; The PSF has made the decision to put our community and our shared diversity, equity, and inclusion values ahead of seeking $1.5M in new revenue. Please read and share. pyfound.blogspot.com/2025/10/NSF-...
🧵
🧵
Reposted by Harini Sudha

New #NeuroAI preprint on #ContinualLearning!
Continual learning methods struggle in mostly unsupervised environments with sparse labels (e.g. parents telling their child the object is an 'apple').
We propose that in the cortex, predictive coding of high-level top-down modulations solves this! (1/6)
Continual learning methods struggle in mostly unsupervised environments with sparse labels (e.g. parents telling their child the object is an 'apple').
We propose that in the cortex, predictive coding of high-level top-down modulations solves this! (1/6)
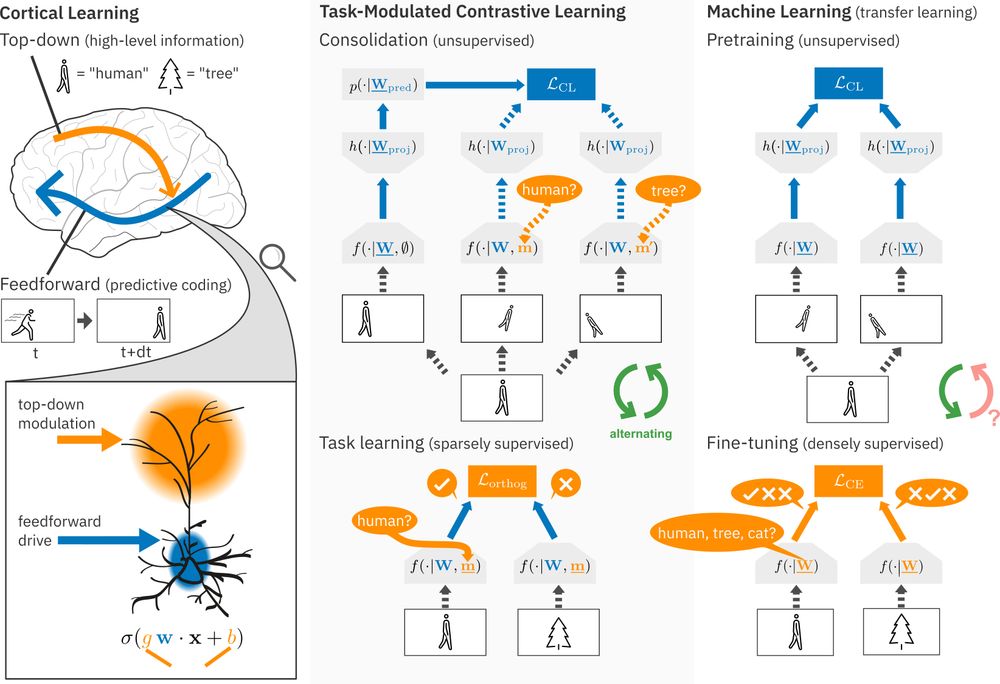
June 10, 2025 at 1:17 PM
New #NeuroAI preprint on #ContinualLearning!
Continual learning methods struggle in mostly unsupervised environments with sparse labels (e.g. parents telling their child the object is an 'apple').
We propose that in the cortex, predictive coding of high-level top-down modulations solves this! (1/6)
Continual learning methods struggle in mostly unsupervised environments with sparse labels (e.g. parents telling their child the object is an 'apple').
We propose that in the cortex, predictive coding of high-level top-down modulations solves this! (1/6)
Reposted by Harini Sudha

Check out our new paper!
Vision models often struggle with learning both transformation-invariant and -equivariant representations at the same time.
@hafezghm.bsky.social shows that self-supervised prediction with proper inductive biases achieves both simultaneously. (1/4)
#MLSky #NeuroAI
Vision models often struggle with learning both transformation-invariant and -equivariant representations at the same time.
@hafezghm.bsky.social shows that self-supervised prediction with proper inductive biases achieves both simultaneously. (1/4)
#MLSky #NeuroAI

Preprint Alert 🚀
Can we simultaneously learn transformation-invariant and transformation-equivariant representations with self-supervised learning?
TL;DR Yes! This is possible via simple predictive learning & architectural inductive biases – without extra loss terms and predictors!
🧵 (1/10)
Can we simultaneously learn transformation-invariant and transformation-equivariant representations with self-supervised learning?
TL;DR Yes! This is possible via simple predictive learning & architectural inductive biases – without extra loss terms and predictors!
🧵 (1/10)

May 14, 2025 at 12:57 PM
Check out our new paper!
Vision models often struggle with learning both transformation-invariant and -equivariant representations at the same time.
@hafezghm.bsky.social shows that self-supervised prediction with proper inductive biases achieves both simultaneously. (1/4)
#MLSky #NeuroAI
Vision models often struggle with learning both transformation-invariant and -equivariant representations at the same time.
@hafezghm.bsky.social shows that self-supervised prediction with proper inductive biases achieves both simultaneously. (1/4)
#MLSky #NeuroAI
Reposted by Harini Sudha

"Our results demonstrate that the better a model understands the data, the more effectively it can compress it, suggesting a deep connection between understanding and compression." - such a cool implication

"LMCompress shatters all previous lossless compression records on four media types: text, images, video and audio."
www.nature.com/articles/s42...
www.nature.com/articles/s42...

Lossless data compression by large models - Nature Machine Intelligence
Effective lossless compression requires that frequent patterns in the data can be identified. Li et al. explore using deep learning models to more effectively compress text, audio and video data.
www.nature.com
May 3, 2025 at 3:02 PM
"Our results demonstrate that the better a model understands the data, the more effectively it can compress it, suggesting a deep connection between understanding and compression." - such a cool implication
Reposted by Harini Sudha

complete blog post is now live! more tips, and reframed into 2-step process: (1) get accepted by page 1, (2) avoid rejection with the rest. download both PDFs too.
maxwellforbes.com/posts/how-to...
maxwellforbes.com/posts/how-to...
April 11, 2025 at 9:35 PM
complete blog post is now live! more tips, and reframed into 2-step process: (1) get accepted by page 1, (2) avoid rejection with the rest. download both PDFs too.
maxwellforbes.com/posts/how-to...
maxwellforbes.com/posts/how-to...
Reposted by Harini Sudha

There’s no such thing as A.I “art.” It’s a soulless amalgamation of plagiarised data. That is the antithesis of art.
March 29, 2025 at 12:48 PM
There’s no such thing as A.I “art.” It’s a soulless amalgamation of plagiarised data. That is the antithesis of art.
Reposted by Harini Sudha

After 6+ months in the making and over a year of GPU compute, we're excited to release the "Ultra-Scale Playbook": hf.co/spaces/nanot...
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!

The Ultra-Scale Playbook - a Hugging Face Space by nanotron
The ultimate guide to training LLM on large GPU Clusters
hf.co
February 19, 2025 at 6:10 PM
After 6+ months in the making and over a year of GPU compute, we're excited to release the "Ultra-Scale Playbook": hf.co/spaces/nanot...
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
Reposted by Harini Sudha

Why & how scientists should do public outreach, especially now. Smart tips from @nicolecrust.bsky.social on @thetransmitter.bsky.social 🧪 www.thetransmitter.org/craft-and-ca...

In your New Year’s resolutions for 2025, consider public outreach
If every person in the neuroscience community committed to doing one thing, imagine the cumulative difference it would make.
www.thetransmitter.org
January 4, 2025 at 4:09 PM
Why & how scientists should do public outreach, especially now. Smart tips from @nicolecrust.bsky.social on @thetransmitter.bsky.social 🧪 www.thetransmitter.org/craft-and-ca...