




Valentina Pyatkin
@valentinapy.bsky.social
Postdoc in AI at the Allen Institute for AI & the University of Washington.
🌐 https://valentinapy.github.io
🌐 https://valentinapy.github.io
I will be giving a talk at @eth-ai-center.bsky.social next week, on RLVR for verifiable instruction following, generalization, and reasoning! 📢
Join if you are in Zurich and interested in hearing about IFBench and our latest Olmo and Tülu works at @ai2.bsky.social
Join if you are in Zurich and interested in hearing about IFBench and our latest Olmo and Tülu works at @ai2.bsky.social

October 27, 2025 at 2:22 PM
I will be giving a talk at @eth-ai-center.bsky.social next week, on RLVR for verifiable instruction following, generalization, and reasoning! 📢
Join if you are in Zurich and interested in hearing about IFBench and our latest Olmo and Tülu works at @ai2.bsky.social
Join if you are in Zurich and interested in hearing about IFBench and our latest Olmo and Tülu works at @ai2.bsky.social
Next up we had @tsvetshop ‘s Yulia Tsvetkov talk about ethics, safety, and reliability of LLMs in the health domain.

October 10, 2025 at 4:09 PM
Next up we had @tsvetshop ‘s Yulia Tsvetkov talk about ethics, safety, and reliability of LLMs in the health domain.
💡We kicked off the SoLaR workshop at #COLM2025 with a great opinion talk by @michelleding.bsky.social & Jo Gasior Kavishe (joint work with @victorojewale.bsky.social and
@geomblog.bsky.social
) on "Testing LLMs in a sandbox isn't responsible. Focusing on community use and needs is."
@geomblog.bsky.social
) on "Testing LLMs in a sandbox isn't responsible. Focusing on community use and needs is."

October 10, 2025 at 2:31 PM
💡We kicked off the SoLaR workshop at #COLM2025 with a great opinion talk by @michelleding.bsky.social & Jo Gasior Kavishe (joint work with @victorojewale.bsky.social and
@geomblog.bsky.social
) on "Testing LLMs in a sandbox isn't responsible. Focusing on community use and needs is."
@geomblog.bsky.social
) on "Testing LLMs in a sandbox isn't responsible. Focusing on community use and needs is."
On my way to Oxford: Looking forward to speaking at OxML 2025

August 10, 2025 at 8:09 AM
On my way to Oxford: Looking forward to speaking at OxML 2025
🔥tokenization panel!

July 18, 2025 at 10:45 PM
🔥tokenization panel!
Additionally, we wrote new training constraints and verifier functions and suggest a good recipe for IF-RLVR training for improved generalization.
We find that IF-RLVR generalization works best on base models and when you train on multiple constraints per instruction!
We find that IF-RLVR generalization works best on base models and when you train on multiple constraints per instruction!
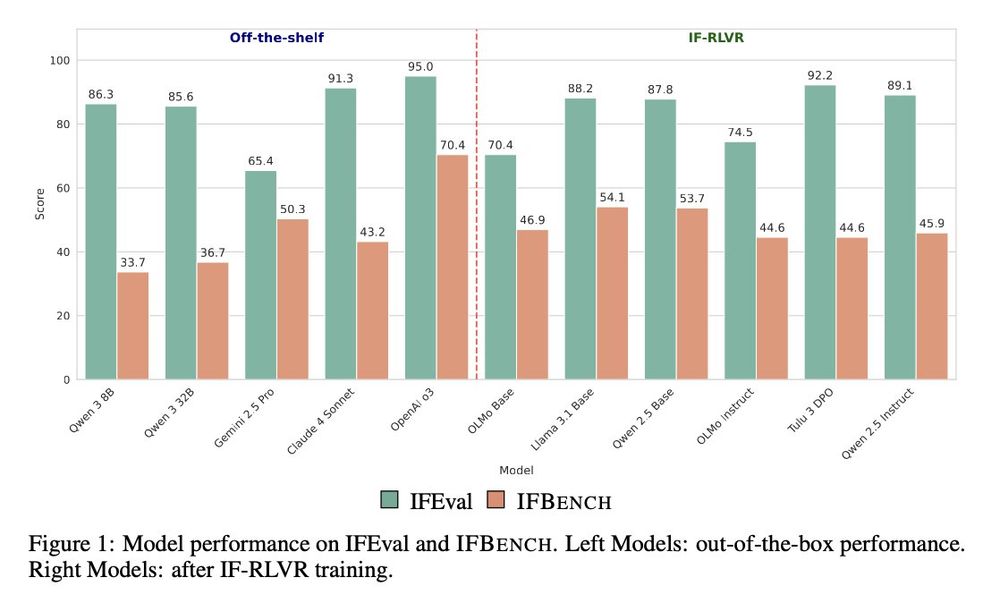
July 3, 2025 at 9:06 PM
Additionally, we wrote new training constraints and verifier functions and suggest a good recipe for IF-RLVR training for improved generalization.
We find that IF-RLVR generalization works best on base models and when you train on multiple constraints per instruction!
We find that IF-RLVR generalization works best on base models and when you train on multiple constraints per instruction!
💡Beyond math/code, instruction following with verifiable constraints is suitable to be learned with RLVR.
But the set of constraints and verifier functions is limited and most models overfit on IFEval.
We introduce IFBench to measure model generalization to unseen constraints.
But the set of constraints and verifier functions is limited and most models overfit on IFEval.
We introduce IFBench to measure model generalization to unseen constraints.

July 3, 2025 at 9:06 PM
💡Beyond math/code, instruction following with verifiable constraints is suitable to be learned with RLVR.
But the set of constraints and verifier functions is limited and most models overfit on IFEval.
We introduce IFBench to measure model generalization to unseen constraints.
But the set of constraints and verifier functions is limited and most models overfit on IFEval.
We introduce IFBench to measure model generalization to unseen constraints.
Interested in shaping the progress of responsible AI and meeting leading researchers in the field? SoLaR@COLM 2025 is looking for paper submissions and reviewers!
🤖 ML track: algorithms, math, computation
📚 Socio-technical track: policy, ethics, human participant research
🤖 ML track: algorithms, math, computation
📚 Socio-technical track: policy, ethics, human participant research

June 17, 2025 at 5:46 PM
Interested in shaping the progress of responsible AI and meeting leading researchers in the field? SoLaR@COLM 2025 is looking for paper submissions and reviewers!
🤖 ML track: algorithms, math, computation
📚 Socio-technical track: policy, ethics, human participant research
🤖 ML track: algorithms, math, computation
📚 Socio-technical track: policy, ethics, human participant research
📢 The SoLaR workshop will be collocated with COLM!
@colmweb.org
SoLaR is a collaborative forum for researchers working on responsible development, deployment and use of language models.
We welcome both technical and sociotechnical submissions, deadline July 5th!
@colmweb.org
SoLaR is a collaborative forum for researchers working on responsible development, deployment and use of language models.
We welcome both technical and sociotechnical submissions, deadline July 5th!


May 12, 2025 at 3:25 PM
📢 The SoLaR workshop will be collocated with COLM!
@colmweb.org
SoLaR is a collaborative forum for researchers working on responsible development, deployment and use of language models.
We welcome both technical and sociotechnical submissions, deadline July 5th!
@colmweb.org
SoLaR is a collaborative forum for researchers working on responsible development, deployment and use of language models.
We welcome both technical and sociotechnical submissions, deadline July 5th!
this year it’s a thermos and not a mug 🥲

December 11, 2024 at 12:37 AM
this year it’s a thermos and not a mug 🥲
Michael will present his work on "Diverging Preferences" at the Pluralistic Alignment workshop!

December 1, 2024 at 11:56 PM
Michael will present his work on "Diverging Preferences" at the Pluralistic Alignment workshop!
@drjingjing.bsky.social will present her SafetyAnalyst work at the SoLaR workshop:

December 1, 2024 at 11:56 PM
@drjingjing.bsky.social will present her SafetyAnalyst work at the SoLaR workshop:
@shocheen.bsky.social and co will be at the Thursday poster session to present our paper on "Contextual Noncompliance"

December 1, 2024 at 11:56 PM
@shocheen.bsky.social and co will be at the Thursday poster session to present our paper on "Contextual Noncompliance"
On Thursday, @hamishivi.bsky.social will present our work on "Unpacking DPO and PPO"

December 1, 2024 at 11:56 PM
On Thursday, @hamishivi.bsky.social will present our work on "Unpacking DPO and PPO"

Open Post-Training recipes!
Some of my personal highlights:
💡 We significantly scaled up our preference data!
💡 RL with Verifiable Rewards to improve targeted skills like math and precise instruction following
💡 evaluation toolkit for post-training (including new unseen evals!)
Some of my personal highlights:
💡 We significantly scaled up our preference data!
💡 RL with Verifiable Rewards to improve targeted skills like math and precise instruction following
💡 evaluation toolkit for post-training (including new unseen evals!)

November 21, 2024 at 6:40 PM
Open Post-Training recipes!
Some of my personal highlights:
💡 We significantly scaled up our preference data!
💡 RL with Verifiable Rewards to improve targeted skills like math and precise instruction following
💡 evaluation toolkit for post-training (including new unseen evals!)
Some of my personal highlights:
💡 We significantly scaled up our preference data!
💡 RL with Verifiable Rewards to improve targeted skills like math and precise instruction following
💡 evaluation toolkit for post-training (including new unseen evals!)

📣 We are looking forward to an interesting line up of invited speakers at the SoLaR workshop at NeurIPS! solar-neurips.github.io
Come join us on Saturday, Dec. 14th in Vancouver
@peterhenderson.bsky.social, Been Kim, @zicokolter.bsky.social, Rida Qadri, Hannah Rose Kirk
Come join us on Saturday, Dec. 14th in Vancouver
@peterhenderson.bsky.social, Been Kim, @zicokolter.bsky.social, Rida Qadri, Hannah Rose Kirk

November 18, 2024 at 7:27 PM
📣 We are looking forward to an interesting line up of invited speakers at the SoLaR workshop at NeurIPS! solar-neurips.github.io
Come join us on Saturday, Dec. 14th in Vancouver
@peterhenderson.bsky.social, Been Kim, @zicokolter.bsky.social, Rida Qadri, Hannah Rose Kirk
Come join us on Saturday, Dec. 14th in Vancouver
@peterhenderson.bsky.social, Been Kim, @zicokolter.bsky.social, Rida Qadri, Hannah Rose Kirk
To address this, we develop distributional reward models which can model annotator preferences while also identifying disagreements.
We show these models can be applied to improve evaluations by identifying divisive examples in LLM-as-Judge benchmarks like WildBench.
[5/6]
We show these models can be applied to improve evaluations by identifying divisive examples in LLM-as-Judge benchmarks like WildBench.
[5/6]

November 7, 2024 at 5:40 PM
To address this, we develop distributional reward models which can model annotator preferences while also identifying disagreements.
We show these models can be applied to improve evaluations by identifying divisive examples in LLM-as-Judge benchmarks like WildBench.
[5/6]
We show these models can be applied to improve evaluations by identifying divisive examples in LLM-as-Judge benchmarks like WildBench.
[5/6]
We identify similar behaviors in LLM-as-Judge evaluations, and find biases in how these methods identify winning responses in cases of diverging preferences.
For instance, LLM-judges prefer complying responses when annotators disagree on whether refusing is appropriate.
[4/6]
For instance, LLM-judges prefer complying responses when annotators disagree on whether refusing is appropriate.
[4/6]

November 7, 2024 at 5:40 PM
We identify similar behaviors in LLM-as-Judge evaluations, and find biases in how these methods identify winning responses in cases of diverging preferences.
For instance, LLM-judges prefer complying responses when annotators disagree on whether refusing is appropriate.
[4/6]
For instance, LLM-judges prefer complying responses when annotators disagree on whether refusing is appropriate.
[4/6]
Since disagreements caused by split user perspectives, do reward models capture these diverse user views?
We find reward models fail to distinguish between diverging and high-agreement preferences, decisively identifying a preferred response even when annotators disagree.
[3/6]
We find reward models fail to distinguish between diverging and high-agreement preferences, decisively identifying a preferred response even when annotators disagree.
[3/6]

November 7, 2024 at 5:39 PM
Since disagreements caused by split user perspectives, do reward models capture these diverse user views?
We find reward models fail to distinguish between diverging and high-agreement preferences, decisively identifying a preferred response even when annotators disagree.
[3/6]
We find reward models fail to distinguish between diverging and high-agreement preferences, decisively identifying a preferred response even when annotators disagree.
[3/6]
Why and when do preference annotators disagree? And how do reward models + LLM-as-Judge evaluators handle disagreements?
Michael explored these questions in a new ✨preprint✨ from his @ai2.bsky.social internship with me!
Michael explored these questions in a new ✨preprint✨ from his @ai2.bsky.social internship with me!

November 7, 2024 at 5:38 PM
Why and when do preference annotators disagree? And how do reward models + LLM-as-Judge evaluators handle disagreements?
Michael explored these questions in a new ✨preprint✨ from his @ai2.bsky.social internship with me!
Michael explored these questions in a new ✨preprint✨ from his @ai2.bsky.social internship with me!
"Do LLM predictors provide structurally consistent outputs in the zero- and few-shot regime?"
Our new work "Promptly Predicting Structures: The Return of Inference" shows that they do not, and we show how to fix it.
Paper: arxiv.org/abs/2401.06877
Code: github.com/utahnlp/prom...
Our new work "Promptly Predicting Structures: The Return of Inference" shows that they do not, and we show how to fix it.
Paper: arxiv.org/abs/2401.06877
Code: github.com/utahnlp/prom...

January 19, 2024 at 2:27 AM
"Do LLM predictors provide structurally consistent outputs in the zero- and few-shot regime?"
Our new work "Promptly Predicting Structures: The Return of Inference" shows that they do not, and we show how to fix it.
Paper: arxiv.org/abs/2401.06877
Code: github.com/utahnlp/prom...
Our new work "Promptly Predicting Structures: The Return of Inference" shows that they do not, and we show how to fix it.
Paper: arxiv.org/abs/2401.06877
Code: github.com/utahnlp/prom...