



Ksenia Se / Turing Post
@turingpost.bsky.social
Founder of the newsletter that explores AI & ML (https://www.turingpost.com)
- AI 101 series
- ML techniques
- AI Unicorns profiles
- Global dynamics
- ML History
- AI/ML Flashcards
Haven't decided yet which handle to maintain: this or @kseniase
- AI 101 series
- ML techniques
- AI Unicorns profiles
- Global dynamics
- ML History
- AI/ML Flashcards
Haven't decided yet which handle to maintain: this or @kseniase
"Densing Law of LLMs" paper: arxiv.org/abs/2412.04315

December 11, 2024 at 11:40 AM
"Densing Law of LLMs" paper: arxiv.org/abs/2412.04315
• The amount of work an LLM can handle on the same hardware is growing even faster than the improvements in model density or chip power alone.
That's why researchers suggest focusing on improving "density" instead of just aiming for bigger and more powerful models.
That's why researchers suggest focusing on improving "density" instead of just aiming for bigger and more powerful models.
December 11, 2024 at 11:40 AM
• The amount of work an LLM can handle on the same hardware is growing even faster than the improvements in model density or chip power alone.
That's why researchers suggest focusing on improving "density" instead of just aiming for bigger and more powerful models.
That's why researchers suggest focusing on improving "density" instead of just aiming for bigger and more powerful models.
Here are the key findings from the study:
• Costs to run models are dropping as they are becoming more efficient.
• The release of ChatGPT sped up the growth of efficiency of new models up to 50%!
• Techniques like pruning and distillation don’t necessarily make models more efficient.
• Costs to run models are dropping as they are becoming more efficient.
• The release of ChatGPT sped up the growth of efficiency of new models up to 50%!
• Techniques like pruning and distillation don’t necessarily make models more efficient.
December 11, 2024 at 11:40 AM
Here are the key findings from the study:
• Costs to run models are dropping as they are becoming more efficient.
• The release of ChatGPT sped up the growth of efficiency of new models up to 50%!
• Techniques like pruning and distillation don’t necessarily make models more efficient.
• Costs to run models are dropping as they are becoming more efficient.
• The release of ChatGPT sped up the growth of efficiency of new models up to 50%!
• Techniques like pruning and distillation don’t necessarily make models more efficient.
Estimating of effective parameter size:
It combines a two-step process:
- Loss Estimation: Links a model's size and training data to its accuracy
- Performance Estimation: Uses a sigmoid function to predict how well a model performs based on its loss.
It combines a two-step process:
- Loss Estimation: Links a model's size and training data to its accuracy
- Performance Estimation: Uses a sigmoid function to predict how well a model performs based on its loss.
December 11, 2024 at 11:40 AM
Estimating of effective parameter size:
It combines a two-step process:
- Loss Estimation: Links a model's size and training data to its accuracy
- Performance Estimation: Uses a sigmoid function to predict how well a model performs based on its loss.
It combines a two-step process:
- Loss Estimation: Links a model's size and training data to its accuracy
- Performance Estimation: Uses a sigmoid function to predict how well a model performs based on its loss.
Scaling law:
The density of a model is the ratio of its effective parameter size to its actual parameter size.
If the effective size is close to or smaller than the actual size, the model is very efficient.
The density of a model is the ratio of its effective parameter size to its actual parameter size.
If the effective size is close to or smaller than the actual size, the model is very efficient.
December 11, 2024 at 11:40 AM
Scaling law:
The density of a model is the ratio of its effective parameter size to its actual parameter size.
If the effective size is close to or smaller than the actual size, the model is very efficient.
The density of a model is the ratio of its effective parameter size to its actual parameter size.
If the effective size is close to or smaller than the actual size, the model is very efficient.
Why is density important?
A higher-density model can deliver better results without needing more resources, reducing computational costs, making models suitable for devices with limited resources, like smartphones and avoiding unnecessary energy use.
A higher-density model can deliver better results without needing more resources, reducing computational costs, making models suitable for devices with limited resources, like smartphones and avoiding unnecessary energy use.
December 11, 2024 at 11:40 AM
Why is density important?
A higher-density model can deliver better results without needing more resources, reducing computational costs, making models suitable for devices with limited resources, like smartphones and avoiding unnecessary energy use.
A higher-density model can deliver better results without needing more resources, reducing computational costs, making models suitable for devices with limited resources, like smartphones and avoiding unnecessary energy use.
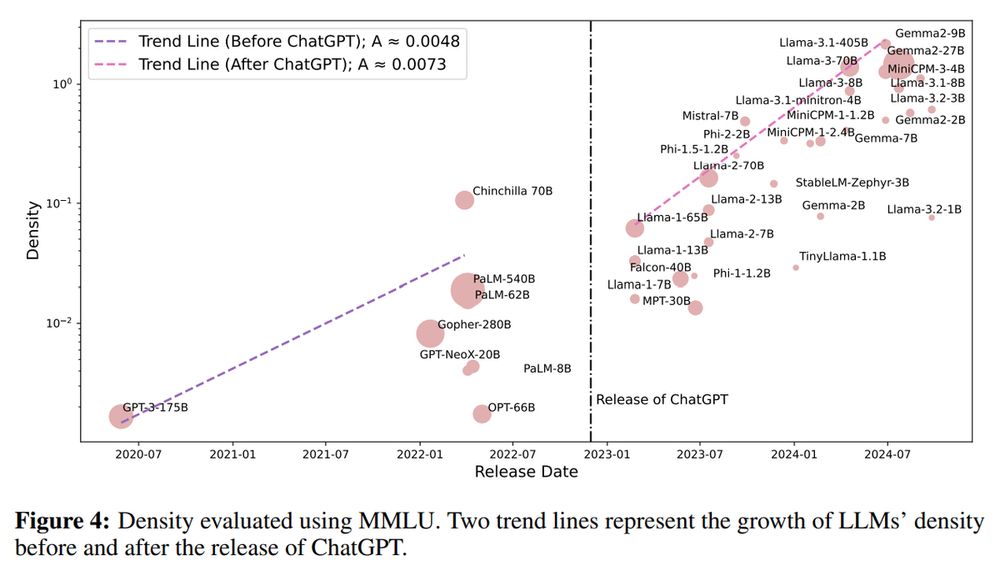
Interestingly, they found a trend, called Densing Law:
The capacity density of LLMs is doubling every 3 months, meaning that newer models are getting much better at balancing performance and size.
Let's look at this more precisely:
December 11, 2024 at 11:40 AM
Interestingly, they found a trend, called Densing Law:
The capacity density of LLMs is doubling every 3 months, meaning that newer models are getting much better at balancing performance and size.
Let's look at this more precisely:
Explore more interesting ML/AI news in our free weekly newsletter -> www.turingpost.com/p/fod79

🌁#79: Sora and World Models – Bringing magic to muggles
Spatial Intelligence just got a boost! Plus, a concise coverage of the remarkably rich week in ML research and innovations
www.turingpost.com
December 10, 2024 at 10:47 PM
Explore more interesting ML/AI news in our free weekly newsletter -> www.turingpost.com/p/fod79
2. AI system from World Labs, co-founded by Fei-Fei Li:
Transforms a single image into interactive 3D scenes with varied art styles and realistic physics. You can explore, interact with elements and move within AI-generated environments directly in your web browser
www.youtube.com/watch?v=lPYJ...
Transforms a single image into interactive 3D scenes with varied art styles and realistic physics. You can explore, interact with elements and move within AI-generated environments directly in your web browser
www.youtube.com/watch?v=lPYJ...

World Labs Unveils AI System That Transforms Single Images into Interactive 3D Worlds
YouTube video by Maginative
www.youtube.com
December 10, 2024 at 10:47 PM
2. AI system from World Labs, co-founded by Fei-Fei Li:
Transforms a single image into interactive 3D scenes with varied art styles and realistic physics. You can explore, interact with elements and move within AI-generated environments directly in your web browser
www.youtube.com/watch?v=lPYJ...
Transforms a single image into interactive 3D scenes with varied art styles and realistic physics. You can explore, interact with elements and move within AI-generated environments directly in your web browser
www.youtube.com/watch?v=lPYJ...
1. GoogleDeepMind's Genie 2
Generates 3D environments with object interactions, animations, and physical effects from one image or text prompt. You can interact with them in real-time using a keyboard and mouse.
Paper: deepmind.google/discover/blo...
Our example: www.youtube.com/watch?v=YjO6...
Generates 3D environments with object interactions, animations, and physical effects from one image or text prompt. You can interact with them in real-time using a keyboard and mouse.
Paper: deepmind.google/discover/blo...
Our example: www.youtube.com/watch?v=YjO6...

December 10, 2024 at 10:47 PM
1. GoogleDeepMind's Genie 2
Generates 3D environments with object interactions, animations, and physical effects from one image or text prompt. You can interact with them in real-time using a keyboard and mouse.
Paper: deepmind.google/discover/blo...
Our example: www.youtube.com/watch?v=YjO6...
Generates 3D environments with object interactions, animations, and physical effects from one image or text prompt. You can interact with them in real-time using a keyboard and mouse.
Paper: deepmind.google/discover/blo...
Our example: www.youtube.com/watch?v=YjO6...
In our new AI 101 episode we discuss:
- FM concepts for optimizing the path from noise to realistic data
- Continuous Normalizing Flows (CNFs)
- Conditional Flow Matching
- Difference of FM and diffusion models
Find out more: turingpost.com/p/flowmatching
- FM concepts for optimizing the path from noise to realistic data
- Continuous Normalizing Flows (CNFs)
- Conditional Flow Matching
- Difference of FM and diffusion models
Find out more: turingpost.com/p/flowmatching

Topic 20: What is Flow Matching?
Explore the key concepts of Flow Matching, its relation to diffusion models, and how it can enhance the training of generative models
turingpost.com
December 5, 2024 at 1:06 AM
In our new AI 101 episode we discuss:
- FM concepts for optimizing the path from noise to realistic data
- Continuous Normalizing Flows (CNFs)
- Conditional Flow Matching
- Difference of FM and diffusion models
Find out more: turingpost.com/p/flowmatching
- FM concepts for optimizing the path from noise to realistic data
- Continuous Normalizing Flows (CNFs)
- Conditional Flow Matching
- Difference of FM and diffusion models
Find out more: turingpost.com/p/flowmatching
Also, elevate your AI game with our free newsletter ↓
www.turingpost.com/subscribe
www.turingpost.com/subscribe

Turing Post
Saves you a lot of research time, plus gives a flashback to ML history and insights into the future. Stay ahead alongside over 73,000 professionals from top AI labs, ML startups, and enterprises
www.turingpost.com
December 5, 2024 at 12:30 AM
Also, elevate your AI game with our free newsletter ↓
www.turingpost.com/subscribe
www.turingpost.com/subscribe
See other important AI/ML news in our free weekly newsletter: www.turingpost.com/p/fod78

🌁#78: Enabling the Future of AI (2025)
join the prediction game plus our usual collection of interesting articles, relevant news, and research papers. Dive in!
www.turingpost.com
December 5, 2024 at 12:30 AM
See other important AI/ML news in our free weekly newsletter: www.turingpost.com/p/fod78
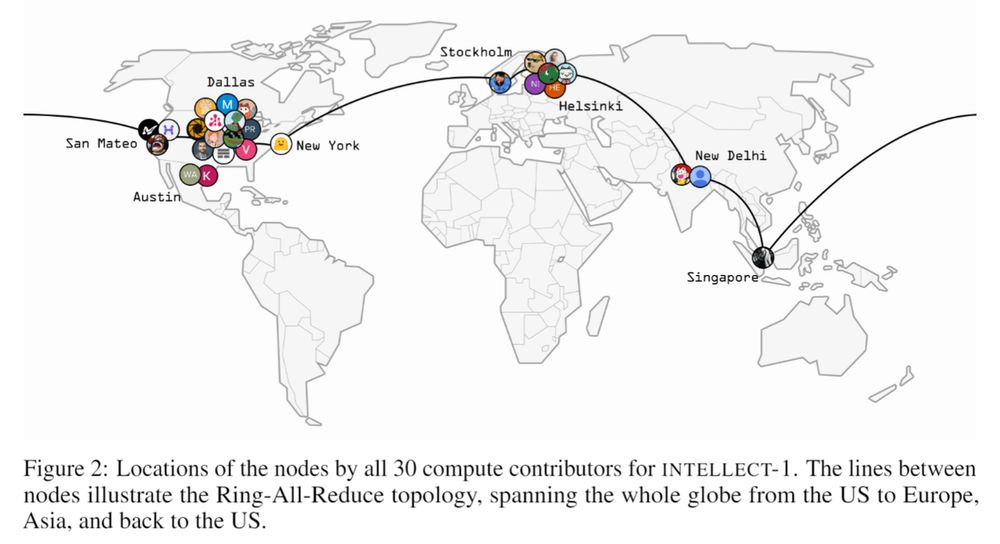
INTELLECT-1 by Prime Intellect
INTELLECT-1 is a 10B open-source LLM trained over 42 days on 1T tokens across 14 global nodes, leverages the PRIME framework for exceptional efficiency (400× bandwidth reduction).
github.com/PrimeIntelle...
INTELLECT-1 is a 10B open-source LLM trained over 42 days on 1T tokens across 14 global nodes, leverages the PRIME framework for exceptional efficiency (400× bandwidth reduction).
github.com/PrimeIntelle...
December 5, 2024 at 12:30 AM
INTELLECT-1 by Prime Intellect
INTELLECT-1 is a 10B open-source LLM trained over 42 days on 1T tokens across 14 global nodes, leverages the PRIME framework for exceptional efficiency (400× bandwidth reduction).
github.com/PrimeIntelle...
INTELLECT-1 is a 10B open-source LLM trained over 42 days on 1T tokens across 14 global nodes, leverages the PRIME framework for exceptional efficiency (400× bandwidth reduction).
github.com/PrimeIntelle...
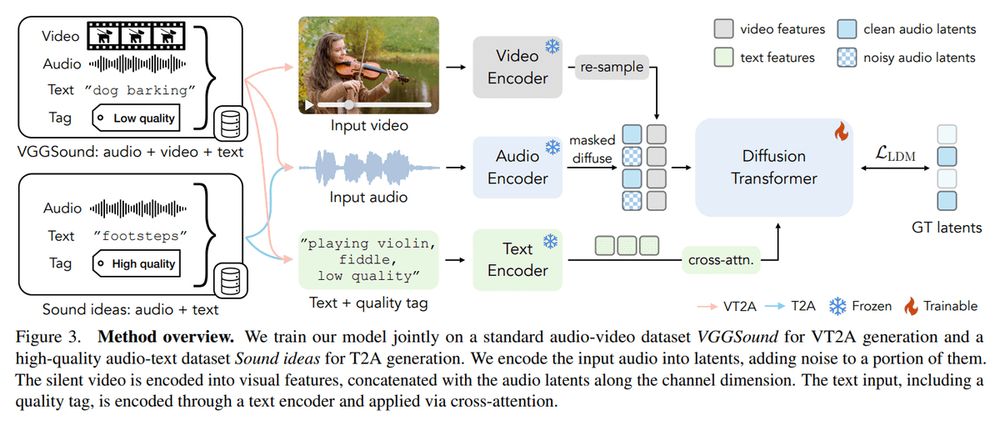
MultiFoley by Adobe Research
MultiFoley is an AI model generating high-quality sound effects from text, audio, and video inputs. Cool demos highlight its creative potential.
arxiv.org/abs/2411.17698
MultiFoley is an AI model generating high-quality sound effects from text, audio, and video inputs. Cool demos highlight its creative potential.
arxiv.org/abs/2411.17698
December 5, 2024 at 12:30 AM
MultiFoley by Adobe Research
MultiFoley is an AI model generating high-quality sound effects from text, audio, and video inputs. Cool demos highlight its creative potential.
arxiv.org/abs/2411.17698
MultiFoley is an AI model generating high-quality sound effects from text, audio, and video inputs. Cool demos highlight its creative potential.
arxiv.org/abs/2411.17698
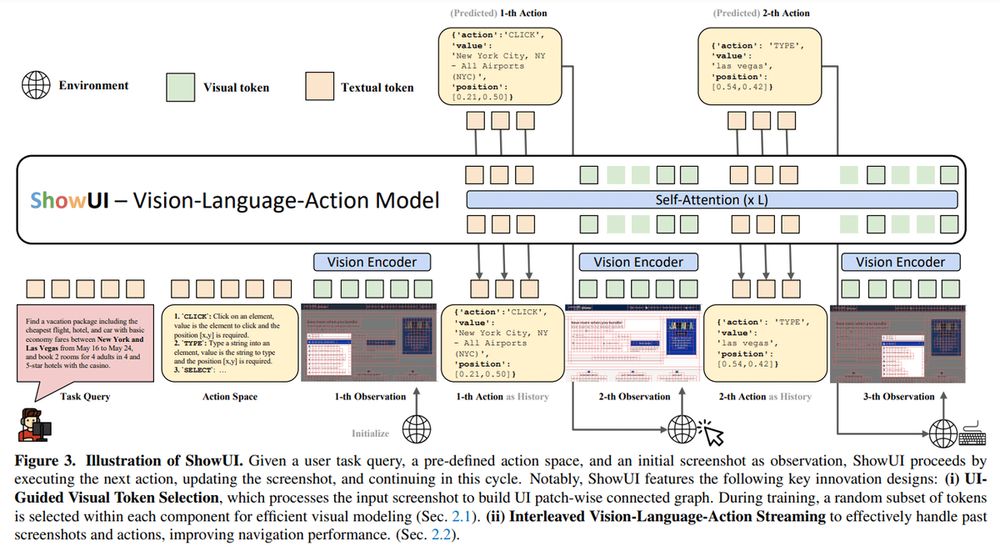
ShowUI by Show Lab, NUS, Microsoft
ShowUI is a 2B vision-language-action model tailored for GUI tasks:
- features UI-guided token selection (33% fewer tokens)
- interleaved streaming for multi-turn tasks
- 256K dataset
- achieves 75.1% zero-shot grounding accuracy
arxiv.org/abs/2411.17465
ShowUI is a 2B vision-language-action model tailored for GUI tasks:
- features UI-guided token selection (33% fewer tokens)
- interleaved streaming for multi-turn tasks
- 256K dataset
- achieves 75.1% zero-shot grounding accuracy
arxiv.org/abs/2411.17465
December 5, 2024 at 12:30 AM
ShowUI by Show Lab, NUS, Microsoft
ShowUI is a 2B vision-language-action model tailored for GUI tasks:
- features UI-guided token selection (33% fewer tokens)
- interleaved streaming for multi-turn tasks
- 256K dataset
- achieves 75.1% zero-shot grounding accuracy
arxiv.org/abs/2411.17465
ShowUI is a 2B vision-language-action model tailored for GUI tasks:
- features UI-guided token selection (33% fewer tokens)
- interleaved streaming for multi-turn tasks
- 256K dataset
- achieves 75.1% zero-shot grounding accuracy
arxiv.org/abs/2411.17465
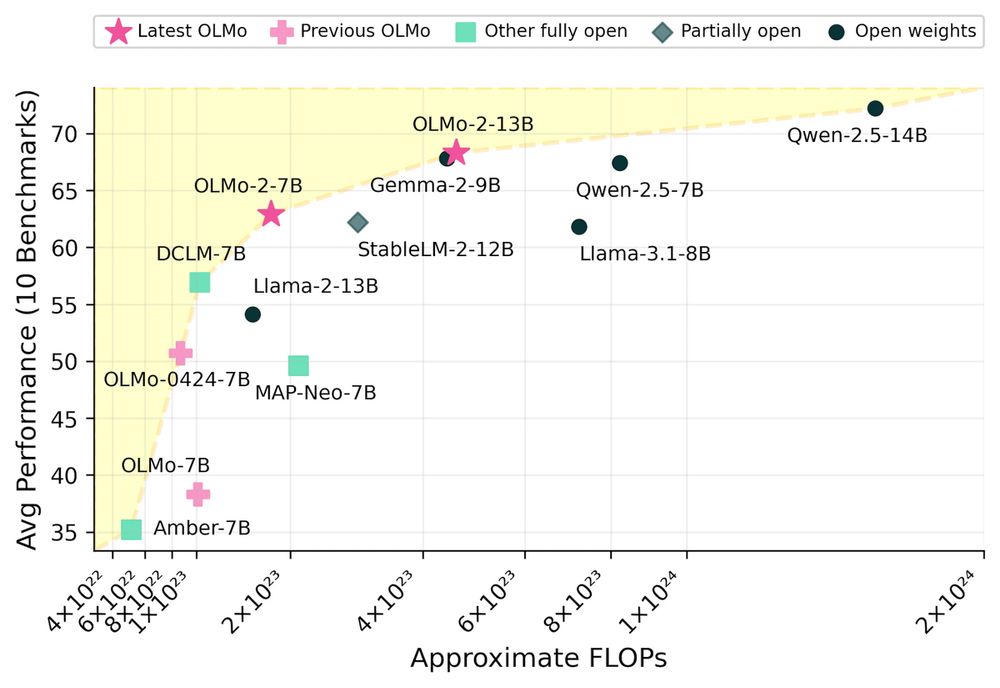
OLMo 2 by Allen AI
OLMo 2, a family of fully open LMs with 7B and 13B parameter, is trained on 5 trillion tokens.
allenai.org/blog/olmo2
OLMo 2, a family of fully open LMs with 7B and 13B parameter, is trained on 5 trillion tokens.
allenai.org/blog/olmo2
December 5, 2024 at 12:30 AM
OLMo 2 by Allen AI
OLMo 2, a family of fully open LMs with 7B and 13B parameter, is trained on 5 trillion tokens.
allenai.org/blog/olmo2
OLMo 2, a family of fully open LMs with 7B and 13B parameter, is trained on 5 trillion tokens.
allenai.org/blog/olmo2
Alibaba’s QwQ-32B
It excites with strong math, coding, and reasoning scores, ranking between Claude 3.5 Sonnet and OpenAI’s o1-mini.
- Optimized for consumer GPUs through quantization
- Open-sourced under Apache, revealing tokens and weights
huggingface.co/Qwen/QwQ-32B...
It excites with strong math, coding, and reasoning scores, ranking between Claude 3.5 Sonnet and OpenAI’s o1-mini.
- Optimized for consumer GPUs through quantization
- Open-sourced under Apache, revealing tokens and weights
huggingface.co/Qwen/QwQ-32B...

Qwen/QwQ-32B-Preview · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
December 5, 2024 at 12:30 AM
Alibaba’s QwQ-32B
It excites with strong math, coding, and reasoning scores, ranking between Claude 3.5 Sonnet and OpenAI’s o1-mini.
- Optimized for consumer GPUs through quantization
- Open-sourced under Apache, revealing tokens and weights
huggingface.co/Qwen/QwQ-32B...
It excites with strong math, coding, and reasoning scores, ranking between Claude 3.5 Sonnet and OpenAI’s o1-mini.
- Optimized for consumer GPUs through quantization
- Open-sourced under Apache, revealing tokens and weights
huggingface.co/Qwen/QwQ-32B...
Like/repost the 1st post to support our work 🤍
Also, elevate your AI game with our free newsletter ↓
www.turingpost.com/subscribe
Also, elevate your AI game with our free newsletter ↓
www.turingpost.com/subscribe
Turing Post
Saves you a lot of research time, plus gives a flashback to ML history and insights into the future. Stay ahead alongside over 73,000 professionals from top AI labs, ML startups, and enterprises
www.turingpost.com
December 2, 2024 at 11:15 PM
Like/repost the 1st post to support our work 🤍
Also, elevate your AI game with our free newsletter ↓
www.turingpost.com/subscribe
Also, elevate your AI game with our free newsletter ↓
www.turingpost.com/subscribe
Find a complete list of the latest research papers in our free weekly digest: www.turingpost.com/p/fod78
🌁#78: Enabling the Future of AI (2025)
join the prediction game plus our usual collection of interesting articles, relevant news, and research papers. Dive in!
www.turingpost.com
December 2, 2024 at 11:15 PM
Find a complete list of the latest research papers in our free weekly digest: www.turingpost.com/p/fod78
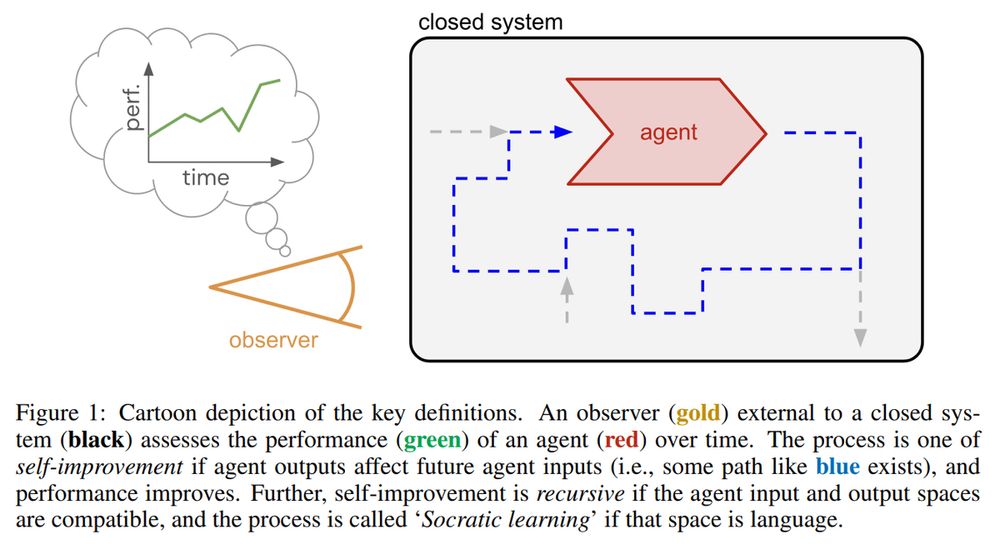
Boundless Socratic Learning with Language Games, Google DeepMind
This framework leverages recursive language-based "games" for self-improvement, focusing of feedback, coverage, and scalability. It suggests a roadmap for scalable AI via autonomous data gen and feedback loops
arxiv.org/abs/2411.16905
This framework leverages recursive language-based "games" for self-improvement, focusing of feedback, coverage, and scalability. It suggests a roadmap for scalable AI via autonomous data gen and feedback loops
arxiv.org/abs/2411.16905
December 2, 2024 at 11:15 PM
Boundless Socratic Learning with Language Games, Google DeepMind
This framework leverages recursive language-based "games" for self-improvement, focusing of feedback, coverage, and scalability. It suggests a roadmap for scalable AI via autonomous data gen and feedback loops
arxiv.org/abs/2411.16905
This framework leverages recursive language-based "games" for self-improvement, focusing of feedback, coverage, and scalability. It suggests a roadmap for scalable AI via autonomous data gen and feedback loops
arxiv.org/abs/2411.16905