




Long Le
@vlongle.bsky.social
PhD student at University of Pennsylvania . Working on robot learning. https://vlongle.github.io/
🚀 How well does it work?
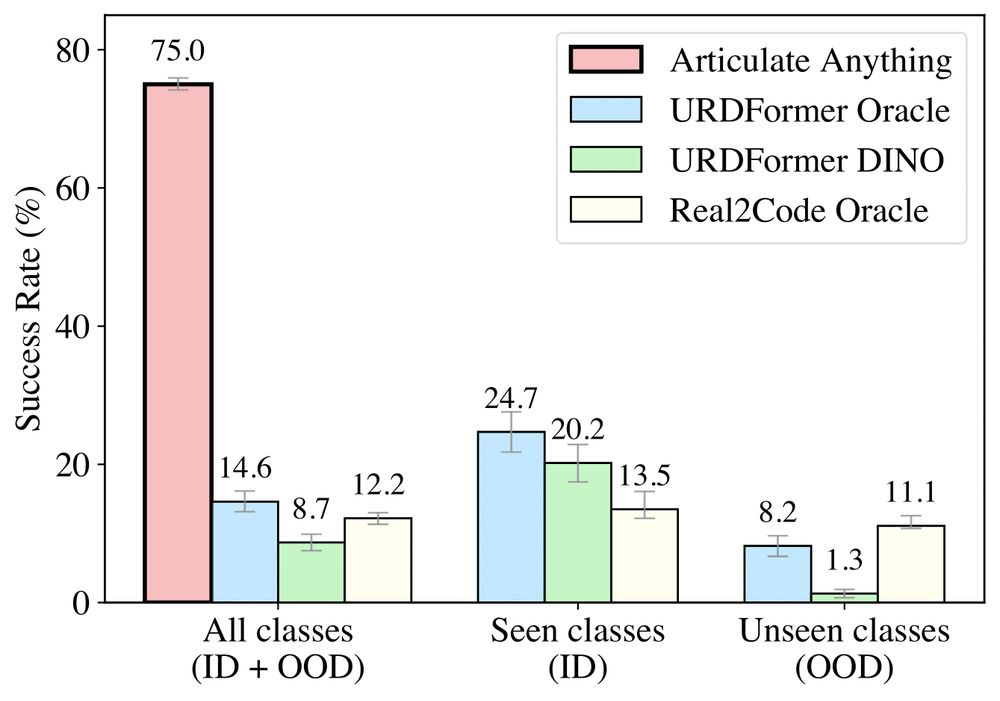
Articulate-Anything is much better than the baselines both quantitatively and qualitatively. This is possible due to (1) leveraging richer input modalities, (2) modeling articulation as a high-level program synthesis, (3) leveraging a closed-loop actor-critic system
Articulate-Anything is much better than the baselines both quantitatively and qualitatively. This is possible due to (1) leveraging richer input modalities, (2) modeling articulation as a high-level program synthesis, (3) leveraging a closed-loop actor-critic system

December 10, 2024 at 4:44 PM
🚀 How well does it work?
Articulate-Anything is much better than the baselines both quantitatively and qualitatively. This is possible due to (1) leveraging richer input modalities, (2) modeling articulation as a high-level program synthesis, (3) leveraging a closed-loop actor-critic system
Articulate-Anything is much better than the baselines both quantitatively and qualitatively. This is possible due to (1) leveraging richer input modalities, (2) modeling articulation as a high-level program synthesis, (3) leveraging a closed-loop actor-critic system
🧩How does it work?
Articulate-Anything breaks the problem into three steps: (1) Mesh retrieval, (2) Link placement, which spatially arranges the parts together, and (3) Joint prediction, which determines the kinematic movement between parts. Take a look at a video explaining this pipeline!
Articulate-Anything breaks the problem into three steps: (1) Mesh retrieval, (2) Link placement, which spatially arranges the parts together, and (3) Joint prediction, which determines the kinematic movement between parts. Take a look at a video explaining this pipeline!
December 10, 2024 at 4:44 PM
🧩How does it work?
Articulate-Anything breaks the problem into three steps: (1) Mesh retrieval, (2) Link placement, which spatially arranges the parts together, and (3) Joint prediction, which determines the kinematic movement between parts. Take a look at a video explaining this pipeline!
Articulate-Anything breaks the problem into three steps: (1) Mesh retrieval, (2) Link placement, which spatially arranges the parts together, and (3) Joint prediction, which determines the kinematic movement between parts. Take a look at a video explaining this pipeline!
🙀Why does this matter?
Creating interactable 3D models of the world is hard. An artist have to model the physical appearance of the object to create a mesh. Then a roboticist needs to manually annotate the kinematic joints to give object movement in URDF.
But what we can automate all these steps?
Creating interactable 3D models of the world is hard. An artist have to model the physical appearance of the object to create a mesh. Then a roboticist needs to manually annotate the kinematic joints to give object movement in URDF.
But what we can automate all these steps?
December 10, 2024 at 4:44 PM
🙀Why does this matter?
Creating interactable 3D models of the world is hard. An artist have to model the physical appearance of the object to create a mesh. Then a roboticist needs to manually annotate the kinematic joints to give object movement in URDF.
But what we can automate all these steps?
Creating interactable 3D models of the world is hard. An artist have to model the physical appearance of the object to create a mesh. Then a roboticist needs to manually annotate the kinematic joints to give object movement in URDF.
But what we can automate all these steps?
📦 Can frontier AI transform ANY physical object from ANY input modality into a high-quality digital twin that also MOVES?
Excited to share our work,Articulate-Anything 🐵, exploring how VLMs can bridge the gap between the physical and digital worlds.
Website: articulate-anything.github.io
Excited to share our work,Articulate-Anything 🐵, exploring how VLMs can bridge the gap between the physical and digital worlds.
Website: articulate-anything.github.io
December 10, 2024 at 4:44 PM
📦 Can frontier AI transform ANY physical object from ANY input modality into a high-quality digital twin that also MOVES?
Excited to share our work,Articulate-Anything 🐵, exploring how VLMs can bridge the gap between the physical and digital worlds.
Website: articulate-anything.github.io
Excited to share our work,Articulate-Anything 🐵, exploring how VLMs can bridge the gap between the physical and digital worlds.
Website: articulate-anything.github.io